
1.Google Research:2020年の振り返りと2021年以降に向けて(2/5)まとめ
・機械学習の応用は脳の構造解析から有望な分子化合物の探索、チップセットの設計など多岐に
・責任あるAIは解釈可能性の向上やバイアスの削減、安全性の向上など引き続き活発
・自然言語理解はTransfomerの改良によりモデル規模の拡大と性能の向上が著しい
2.機械学習の応用、責任あるAI、言語理解、機械翻訳
以下、ai.googleblog.comより「Google Research: Looking Back at 2020, and Forward to 2021」の意訳です。元記事の投稿は2021年1月12日、Jeff Deanによる投稿です。
去年まではai.googleblog.comに前年に投稿された話題の振り返り的な投稿が大半を占めていたのですが、今年はai.googleblog.comの投稿にはなかった進展についても多く触れられているため、超長文です。
中でも「コンセプトボトルネックモデル(Concept bottleneck models)」は、専門家の持つ専門知識を特定のレイヤーに一致するようにモデルをトレーニングすることにより、モデルの解釈可能性を向上するアイディアとの事で、え、そんな事がもう出来るようになってたの!と衝撃を受けました。
アイキャッチ画像のクレジットはPhoto by Roberto Nickson on Unsplash
(5)機械学習のその他の分野への応用
機械学習は、私達が科学の多くの分野で進歩を遂げるのを助ける不可欠な技術であることが証明され続けています。2020年、HHMI Janelia Research CampusのFlyEMチームと共同で、ショウジョウバエの脳構造が把握できる半脳コネクトームをリリースしました。
これは、脳組織の高分解能電子顕微鏡画像に適用可能な大規模な機械学習モデルを使用して再構築された、脳の接続性を把握可能な大規模なシナプス解像度マップです。
このコネクトーム情報は、神経科学者が様々な照合をするのに役立ち、脳がどのように機能するかを私たち全員がよりよく理解するのに役立ちます。
非常にfly(訳注:flyには俗語として「格好いい、イカス」の意味もあるので「蝿」とかけている。とても訳しにくいJeff Deanのおやぢギャグ)で操作可能な三次元UIを必ずチェックしてください!
システム生物学の問題へのMLの適用も増加しています。 Google Accelerated Scienceチームは、Calicoの同僚と協力して、酵母に機械学習を適用し、システム全体で遺伝子がどのように連携するかをより深く理解しています。
また、モデルベースの強化学習を使用して、医療または産業用途に望ましい特性を持つDNAやタンパク質などの生物学的配列を設計する方法も模索しています。モデルベースのRLは、サンプルの効率を向上させるために使用されます。
実験の各ラウンドで、ポリシーは、前のラウンドからの機能測定に適合するシミュレーターを使用してオフラインでトレーニングされます。 DNA転写因子結合部位の設計、抗菌タンパク質の設計、タンパク質構造に基づくイジングモデルのエネルギーの最適化などのさまざまなタスクで、モデルベースのRLが既存の方法の魅力的な代替手段であることがわかります。
X-Chem PharmaceuticalsおよびZebiAIと提携して、有望な分子化合物の「仮想スクリーニング」を計算で行うためのML技術も開発しています。
この分野での従来の研究は、関連する化合物の比較的小さなセットに焦点を当てる傾向がありました。しかし、本研究では、化学空間の広い範囲にわたって「ヒット」を見つけられるように一般化するために、DNAでエンコードされた小分子ライブラリを使用しようとしています。これは、時間のかかる物理ベースの研究作業の必要性を減らし、アイデアから医薬品の実用化に進む道のりを楽にします。
また、機械学習をコアコンピュータサイエンスやコンピュータシステムの問題に適用することに成功しました。この傾向は、MLSys(Machine Learning and Systems)のようなまったく新しいカンファレンスを生み出しています。
論文「Learning-based Memory Allocation for C++ Server Workloads」では、ニューラルネットワークベースの言語モデルが、「メモリ割当毎の実行状況に依存するサイトオブジェクトの有効期間」を予測し、これを使用してヒープを整理し、断片化を減らしました。
巨大なページのみを使用しながら、断片化を最大78%削減できます。TLB(Translation Lookaside Buffer、メモリ管理ユニット内のキャッシュ)の動作に適しています。
「End-to-End, Transferable Deep RL for Graph Optimization」では、TensorFlowのデフォルトの最適化と比較して、3つのグラフ最適化タスクで33%~60%のスピードアップを示す、計算グラフ最適化のためのエンドツーエンドの転移可能な深層強化学習方法について説明しました。以前の計算グラフ最適化手法よりも15倍高速な収束を実現します。

GOの概要
グラフembeddingとシーケンシャルattentionを組み合わせたエンドツーエンドのグラフポリシーネットワーク
「Chip Design with Deep Reinforcement Learning」で説明したように、コンピュータチップ設計の配置配線の問題にも強化学習を適用しています。これは通常、非常に時間と労力を要するプロセスであり、チップのアイデアから実際に完全に設計および製造されたチップを作成するまでに非常に長い時間がかかる主な理由です。
従来の手法とは異なり、私達のアプローチには、過去の経験から学び、時間をかけて改善する能力があります。特に、より多くのチップブロックをトレーニングするにつれて、これまでに見られなかったチップブロックの最適化配置を迅速に生成するように改善されます。このシステムは、通常、人間のチップ設計の専門家よりも優れた配置を生成できます。このシステム(TPUを使って実行)を使用して、次世代のTPUの大部分の配置とレイアウト設計を行います。
Mengerは、大規模な分散強化学習のために構築した最近のインフラストラクチャであり、チップ設計などの難しいRLタスクに有望なパフォーマンスをもたらします。
オープンソースのRISC-VプロセッサであるArianeのマクロ配置のトレーニングの進行に伴う変化
左側では、ポリシーがゼロからトレーニングされており、右側では、事前にトレーニングされたポリシーがこのチップ用に微調整されています。各長方形は、個々のマクロ配置を表します。ゼロから学習したポリシーが設計した中央の空白部分が、事前にトレーニングされたポリシーによる配置では最初から存在していることに注目してください。
(6)責任あるAI(Responsible AI)
Google AI原則は、高度なテクノロジーの開発の指針となります。 私たちは引き続き責任あるAIの研究とツールに投資し、この分野で推奨される技術的手法と実装の進捗状況について、ブログ投稿やレポートを含む定期的な更新を行い共有します。
言語モデルの動作をよりよく理解するために、言語モデルの解釈可能性を向上させるツールキットである言語解釈可能性ツール(LIT:Language Interpretability Tool)を開発し、言語モデルの決定をインタラクティブに調査および分析できるようにしました。
事前にトレーニングされた言語モデルで性別の相関関係を測定するための手法と、Google翻訳で性別の偏りを減らすための規模拡大可能な手法を開発しました。カーネルトリックを使用して、個々の予測に対するトレーニングデータ内の事例の影響を推定する簡単な方法を提案しました。
非専門家が機械学習の結果を解釈できるように、2019年に紹介されたTCAV手法を拡張して、完全で十分な概念のセットを提供するようになりました。
オリジナルのTCAVの研究では、「毛皮」と「長い耳」が「ウサギ」の予測にとって重要な概念であると言えます。この作業により、これら2つの概念は予測を完全に説明するのに十分であるとも言えます。他の概念は必要ありません。
コンセプトボトルネックモデル(Concept bottleneck models)は、レイヤーの1つが事前定義された専門家の持つ概念(例えば、「骨がささくれだっている」または「翼の色」)と一致するようにモデルをトレーニングすることにより、モデルをより解釈しやすくするための手法です。
タスクの最終予測を行う前に、これらの概念をその場で解釈するだけでなく、オン/オフにすることもできます。
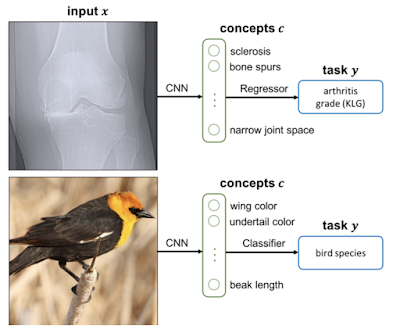
Concept Bottleneck Modelsで説明されているように、予測を事前に特定された概念に合わせると、モデルがより解釈しやすくなります。
他の多くの機関と協力して、言語モデルの記憶効果も調査し、トレーニングデータ抽出攻撃が最先端の大規模言語モデルに対する現実的な脅威であることを示しました。この発見と、embeddingモデルが情報を漏らす可能性があるという結果は、プライバシーに重大な影響を与える可能性があります。(特に個人データでトレーニングされたモデルの場合)
論文「Thieves of Sesame Street: Model Extraction on BERT-based APIs」では、言語モデルへのAPIアクセスのみを持つ攻撃者が、元のモデルと非常に高い相関関係を持つモデルを作成できることを示しました。元のモデルへのAPIアクセスが比較的少ない場合でも非常に高い相関を持つ出力が可能です。その後の後続研究により、攻撃者は任意の精度でより小さなモデルを抽出できることが実証されました。
適応的攻撃を使用して評価しても、敵対的サンプルに対する13の公開された防御法を回避できることをAIの安全原則に基づいて示しました。私達の仕事は、適応的攻撃を実行するために必要な方法論とアプローチのレイアウトに焦点を当てているため、コミュニティはより堅牢なモデルの構築をさらに進めることができます。
機械学習システム自体を調べる方法を調べることも、重要な調査領域です。Partnership on AIと協力して、航空宇宙、医療機器、金融業界からの教訓とそのベストプラクティスを利用して、ソフトウェア製品設定での機械学習の使用を監査する方法のフレームワークを定義しました。
トロント大学とMITとの共同作業で、顔認識システムのパフォーマンスを監査するときに発生する可能性のあるいくつかの倫理的懸念を特定しました。
ワシントン大学との共同作業で、アルゴリズムの公平性を評価するためのサブセットを選択する際の多様性と包含に関連するいくつかの重要な考慮事項を特定しました。
およそ10億人のユーザーのために責任あるAIを機能させる最初のステップとして、そして公平性の概念が世界のさまざまな地域で一貫しているかどうかを理解するために、インドのアルゴリズムの公平性に関するフレームワークを分析および作成しました。この際はデータセット、公平性の最適化、インフラストラクチャ、エコシステムを考慮しました。
2019年にトロント大学と共同で導入されたモデルカードは、影響力を増しています。実際、OpenAIのGPT-2やGPT-3などの多くの有名なモデル、GoogleのMediaPipeモデルの多く、さまざまなGoogle Cloud APIはすべて、機械学習モデルのユーザーにモデルの開発に関する詳細情報、様々な条件下で観察されたモデルの動作を提供する方法としてモデルカードを採用しています。
他の人が自分の機械学習モデルにこれを簡単に採用できるようにするために、モデルの透明性レポートを簡単にするModel CardToolkitも紹介しました。ML開発プラクティスの透明性を高めるために、データ要件の仕様やデータ受け入れテストなど、データセット開発ライフサイクル全体にわたるさまざまなベストプラクティスの適用可能性を示します。
米国国立科学財団(NSF:National Science Foundation)と協力して、人間とAIの相互作用とコラボレーションのための国立AI研究所を発表し、資金提供を支援しました。
また、TF Model Remediationライブラリで利用可能な新しい正則化手法であるMinDiffフレームワークをリリースしました。これは、MLモデルをトレーニングする際の不公平なバイアスを効果的かつ効率的に軽減するためのものです。簡単なシミュレーションを構築するためのML-fairnessジムもあります。ML-fairnessジムは社会環境に機械学習ベースの意思決定システムを導入することの潜在的な長期的影響を調査できます。
公平性のためのフレームワークの開発に加えて、強化学習を使用してより安全な軌道を導入するなど、推薦システムのユーザ体験の健全性と品質を特定および改善するためのアプローチを開発しました。また、機械学習システムの信頼性の向上にも引き続き取り組んでおり、敵対的な事例を生成するなどのアプローチによって堅牢性が向上し、堅牢性アプローチによって公平性が向上することがわかりました。
差分プライバシー(Differential privacy)は、プライバシー保護を正式に定量化する手法であり、特定の個人に関する情報を漏らさないように動作するために、非常に基本的なアルゴリズムも再考する必要があります。特に、差分プライバシーは、前述の種類の記憶効果と情報漏えいに対処するのに役立ちます。
2020年には、private empirical riskを最小化するより効率的な方法から、厳密な近似保証とプライベートスケッチアルゴリズムを備えたプライベートクラスタリング手法まで、多くの刺激的な開発がありました。
また、内部ツールの中核にある差分プライバシーライブラリをオープンソース化しました。実数の浮動小数点表現によって引き起こされる漏洩から保護するために特別な注意を払っています。これらは、研究者や政策立案者にとって匿名データの貴重な情報源である差分プライベートCOVID-19モビリティレポートを作成するために使用するものとまったく同じツールです。
開発者が分類モデルのプライバシー属性を評価できるように、TensorflowでMLプライバシーテストライブラリをリリースしました。このライブラリが、世界中の機械学習開発者が使用できる堅牢なプライバシーテスト群の出発点になることを願っています。
プライベートアルゴリズムの開発において最先端技術を推進することに加えて、私はプライバシーを製品の構造に織り込むことで私たちが行った進歩に興奮しています。最良の例の1つは、ChromeのPrivacy Sandboxです。これは、広告エコシステムの基盤を変更し、個人のプライバシーを体系的に保護するのに役立ちます。プロジェクトの一環として、関心に基づくターゲティングのための集団連合学習(FLoC:Federated Learning of Cohorts)や、差分プライバシー測定のための集約APIなど、さまざまなAPIを提案して評価しました。
2017年に発表されたfederated learningは、それ自体が完全な研究分野であり、2020年だけでもfederated learningに関する3000を超える出版物が掲載されています。2019年に発行された私たちの組織横断的な進歩と連合学習の未解決の問題に関する調査論文は過去1年間で367回引用されており、更新版はまもなく機械学習のFoundations & Trendsシリーズで公開されます。7月に、federated learningと分析に関するワークショップを開催し、すべての研究発表とTensorFlowフェデレーションチュートリアルをyoutubeで公開しました。
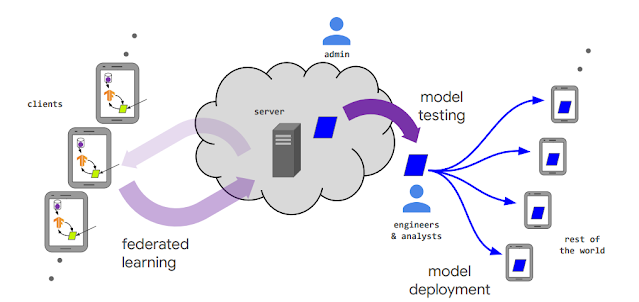
federated learningでトレーニングされたモデルとフェデレーション学習システムのさまざまな登場人物のライフサイクル
私たちは、新しいフェデレーション最適化アルゴリズムの開発を含め、federated learningの最先端を推進し続けています。これには、アダプティブラーニングアルゴリズム(adaptive learning algorithms)、事後平均化アルゴリズム(posterior averaging algorithms)、フェデレーション設定で集中型アルゴリズムを模倣する手法、補完的な暗号化プロトコルの大幅な改善などが含まれます。
フェデレーション分析を発表し、個人が特定できない状態でユーザーのスマートフォン内に保存されている生データをデータサイエンスが分析する事を可能にしました。Google製品でのfederated learningの新しい用途には、Gboardで入力状況に合わせた絵文字の提案、Google Health Studiesによるプライバシー保護医学研究の開拓が含まれます。更に、neuripsで発表した「Privacy Amplification via Random Check-Ins」では、federated learningの最初のプライバシーアカウンティングメカニズムを紹介しました。
ユーザーの安全も私たちにとって非常に興味深い分野です。 2020年には、悪意のあるドキュメントに対する保護を提供する新しいMLベースのドキュメントスキャナーを導入することで、Gmailユーザーの保護を継続的に改善しました。これにより、悪意のあるオフィスドキュメントの検出が毎日10%増加しました。一般化機能のおかげで、このツールは、他の検出メカニズムを回避し、場合によっては検出率を150%向上させ、いくつかの敵対的なマルウェアをブロックするのに非常に効果的です。
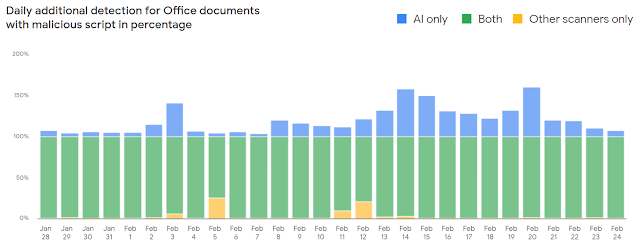
アカウント保護の面では、完全にオープンソースのセキュリティキーファームウェアをリリースして、アカウントをフィッシングから保護するための最良の方法としてセキュリティキーに焦点を合わせながら、2要素認証の分野で最先端を行くのに役立てています。
(7)自然言語の理解
言語の理解を深めることは、2020年にかなりの進歩が見られた分野です。Googleや他でおこなわれている自然言語分野での研究の多くは現在Transformerに依存しています。Transformerは元々言語に関する問題を解決するために開発された特定のスタイルのニューラルネット ワークモデルですが、近年、画像、動画、音声、タンパク質の折り畳み、およびその他の様々な研究領域でも有用であるという証拠が増えています。
楽しみな研究領域の1つは、関心のある事柄についてユーザーと雑談できるチャットできる対話システムです。多くの場合、このような対話には複数回のやりとりが含まれます。
従来のこの分野での成功した研究には、特定の話題(Duplexの店舗予約など)に特化したシステムの作成が多く含まれていましたが、これらのシステムでは一般的な会話を続けることができません。
より自由な対話が可能なシステムを作成するという普遍的な研究目標を追求するために、2020年に、どんな話題も熱心にチャットできる学習済みの会話エージェントであるMeenaについて紹介しました。
Meenaは、回答の適切度と具体度の両方を測定するSSAと呼ばれる対話システム測定基準で高スコアを達成します。Meenaのモデルサイズを拡大すると、より低いパープレキシティ(perplexity、候補となる単語を絞り込む性能)を実現でき、論文に示されているように、より低いパープレキシティはSSAの改善と非常に密接に関連していることがわかりました。
Meena(左)と人間(右)のチャット
生成言語モデルや対話システムに関するよく知られた問題の1つは、事実データ(訳注:factual data、理論や個人的な解釈ではなく、事実に関係している、または事実を含んだデータ。ローン申請時に参照される与信情報など)について話し合う時に、モデルの容量が話題に関するすべての特定の詳細を記憶するのに十分な大きさを持っていない可能性があることです。
そのため、モデルはもっともらしいが具体的でなく正しくない言葉を生成する事があります。(これはAIに固有のものではありません。人間もこれらのエラーを行う事ができます。)
対話システムでこれに対処するために、外部情報ソース(例:大規模な文書資料または検索エンジンAPI)へのアクセスを許可することにより、会話型エージェントを拡張する手法を模索しています。また、検索された文と一致する用語を生成するために、外部情報ソースを追加のリソースとして使用するための学習手法も開発しています。
この分野での研究には、検索を言語特徴表現モデルに統合することが含まれます。これがうまく機能するための重要な基盤技術は、効率的なベクトル類似性検索であるScaNNのような技術であり、目的の情報をテキスト資料内の情報に効率的に一致させる事が必要になります。
適切なコンテンツが見つかったら、ニューラルネットワークを使用してテーブル内の回答を見つけたり、定型書式から構造化データを抽出するアプローチなどで理解を深めることができます。テキスト要約の最先端モデルであるPEGASUSに関する私達の研究は、会話、検索システム、およびその他の多くの場所で役立つ一般的な手法である、任意のテキストの自動要約を作成するためにも役立ちます。
NLPモデルの効率も、2020年の私たちの仕事の重要な焦点となっています。転移学習やマルチタスク学習などの手法は、一般的なNLPモデルを適度な計算量で新しいタスクに使用できるようにするのに劇的に役立ちます。
これに関する作業には、T5を使った転移学習の探索、モデルの疎な活性化(sparse activation、後述のGShardの作業のように)、およびELECTRAを使用したより効率的なモデルの事前トレーニングが含まれます。
その他の作業としては基本的なTransformerアーキテクチャの改善も目指しています。
Reformer:はるかに大きなattention windowsをより効率的にサポートするために局所性鋭敏型ハッシュと可逆計算を使用
Performers:二次関数的ではなく線形にスケーリングするattentionのためのアプローチ(タンパク質モデリングの事例で解説しています)
ETCとBigBird:大域的で疎なランダム接続を利用して、より大きく構造化されたシーケンスデータを線形に規模拡大する事を可能に。
また、よりBERTのラージモデルと比較して100分の1の非常に軽量なNLPモデルを作成する手法についても検討しました。モデルのサイズは小さくとも、一部のタスクでもほぼ同等の性能を発揮できるため、スマートフォンなどに搭載するオンデバイスのNLPとして非常に適しています。
論文「Encode, Tag and Realize」では、完全に汎用的なテキスト生成ではなく編集操作を使用する生成テキストモデルの新しいアプローチも検討しました。これは、生成の計算要件、生成されたテキストの制御の強化、および必要なトレーニングデータの削減に利点があります。
(8)機械翻訳
効果的な言語翻訳とは、異なる言語を話していても、私たち全員がコミュニケーションできるようにすることで、異なった世界を近づけるのに役立ちます。現在までに、世界中で10億人以上がGoogle翻訳を使用しており、昨年は5つの新しい言語(ルワンダ語、オリヤー語、タタール語、トルクメン語、ウイグル語、合計話者数は7500万人)のサポートを追加しました。
翻訳の品質は向上し続けており、2019年5月から2020年5月まで、100を超える言語で平均+ 5BLEUポイントの品質向上を示しています。
これは、改善されたモデルアーキテクチャやトレーニング、データセット、多言語転送、マルチタスク学習におけるノイズ処理の改良、低リソース言語(ネット上にその言語で書かれたコンテンツがあまりない言語)を改善するための単一言語データのより良い使用、機械学習システムの公平性の改善など、様々な手法を通じて、可能な限り多くの人々に利益を提供するという私たちの目標に直接一致しています。
多言語翻訳モデルの継続的な規模拡大により、特に世界中の数十億人の低リソース言語を話す人々に、さらなる品質の向上がもたらされると確信しています。
「GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding」ではGoogleの研究者は、最大6,000億個のパラメーターの疎に活性化された多言語翻訳モデルをトレーニングすると、100言語の翻訳品質が大幅に向上することを示しました。各言語毎に個別の4億パラメータを使用した単一言語モデルと比較してBLEUスコアが大きく改善したのです。
本研究では、以下に再掲した論文の図6に示されている、3つの傾向が際立っていました。(完全な説明については、元論文を参照してください)
・多言語トレーニングによるBLEUスコアの向上は、全ての言語で向上しますが、低リソース言語(グラフの右側。図の各長方形は10億の話者を示しているが左側よりも右側の方が横幅が広い)ではさらに高くなっています。
・モデルが大きくて深いほど、全ての言語でBLEUスコアの改善が大きくなりました。(線が交差することはほとんどありません)
・大きくて疎なモデルは、大きくて密なモデルよりもモデルトレーニング時の計算効率が約10倍から100倍向上しますが、精度は大きくて密なモデルのBLEUスコアと同等か大幅に上回ります。(計算効率については論文で説明しています)
図
「GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding」で説明されている、大規模で疎に活性化された言語モデルの100言語にわたる翻訳品質の大幅な向上の図。
私たちは、このGShardの調査作業で実証されたメリットをGoogle翻訳にもたらすことに積極的に取り組んでいます。また、ディベヒ語やアラビア語スーダン方言などの言語を含む1000の言語をカバーする単一モデルをトレーニングしています。(途中で解決する必要のあるいくつかの課題を共有しています)
また、BERTモデルの文の言語に依存しない特徴表現を作成する手法も開発しました。これは、より優れた翻訳モデルの開発に役立ちます。
更に翻訳品質をより効果的に評価するための新しい評価基準であるBLEURTを紹介しました。以下の表に示すように、BLEUのように使用されている単語の重複率を調査するだけでなく、生成された文の意味を考慮する新しい評価基準であるため、翻訳などの文章を生成するタスクをより正しく評価する事ができます。

3つの候補文のBLEUスコアの比較
候補2「Bud Powellは歴史的なピアニストでした」は、候補3「Bud Powellはニューヨーカーでした」より意味的に参照文「Bud Powellは伝説的なピアニストでした」に近いのですが、BLEUスコアは候補3よりも低くなります。
3.Google Research:2020年の振り返りと2021年以降に向けて(2/5)関連リンク
1)ai.googleblog.com
Google Research: Looking Back at 2020, and Forward to 2021
2)research.google
Publication database

CIFAR10のモデルに対するメンバーシップ推論攻撃。
x軸はモデルのテスト精度であり、y軸は脆弱性スコア(低いほど秘密が守られている事を意味します)です。精度はほぼ同じままであっても、脆弱性が増大します。より一般化することで、プライバシーの漏洩を防ぐことができます。