
1.LaBSE:言語に依存しないBERT仕様のEmbedding(1/2)まとめ
・多言語アプローチは有用ではあるがパフォーマンスを維持しながら対応言語を増やすのは困難
・LaBSEは109の言語を使って訓練したBERT仕様で多言語共通なembeddingsを持つモデル
・トレーニングに利用できるデータが存在しない言語にとっても効果的なモデルとなった
2.LaBSEとは?
以下、ai.googleblog.comより「Language-Agnostic BERT Sentence Embedding」の意訳です。元記事の投稿は2020年8月18日、Yinfei YangさんとFangxiaoyu Fengさんによる投稿です。
Google翻訳は1つのモデルで全言語の翻訳を行うアプローチであり、それゆえ、2言語間の翻訳に特化しているモデルには翻訳品質の面で劣ると言う評価もあります。しかし、1つのモデルで対応するアプローチであるがゆえに、学習用データがあまり存在しない低リソース言語でも翻訳品質の向上ができている側面があり、その辺りの話は「Google翻訳の最近の進歩」などに詳しいです。今回、遂には学習用データが存在しない言語でもある程度対応できるようになっちゃいました、というお話です。
Labには実験室の意味以外にもラブラドル・レトリーバーの意味があるんですね、って事でアイキャッチ画像はcuteなpuppyでクレジットはPhoto by Jen Vazquez Photography on Unsplash
多言語Embeddingモデルは、様々な言語の文章を共有Embedding空間にエンコードする強力なツールです。テキストの分類、クラスタリングなどのさまざまな下流タスクに適用できると同時に、言語を理解するために意味情報を活用できます。
LASERやMultilingual Universal Sentence Encoderのような、このようなEmbeddingを生成する従来のアプローチは、翻訳元言語と翻訳先言語を並列に並べた言語資料に依存し、文章のEmbedding間の一貫性を促進するために、ある言語から別の言語に直接文を割り当てます。
これらの既存の多言語アプローチは、多くの言語で優れた全体的なパフォーマンスを発揮します。しかし、専用のバイリンガルモデル(つまり、二つの言語間の翻訳のみを行うモデル)と比較して、高リソース言語(利用できる学習データが多い言語)ではパフォーマンスが低下することが多いです。
専用のバイリンガルモデルは、翻訳ランキングを活用するアプローチ(Effective Parallel Corpus Mining using Bilingual Sentence Embeddings)を活用して、トレーニングデータに翻訳元言語と翻訳先言語のペアを使用して、より適切な翻訳を実現可能な言語表現を取得できます。
更に、モデル容量には制限がありますし、低リソース言語(利用できる学習データが少ない言語)ではトレーニングデータの品質も低いことが多いです。そのため、優れたパフォーマンスを維持しながら、多言語モデルを拡張してより多くの言語をサポートしていく事は難しい場合があります。
多言語のEmbedding空間のイラスト
言語モデルを改善するための最近の取り組みには、BERT、ALBERT、RoBERTaで使用されているような、マスクされた言語モデル(MLM:Masked Language Model)を使った事前トレーニングの開発が含まれます。このアプローチでは、単一言語のテキストのみが必要となるため、幅広い言語と様々な自然言語処理タスクに並外れた利益をもたらしました。
更に、MLM事前トレーニングは、多言語設定で利用できるように拡張されました。トレーニングデータに連結された翻訳文のペアを含める「翻訳言語モデリング(TLM:Translation Language Modeling)」か、または単に複数の言語から事前トレーニングデータを導入する事で、多言語設定に対応する手法が発表されています。
ただし、MLMおよびTLMトレーニング中に学習された内部モデル特徴表現は、下流タスクを微調整する時には有用ですが、翻訳タスクに不可欠な文レベルのembeddingを直接生成しません。
論文「Language-agnostic BERT Sentence Embedding」では、109の言語を使って、言語にとらわれないクロスリンガルな文のembeddingsを生成する、LaBSE(Language-agnostic BERT Sentence Embedding)と呼ばれる多言語のBERT仕様のembeddingsモデルを紹介します。
モデルは、MLMとTLMの事前トレーニングを使用して、170億の1か国語の文と60億の2か国語の文のペアでトレーニングされ、トレーニングに利用できるデータがない低リソース言語にとっても効果的なモデルになります。
更に、このモデルは、複数言語で記されているテキスト(別名bitextとして知られています)を検索するタスクにおいて新しい最先端のスコアを達成しました。トレーニング済みのモデルをtfhubを通じてコミュニティにリリースしました。これには、そのまま使用することも、領域固有のデータを使用して微調整するためのモジュールも含まれています。
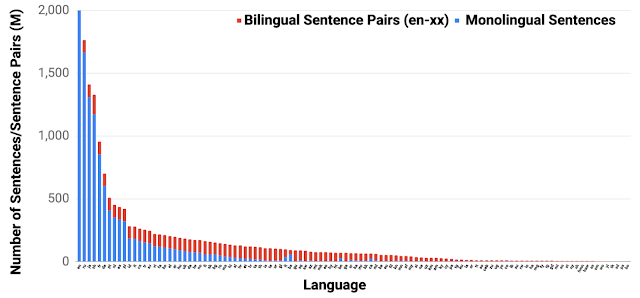
109のサポートされている言語のトレーニングデータの分布
モデル
以前の研究「Improving Multilingual Sentence Embedding using Bi-directional Dual Encoder with Additive Margin Softmax」では、多言語文用のembeddings空間を学習するために翻訳のランク付けタスクを使用する事を提案しました。
このアプローチでは、翻訳元言語の文章と翻訳先言語の複数の文章が与えられ、真の翻訳文を見つけるタスクをモデルに実行させます。翻訳ランキングタスクは、共有transformerエンコーダーを備えたデュアルエンコーダーアーキテクチャを使用してトレーニングされます。
結果として得られたバイリンガルモデルは、複数言語で記されているテキストを検索するタスク(United NationsとBUCCを含む)で最先端のパフォーマンスを実現しました。
ただし、バイリンガルモデルを拡張して複数の言語(テストケースでは16言語)をサポートすると、モデルの容量、語彙の範囲、トレーニングデータの品質などが制限されるため、モデルが影響を受けました。
翻訳ランキングタスク
特定の翻訳元言語の文が与えられ、翻訳先言語の複数の文章の中から真の翻訳文を見つけることがタスクの目的です。
3.LaBSE:言語に依存しないBERT仕様のEmbedding(1/2)関連リンク
1)ai.googleblog.com
Language-Agnostic BERT Sentence Embedding
2)arxiv.org
Language-agnostic BERT Sentence Embedding
3)research.fb.com
LASER LANGUAGE-AGNOSTIC SENTENCE REPRESENTATIONS
4)www.ijcai.org
Improving Multilingual Sentence Embedding using Bi-directional Dual Encoder with Additive Margin Softmax(PDF)
5)tfhub.dev
LaBSE
6)github.com
LASER/data/tatoeba/v1/

