
1.深層強化学習を使って半導体チップの設計を自動化
・機械学習に専用ハードウェアを使用する事が増えているがチップ設計に数年単位の時間がかかる
・チップ設計を強化学習に行わせて、過去の経験から学び、時間をかけて改善するアプローチを実現
・これによりハードウェアの発展と機械学習の発展に相乗効果が期待できるかもしれない
2.コンピュータの心臓部の設計を強化学習で効率化
以下、ai.googleblog.comより「Chip Design with Deep Reinforcement Learning」の意訳です。元記事は2020年4月23日、Anna GoldieさんとAzalia Mirhoseiniさんによる投稿です。
コンピュータの心臓部(Chip)の設計を機械学習を使って自動化して開発速度と効率を向上し、その結果、改良できたコンピュータを使って更に機械学習の開発が加速できたら良いですね、というお話です。Chip設計に関する解説部分は専門的な用語が沢山出て来ますが、斜め読みでも良いと思います。
アイキャッチ画像はChipから連想したロンドンのFish and Chipsの屋台でクレジットはPhoto by Jannes Van den wouwer on Unsplash
現代のコンピューティングの革命は、コンピューターシステムとハードウェアの目覚ましい進歩によって可能になった分野が多く存在します。
ムーアの法則とデナードの比例縮小則(訳注:トランジスタは小さくするだけで高速かつ低消費電力になっていくという1974年にロバート・デナードが共著した論文に基づく法則)の鈍化に伴い、世界は急激に増大するコンピューティング需要を満たすために、専用ハードウェアを使用する事が増えています。
ただし、現在は専用ハードウェアに搭載するチップの設計に数年かかるため、2~5年後の機械学習(ML:Machine Learning)モデル用に次世代のチップを最適化する方法について考える必要があります。
チップ設計サイクルを劇的に短縮すると、ハードウェアは急速に進歩するMLに適応できるようになります。MLを使ってチップ設計サイクルを短縮し、ハードウェアとMLをより統合する手段とし、それぞれがそれぞれの進歩を促進するとしたらどうでしょうか?
論文「Chip Placement with Deep Reinforcement Learning」では、チップの配置を強化学習(RL)の問題とみなし、エージェント(つまり、強化学習のポリシー)をトレーニングして、チップの配置に関する品質問題を最適化します。
従来の手法とは異なり、私達のアプローチには、過去の経験から学び、時間をかけて改善する能力があります。特に、より多くのチップブロックを使ってトレーニングを行うと、トレーニング中に出てこなかったチップブロックに対しても最適化された配置を迅速に生成する能力が向上しています。
比較対象となる既存の手法は人間の専門家による試行錯誤が必要であり、手動設計に数週間かかるのに対し、この手法では、手動で設計したものより優れた、またはそれに匹敵するチップの配置設計を6時間未満で生成できます。論文ではGoogleのアクセラレータチップ(TPU)用に最適化された配置が生成できる事を示していますが、この方法はあらゆる種類のチップ(ASIC)に応用できます。
チップの配置設計の問題
コンピュータチップは数十のブロックに分割されており、各ブロックはメモリサブシステム、演算ユニット、制御ロジックシステムなどの個別のモジュールです。
これらのブロックは、Macro(訳注:メモリマクロ化処理装置)やスタンダードセル(NAND、NOR、XORなどの論理ゲート)などで構成されています。また、これらの回路同士の接続状態は、ネットリストと呼ばれる図表で記述する事になっています。
チップブロックのレイアウトを決定するプロセスは、チップフロアプランと呼ばれ、チップ設計プロセスにおいて最も複雑で時間のかかる作業の1つです。
各種の制約(チップ同士の配置間隔や配線の密集度合)を順守しつつ、電力、パフォーマンスなどのネットリストをチップキャンバス(二次元の格子)に配置する必要があります。
この作業に関しては何十年にもわたる研究が続けられているにもかかわらず、人間の専門家は、多面的な設計要件を満たすために数週間にわたって作業を繰り返す必要があります。
この問題の複雑さは、ネットリストのサイズ(数百万から数十億のノード)から生じています。ネットリストのサイズは、配置場所の格子の細かさに比例し、これを業界標準の電子設計自動化ツールで設計すると、チップが満たすべき要件を計算するために何時間も(場合によっては一日以上)かかり、莫大なコストになります。
深層強化学習モデル
モデルへの入力は、
・チップのネットリスト(ノードのタイプと隣接情報)
・配置しようとする現在のノードのID
・ネットリストの捕捉データ(ワイヤーの総数、Macro、スタンダードセルクラスター)
などです。
ネットリストグラフと現在のノードは、入力状態をエンコードするために開発した「エッジベースのグラフニューラルネットワーク(edge-based graph neural network)」に入力として渡されます。これにより、部分的に配置されたグラフと候補ノードのembeddingsが生成されます。
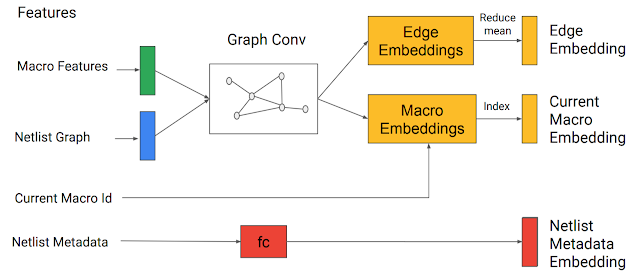
グラフニューラルネットワークはembeddingsを生成します。
これらは、メタデータのembeddingsと連結されて、ポリシーおよびバリューネットワークへの入力となります。
次に、エッジ、Macro、ネットリストのメタデータのembeddingsが連結されて、単一のembeddingsが形成され、フィードフォワードニューラルネットワークに渡されます。
フィードフォワードネットワークの出力は、有用な特徴を捕捉し、ポリシーおよびバリューネットワークへの入力として機能する学習済み特徴表現です。ポリシーネットワークは、現在のノードを配置できる全てのグリッドセルを対象に確率分布を生成します。
トレーニングの各反復で、Macroは強化学習エージェントによって順次配置されます。
その後、スタンダードセルクラスターが、力指向手法(force-directed method:二次元または三次元空間でグラフ間の辺の長さをほぼ等しく、且つ、グラフの辺ができるだけ交差しないようにするアルゴリズム)を使って配置されます。力指向手法は、回路をバネのシステム(system of springs)としてモデル化して、ワイヤー長を最小化しようとします。
強化学習トレーニングは、「おおよそのワイヤ長(例えば、HPWL、半周長のワイヤの長さ)の加重平均」と「その密集具合(例えば、配置されたネットリストによって消費される配線リソースの割合)」を使用して、エージェントの各チップ配置に対して計算された、高速だが概算の報酬信号によってガイドされます。

各トレーニングの反復中、Macroはポリシーによって一度に1つずつ配置され、スタンダードセルクラスターは力指向手法で配置されます。 報酬は、おおよそのワイヤ長の加重平均とその密集具合の組み合わせから計算されます。
結果
私達の知る限り、この手法は一般化する能力を備えた最初のチップ配置アプローチです。つまり、以前にネットリストを配置するときに学習したことを活用して、今までに見た事のない新しいネットリストの配置を改善できます。事前トレーニングを実行する際に学習用チップネットリストの数を増やすと(つまり、配置を最適化する方法をより経験するにつれて)、ポリシーが新しいネットリストに対応可能になっていく(つまり一般化されていく)事が示されています。
例えば、事前トレーニング済みポリシーは、組織的に配置を行います。
具体的には、Macroはチップの端の近くに配置し、中央に凸型スペースを配置して、そこにスタンダードセルを配置します。これにより、過剰な配線がなくなり、Macroとスタンダードセル間のワイヤ長が短くなります。
対照的に、ゼロからトレーニングしたポリシーはランダムに配置する事から開始し、高品質な配置を見つけるためにはるかに長い時間をかけて、最終的に、チップキャンバスの中央を開けておく必要性を再発見します。以下のアニメーションで確認できます。
オープンソースのRISC-VプロセッサーであるArianeにおけるMacro配置の学習進捗
左図:ゼロからトレーニングしたポリシー
右図:事前トレーニングを行いこのチップ用に微調整したポリシー
各長方形は、個別のMacroを表します。
ゼロからトレーニングしたポリシーが最終的に発見する中央の空白部分が事前トレーニング済みポリシーでは最初から存在していることに注目してください。
事前トレーニングにより、サンプルの効率と配置品質が向上している事が観察できました。
以下で、事前トレーニング済みのポリシーを使用して生成された配置設計の品質を、ゼロからトレーニングしたポリシーが生成した配置設計と比較します。
学習データ内に存在しなかった新規チップブロックで配置設計を行うために、ゼロショット法を使用します。つまり、事前調整済ポリシーに対して新規チップブロックを使った一切微調整を行いません。
その状態で、新しいブロックを配置し、1秒未満で配置設計を行います。
新規チップブロックのポリシーに対して微調整(Finetune a Pre-trained Policy)することにより、結果を更に改善する事もできます。
ゼロからトレーニングされたポリシー(From Scratch)は、収束にかなり時間がかかり、24時間後でも、、微調整されたポリシーが12時間後に設計するものよりも悪いです。
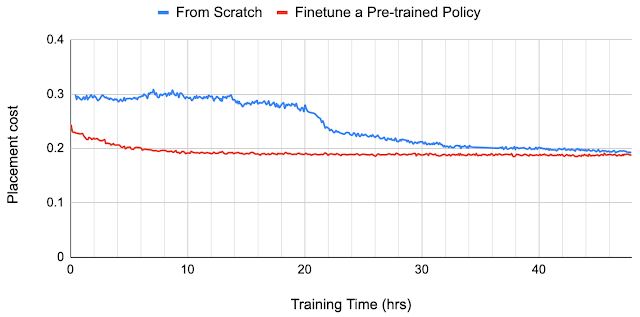
より大きなデータセットでトレーニングを行うと、パフォーマンスが向上します。
トレーニングセットを2ブロックから5ブロックに増やし、更に20ブロックに増やすと、ポリシーはゼロショット時(Zero-shot)でも微調整時(Fine-tune)でも、適切な配置設計を生成することがわかりました。
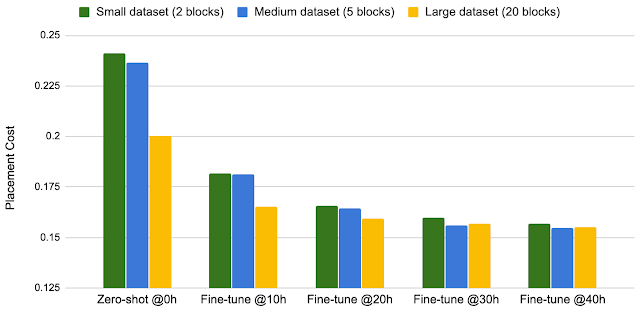
トレーニングデータのサイズとパフォーマンス
経験から学び、時間とともに改善する本アプローチの能力は、チップ設計者に新たな可能性の扉を開きます。
エージェントがより多くの学習でーたと多様なチップにさらされると、新しいチップブロックで最適化した配置を生成する速度と品質が向上します。高速で高品質な自動チップ配置方法は、チップ設計を大幅に加速し、チップ設計プロセスの初期段階の最適化を可能にします。
主にアクセラレータチップを評価しますが、提案された方法は、あらゆるチップ配置問題に広く適用できます。あらゆるハードウェアが機械学習を実行するために活用されている今、私達は機械学習が与えられた恩恵をハードウェアに対して返す時が来たと信じています。
謝辞
このプロジェクトは、Google Research teamとGoogle Hardware and Architecture teamの共同研究でした。私達は協力してくださった皆さん、
Mustafa Yazgan, Joe Jiang, Ebrahim Songhori, Shen Wang, Young-Joon Lee, Eric Johnson, Omkar Pathak, Sungmin Bae, Azade Nazi, Jiwoo Pak, Andy Tong, Kavya Srinivasa, William Hang, Emre Tuncer, Anand Babu, Quoc Le, James Laudon, Roger Carpenter, Richard Ho そしてJeff Deanの、この研究に対するサポートと貢献に感謝します。
3.深層強化学習を使って半導体チップの設計を自動化関連リンク
1)ai.googleblog.com
Chip Design with Deep Reinforcement Learning
2)arxiv.org
Chip Placement with Deep Reinforcement Learning

