
1.Menger:大規模な分散型強化学習(1/3)まとめ
・RLとはデータ収集とトレーニングのループだが規模拡大すると反復処理が追いつかなくなる
・Mengerは大規模な分散RLインフラであり複数クラスタにより規模拡大が可能
・TPUを使用して反復処理を高速化し比較対象よりトレーニング時間を最大8.6倍短縮
2.Mengerとは?
以下、ai.googleblog.comより「Massively Large-Scale Distributed Reinforcement Learning with Menger」の意訳です。元記事の投稿は2020年10月2日、Amir YazdanbakhshさんとJunchaeo Chenさんによる投稿です。
Mengerはグラフ理論のメンガーの定理で有名な数学者であるKarl Mengerから取っているそうです。お父さんのCarl Mengerも国民経済学原理の出版で有名な経済学者なのでカール・メンガーで検索するとお父さんの方の業績が結構出てきるので混乱しないように注意です。
アイキャッチ画像は息子の業績である「メンガーのスポンジ(Menger sponge)」です。フラクタル曲線、つまり規模を拡大しても一定のパターンが無限に繰り返される2次元画像は皆さん見た事があると思うのですが、フラクタル曲線の三次元版がメンガーのスポンジであって、今回提案されたMengerは事実上無限に規模を拡大出来ると言う事からあやかって命名されたそうです。
クレジットはwikipediaよりNiabot
過去10年間で、強化学習(RL:Reinforcement Learning)は機械学習で最も有望な研究分野の1つになり、チップ配置の設計やリソース管理などの高度な現実世界の問題を解決し、碁、Dota2、そしてhide-and-seekなどの挑戦的なゲームを解決する大きな可能性を示してきました。
一言で言えば、RLのインフラとは、データ収集とトレーニングのループです。行為者(actor)は環境を探索してサンプルデータを収集し、それを学習者(learner)に送信してモデルをトレーニングおよび更新します。
現在のほとんどのRL手法では、ターゲットタスクを学習するために、環境から数百万のサンプルのバッチに対して多くの反復が必要です(たとえば、Dota 2は2秒毎に200万フレームのバッチから学習しています)。
そのため、RLのインフラは、効率的に規模を拡大し(例えば、行為者の数を増やす)、膨大な数のサンプルデータを収集するだけでなく、トレーニング中にこれらの大量のサンプルデータを迅速に反復処理できる必要があります。
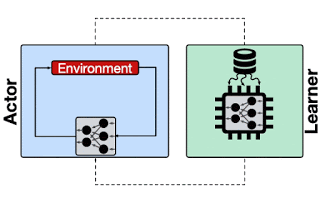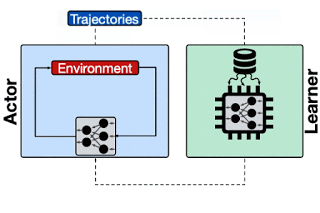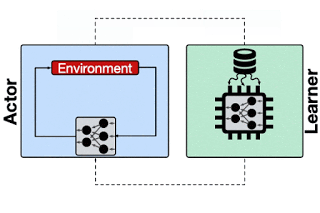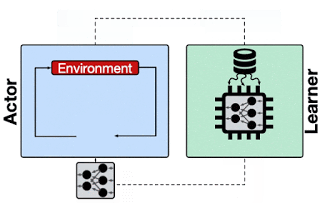
行為者が軌跡(trajectories、複数のサンプルデータなど)を学習者に送信するRLシステムの概要
学習者は、サンプルデータを使用してモデルをトレーニングし、更新されたモデルを行為者に戻します。(例えばTF-Agents、IMPALAなど)
本日、Mengerを紹介します。これは、局所型推論(localized inference)を備えた大規模な分散RLインフラストラクチャであり、複数の処理クラスター(Borgセルなど)により、全体で数千の行為者にスケールアップし、チップ配置設計タスクにおける全体的なトレーニング時間を短縮します。
本投稿では、Google TPUアクセラレータを使用してMengerを実装し、トレーニングの反復を高速化する方法について説明し、チップ配置設計を行う困難なタスクでのパフォーマンスと規模拡大性を示します。 Mengerは、比較対象とした実装よりトレーニング時間を最大8.6倍短縮できます。
Mengerのシステムデザイン
AcmeやSEED RLなど、様々な分散RLシステムが存在し、それぞれは分散強化学習システムとして、特定の設計ポイントに最適化することに重点を置いています。
例えば、Acmeは各行為者に局所型推論を使用して学習者から頻繁にモデルを取得します。その一方、SEED RLは、バッチ呼び出しを実行するためにTPUコアの一部を割り当てて、集中型推論(centralized inference)設計の恩恵を受けます。
これらの設計ポイント間のトレードオフは次のとおりです。
(1)通信コストの比較
集中型推論サーバーとの間で観測およびアクションを送受信するための通信コストを支払うか、学習者からモデルを検索する通信コストを支払うか?
(2)推論コストの比較
行為者(主にCPUで稼働)に推論させたコストとTPU/GPUなどのアクセラレーターに推論させたコストの比較
ターゲットアプリケーションの要件(観測サイズ、アクション、モデルのサイズなど)のため、MengerはAcmeと同様に局所型推論を使用しますが、行為者の規模拡張性を事実上無制限に押し上げます。
大規模な規模拡張性とアクセラレータの高速トレーニングを実現するための主な課題は次のとおりです。
(1)モデル検索のために行為者から学習者への多数の読み取り要求を処理しようとすると、学習者は容易に締め上げられる事になり、行為者の数が増えるに連れすぐに主要なボトルネック(例えば、収束時間が大幅に長くなります)になります。
(2)TPUのパフォーマンスは、トレーニングデータをTPUコンピューティングコアに供給する際の入力パイプラインの効率によって制限されることがよくあります。TPUコンピューティングコアの数が増える(TPUポッドなど)と、入力パイプラインのパフォーマンスは、トレーニングランタイム全体にとってさらに重要になります。
3.Menger:大規模な分散型強化学習(1/3)関連リンク
1)ai.googleblog.com
Massively Large-Scale Distributed Reinforcement Learning with Menger
2)github.com
deepmind / reverb

