
1.Cloud TPU v3 PodsがAI学習にかかる時間を競うコンペで最速記録を達成まとめ
・Cloud TPU v3 Podsが機械学習モデルの学習時間を測るベンチマークであるMLPerfで最速記録を達成
・オンプレミスが主体のNVIDIAのシステムに対してクラウド利用可能なGCP上のサービスとして実現
・Cloud TPU v3 Podsはベータ利用が可能になっており必要なチップ数を16~1024間で選択して利用可能
2.Cloud TPU v3 Podsとは?
以下、cloud.google.comより「Cloud TPU Pods break AI training records」の意訳です。元記事の投稿は2019年7月11日、Zak Stoneさんによる投稿です。三カ月前なので少し古いですが、11月4日時点でまだ最速記録は破られていないようです。
TPU v3 podsが既にベータ利用可能になっていた事に気付いてませんでした。クラウドの世界ではAmazonやMicrosoftに相当な遅れをとっているGoogleですが、今回のコンペの主要競争相手はNVIDIAで少しだけIntel、Alibabaの名前が載っている状況、つまりはハードウェアベンダーとしての対決です。
現在のようにシステムの中にAIを取り込むのではなく、AIありきでシステム設計が行われるようになっていくとしたらGCPが一気にシェアを獲得するのでしょうか。それとも学習済みモデルを動かすだけならばニューラル特化型ハードの必要性は高くはないので、AzureやAWSがシェアを維持するのでしょうか。
ちなみにAmazonもAWS Inferentiaという機械学習用の専用ハードウェアを開発中と2018年11月に発表しており、その際は2019年中に利用可能になるとの話でしたが2019年11月3日現在でまだ続報がないようで、今回のMLPrefベンチにもAmazonの名前は載っていません。
Google CloudのAIに最適化されたインフラストラクチャにより、企業は最先端の機械学習(ML)モデルをより速く、より大規模に、より低コストでトレーニングする事ができます。これらの利点により、Google Cloud Platform(GCP)は、MLパフォーマンスを測定するための業界標準であるMLPerfベンチマークのコンペティションの最新ラウンドで3つの新しいパフォーマンスレコードを達成する事ができました。
3つの記録全て、Googleが機械学習専用に構築した最新世代のスーパーコンピューターであるCloud TPU v3 Podsで達成されました。これらの結果は、 Cloud TPU Podsのスピードを示しています。各記録の実行時間は2分未満でした。
AIに最適化されたインフラストラクチャ
これらの最新のMLPerfベンチマーク結果の意味する事は、Google Cloudは、トランスフォーマー(Transformer)、Single Shot Detector(SSD)、およびResNet-50などの大規模な業界標準のMLトレーニングワークロードを実行したときに、社内システム(オンプレミスシステム)を凌駕する最初の広く一般利用可能なクラウドシステムです。TransformerおよびSSDカテゴリでは、Cloud TPU v3 Podsは、MLPerf Closed Divisionの最速のオンプレミスシステムよりも84%以上高速にモデルをトレーニングしました。
・Transformerモデルアーキテクチャは、現代の自然言語処理(NLP)の中核です。たとえば、Transformer は、機械翻訳、言語モデリング、および高品質のテキスト生成の大幅な改善を可能にしました。(訳注:BERTのTはTransformerのT)
・SSDモデルアーキテクチャは、物体検出に広く使用されています。これは、医療画像処理、自動運転、写真編集などのコンピュータービジョンアプリケーションの重要な部分です。
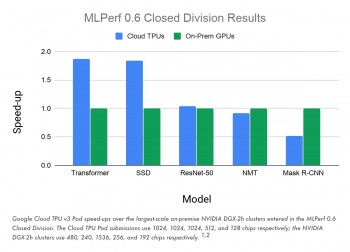
Cloud TPUを用いて速度を向上できるMLワークロードの幅広さを示すために、NMTおよびMask R-CNNカテゴリの結果も提出しました。NMTモデルはニューラル機械翻訳のより伝統的なアプローチで使われる事が多く、Mask R-CNNは画像セグメンテーションモデルで使われます。
スケーラビリティー
GCPは、様々な規模のAI開発に対して適切なパフォーマンスと価格を提供する柔軟性を備えています。
クラウドTPUユーザーは必要に応じて、「スライスサイズ」と呼ばれる単位で最適なクラウドTPUポッド構成を選択する事ができます。スライスサイズはMLPerfベンチマークでも使用されています。
Cloud TPU v3 Podのスライスには、16、64、128、256、512、または1024チップを含める事ができ、Cloud TPUチュートリアルで取り上げられているオープンソースのリファレンスモデルのいくつかは、最小限のコードを変更するだけでこれらすべてのスライスサイズで実行する事ができます。

今日から始めましょう
クラウドTPUポッドの規模とパフォーマンスのメリットは、Cloud TPUの既存顧客にも影響を拡大しています。たとえば、Recursion Pharmaceuticals社は、自社のGPUベースのシステムでは24時間かかる学習を、Cloud TPU Podsを使ってわずか15分でトレーニングできるようになりました。
最先端の深層学習を開発する事が御社にとってビジネス上重要であるならば、Google Cloud営業担当者に連絡して、Cloud TPU Podsへのアクセスをリクエストしてください。Google Cloudのお客様は、自社システムを構築するために数か月の時間をかける事なく、数日待てばCloud TPU Podsを試す事ができます。Cloud TPU Podsスライスの1年間および3年間の使用権を予約すると割引が適用され、開発コストの1ドルあたりのパフォーマンスがさらに向上します。
これは始まりです
私達は、最新のGPU、クラウドTPU、高度なAIソリューションを含むAIプラットフォームを、機械学習ワークロードを実行するのに最適な場所にすることを約束します。
Cloud TPUのパフォーマンス、スケール、および柔軟性は引き続き成長し、サポートされるクラウドTPUワークロードの幅を広げ続けます。(TPUのソースコードはgithubで利用可能です)
Cloud TPUの詳細については、Cloud TPUのホームページとドキュメントをご覧ください。またブラウザでCloud TPUを無料で試すこともできます。(Colabを使ったインタラクティブなデモページがあります。そこでは貴方が選択した画像に、トレーニング済みのMask R-CNN画像セグメンテーションモデルを適用する事ができます。)
Cloud TPUのベータ利用が可能になった事をアナウンスしたページ「Google’s scalable supercomputers for machine learning, Cloud TPU Pods, are now publicly available in beta」の下部よりCloud TPUを利用したColabのデモとチュートリアルへのリンクを更に見つけることができます。
3.Cloud TPU v3 PodsがAI学習にかかる時間を競うコンペで最速記録を達成関連リンク
1)cloud.google.com
Cloud TPU Pods break AI training records
Google’s scalable supercomputers for machine learning, Cloud TPU Pods, are now publicly available in beta
2)mlperf.org
MLPerf Training v0.6 Results
3)github.com
tensorflow/tpu
