
1.定型書式から必要な情報を自動で抽出(1/2)まとめ
・領収書、請求書などの定型書式文書は、様々なビジネス場面において非常に一般的で大切
・しかしこれらの定型書式文書は手作業で処理されるが転記ミスなどが発生する可能性がある
・機械学習を用いてこれらの定型書式文書を自動処理させたいが自然言語と視覚処理が絡むため困難
2.構造化データとは?
以下、ai.googleblog.comより「Extracting Structured Data from Templatic Documents」の意訳です。元記事の投稿は2020年6月12日、Sandeep Tataさんによる投稿です。
表からデータを自動で抽出するTAPASを以前紹介しましたが、今回は表形式だけでなく請求書などの一般的な定型文書からデータを自動抽出するお話です。
アイキャッチ画像は定型書式の一種である乗車券、しかしハリーポッターに出て来る魔法学校行きの乗車券で乗り場がPLATFORM 9 3/4、つまり9番線乗り場と10番線乗り場の間に存在する秘密の乗車ホームから発車するので、今回のAIで「プラットフォーム番号は整数」とスキーマ定義していると認識できません。クレジットはPhoto by Serafima Lazarenko on Unsplash
2022年4月追記)後続研究にFormNetが発表されました
領収書、請求書、保険の見積もりなどの定型書式文書は、様々なビジネス場面において非常に一般的で大切です。現在、これらの文書の処理は主に手作業で行われており、既存の自動化システムは、脆弱でエラーが発生しやすい経験則的な実装に基づいています。
何千もの異なるデザインでレイアウトできる請求書のような文書について考えてみましょう。
異なる会社、または同じ会社内の異なる部署からの請求書でも、書式が少し異なる場合があります。ただし、請求書番号、請求日、請求金額、支払期日、および請求対象の商品リストなど、請求書に含まれるべき情報には共通の項目があります。
こういった必要な項目と項目間の関連性が明確なデータ、すなわちデータ構造が明確なデータを構造化データ(Structured Data)と言います。
構造化データを自動的に抽出するシステムがあれば、エラーが発生しやすい手作業を回避できるため、多くの業務フローの効率を劇的に向上させる可能性があります。
ACL 2020に受理された論文「Representation Learning for Information Extraction from Form-like Documents」では、定型書式文書から構造化データを自動的に抽出する方法を紹介します。
平文からデータを抽出する従来の研究とは対照的に、抽出候補となる項目を識別するために項目のタイプに関する知識を使用するアプローチを提案します。
次に、近隣の単語から各候補の密な特徴表現を学習するニューラルネットワークを使用して、これらをスコア付けします。様々な請求書と様々な領収書を対象とした実験により、学習データ内に含まれていなかったレイアウトであっても対応可能な一般化ができていることが示されました。
なぜ定型書式からデータを抽出する事は難しいのでしょうか?
この情報抽出の問題は、自然言語処理(NLP)とコンピュータービジョンの2つの分野にまたがっているために困難になります。
従来のNLPタスクとは異なり、このような定型文書には、通常の文や段落に見られるような「自然言語」は含まれず、申し込みフォームに似ています。
多くの場合、データは表形式で表示されますが、ほとんどの文書で複数のページが存在し、多くの場合、段落の数は異なり、情報を整理するための様々なレイアウトやフォーマットに手がかりがあります。このような文書を理解するためには、ページ上の文章の配置形状を理解することが重要です。しかし、その一方、これらの文書を純粋に画像内の文章の範囲を特定する「セグメンテーション問題」として扱うと、データ抽出の際に「文字が持っている意味」を情報として活用することが難しくなります。
解決策の概要
この問題に対する私達のアプローチでは、開発者は2つの入力を使用して、特定文書(請求書など)から情報を抽出するシステムを学習および展開する事ができます。
2つの入力とは「ターゲットスキーマ(つまり、抽出する項目とその項目のタイプを定義したリスト)」、および「トレーニングセットとして使用するために正確なラベルが付けられたドキュメントの小さな集合」です。
サポートしている項目タイプには、日付、整数、英数字で構成されるコード、通貨額、電話番号、URLなどの基本的データが含まれます。 また、住所、会社名など、Googleナレッジグラフ(Google検索した時に右上の方に出て来る時があるパネル)が通常検出する概念を利用します。
入力ドキュメントは、最初に光学式文字認識(OCR:Optical Character Recognition)サービスであるCloud Vision APIを利用してテキストやレイアウト情報を抽出します。これにより、PDFなどのデジタルドキュメントや画像(スキャンされた文書など)を扱う事ができます。
次に、OCRが出力した文章から、抽出対象項目かもしれない部分を識別する候補生成プログラムを実行します。
候補生成プログラムは、各項目タイプ(日付、番号、電話番号など)に関連付けられた既存のライブラリを利用します。これにより、候補毎に新しいプログラムを記述する必要がなくなります。
これらの各候補は、学習済みニューラルネットワーク(以下で説明する「スコアラー(scorer)」)を使用してスコア付けされ、実際にその項目が抽出対象である可能性を推定します。
最後に、割り当てモジュールが、スコアリングされた候補を目標の項目と照合します。
デフォルトでは、割り当てモジュールは項目毎に最も高いスコアを持つ候補を選択するだけですが、「請求日の項目は支払い日の項目より前の日付でなければならない」などの、追加の固有制約を組み込むことができます。
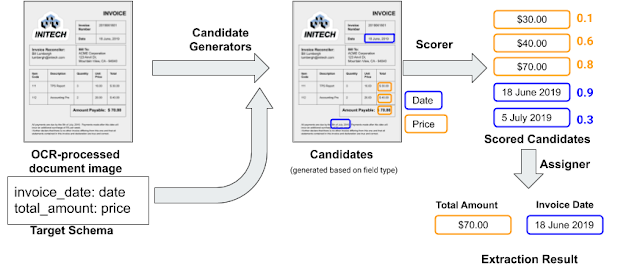
抽出システムの処理概要
請求書と2つの項目を持つシンプルなターゲットスキーマを使用した例です。
青い四角は、請求日(invoice_date)項目の候補と、請求総額(amount_due)項目の候補を示しています。
スコアラー(scorer)
スコアラーは、バイナリ分類器としてトレーニングされるニューラルモデルです。入力として、スキーマから対象項目と抽出候補を受け取り、0~1の予測スコアを生成します。
候補のラベルは、候補がその文章と項目の検証済みラベルと一致するかどうかによって決まります。
モデルは、項目と候補をベクトル空間に展開し、それらの特徴表現を学習します。ベクトル空間内で項目に最も近い候補が、その項目の正しい抽出値である可能性が最も高くなります。
候補の特徴表現
候補は、「その近くに存在するトークン(単語や記号、数字など)」と「トークンの相対位置」と共に特徴表現を構成します。相対位置は「候補として識別された境界ボックスの重心」に対するトークンの位置です。
例として請求日(invoice_date)項目を考えてみましょう。
「Invoice Date」や「Inv Date」などの単語が近くに存在すると、これが候補である可能性が高い事をスコアラーにヒントとして示す可能性があります。しかし、「Delivery Date」のような単語は、これがおそらくinvoice_dateではないことを示します。
小さなトレーニングデータセットに偶然存在する値に過剰適合してしまう事を避けるために、「候補の値」はその特徴表現に含めません。例えば、学習データ内にその年の請求書のみが含まれている場合、請求年は必ず「2019」になってしまうためです。

請求書の一部
緑の四角は、invoice_date項目の候補を示し、赤い四角は、近くのトークンであり、相対位置を表す矢印がついています。「number」、「date」、「page」、「of」、および他の「invoice」も候補の近くのトークンです。
3.定型書式から必要な情報を自動で抽出(1/2)関連リンク
1)ai.googleblog.com
Extracting Structured Data from Templatic Documents
2)research.google
Representation Learning for Information Extraction from Form-like Documents

