
1.Federated Learning:分散した学習データを処理可能な統合的機械学習まとめ
・Federated Learningは分散したデータを用いて共通モデルを更新する
・学習はオンデバイスで実施するがクラウド上の共通モデルに差分を反映
・使用者に個別にパーソナライズしつつ、共通モデルの改良を実現
2.Federated Learningとは?
以下、ai.googleblog.com「Federated Learning: Collaborative Machine Learning without Centralized Training Data」の意訳です。元記事の投稿が2017年4月6日なので少し古いですが、「オンデバイスでディープラーニングを学習させる手法」で言及されていた投稿です。また、Federated Learningと似たコンセプトですが、2014年くらいから使われている同じくプライバシーを確保しながら統計的にデータを扱う手法、差分プライバシー(differential privacy)の2019年の実例についてはこちら。
2020年4月追記)コロナウイルス対策で大きく注目を集めている差分プライバシー(differential privacy)の実例がCOVID-19 Community Mobility Reportsです。
2020年6月追記)Federated Learningの仕組みを分析に利用できるようにしたFederated Analyticsという仕組みが紹介されました。
2022年1月追記)後続研究の記事を「Federated Reconstruction:部分的に端末内で連合学習を行い連合学習の規模を拡大」をアップしました。
一般的な機械学習では、学習データを1台のマシンまたはデータセンターに集中させる必要があります。Googleは、Googleのサービスを改善するために、最も安全で堅牢なクラウドインフラストラクチャを構築し、こういったデータの処理を行っています。今回の投稿では、ユーザ操作から得たデータをモバイルデバイスでトレーニングする新しいアプローチであるFederated Learningを紹介します。
Federated Learningは、携帯電話がすべてのトレーニング・データを電話内に保存しながら、共有予測モデルを共同学習することを可能にします。つまり、データをクラウドに格納する事なしに機械学習の実行を可能にするのです。
これは、モデルの学習をオンデバイスで実行する事によって、モバイルデバイスで予測を行うローカルモデル(Mobile Vision APIやOn-Device Smart Replyなど)の限界を超えています。
これは次のように機能します。貴方のスマホは現在のモデルをダウンロードし、貴方がスマホを用いて入力したデータを用いてモデルを学習し、改善し、小さな変更点としてまとめます。この変更点のみが、暗号化された通信を使用してクラウドに送信されます。クラウドでは、他のユーザーから送信された更新と共に平均化され、クラウド上の共有モデルが改善されます。すべてのトレーニングデータはスマホ上に残っており、個々の変更点はクラウドに保存されません。
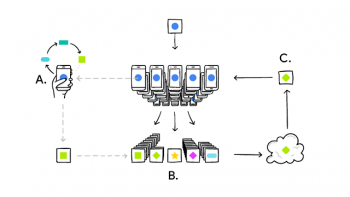
貴方のスマートフォンは、使用状況(A)に基づいてニューラルネットワークモデルを貴方に最適化(パーソナライズ)します。多くのユーザーのパーソナライズされたモデルの変更点が集約され(B)、共有モデルに反映され(C)、その後も同様な手順が繰り返されます。
Federated Learningでは、よりスマートなモデル、低レイテンシ、低消費電力を実現しながらプライバシーを確保します。また、このアプローチにはもう1つの利点があります。クラウドから共有モデルの更新を提供するだけでなく、携帯電話上でパーソナライズされた改良モデルをすぐに使用する事ができるので、携帯電話を使い方に合わせてすぐにそのカスタマイズされた機能を活用することができるのです。
Googleでは現在、AndroidのGboard、つまりGoogleキーボードでFederated Learningをテストしています。Gboardに変換候補が表示されると、現在の入力中の文脈に関する情報と、変換候補をクリックしたかどうかの情報がローカルデバイス(スマートフォン)に保存されます。
Federated Learningは、Gboardの変換候補提案モデルの履歴を保持し、モデルを改善し、次回の提案に生かします。
Federated Learningを可能にするために、アルゴリズム上および技術上の多くの課題を克服する必要がありました。典型的な機械学習システムでは、SGD(Stochastic Gradient Descent:確率的勾配降下法)のような最適化アルゴリズムをクラウド内のサーバーで均等に分割された大きなデータセットに対して実行します。しかし、このような何度も繰り返される反復アルゴリズムは、トレーニングデータへ迅速にアクセスできる事と、データの応答速度が速い事を必要とします。しかし、Federated Learningでは、データは非常に不均衡な状態で数百万のデバイスに分散されています。更に、これらのデバイスは、応答に時間がかかり、処理能力も低いため、断続的にしかトレーニングのために利用できません。
これらのネットワーク帯域幅と応答速度の制限は、Federated Averaging algorithmの開発動機に繋がりました。これは、単純なfederated版のSGDと比較して、10~100倍少ない通信量でディープニューラルネットワークを訓練することができます。
重要なアイデアは、最新のモバイルデバイスの強力なプロセッサを使用して、単純な勾配計算ではなく高品質な更新を計算することです。高品質な更新は優れたモデルを作成する際に反復回数が少なくて済むため、トレーニング時の通信量は大幅に削減されます。
アップロード速度は通常、ダウンロード速度よりもはるかに遅いため、ランダムローテーションと量子化を使用して更新部分を圧縮することでアップロードの際の通信コストを最大1/100にまで削減する斬新な方法を開発しました。これらのアプローチはディープネットワークのトレーニングに重点を置いていますが、クリックスルー率予測などの問題に優れた高次元の疎凸モデル(sparse convex)のアルゴリズムも設計しています。
この技術をGboardを実行する何百万もの異機種携帯電話に導入するには、洗練されたテクノロジーの積み重ねが必要です。オンデバイスのトレーニングでは、TensorFlowの小型バージョンを使用します。 慎重にスケジュールを立て、デバイスが何も操作されていない状態で、電源接続され、無料のワイヤレス接続に接続されている時にしかトレーニングは行われないため、スマートフォンのパフォーマンスに影響はありません。
貴方の携帯電話は貴方の操作感に影響を与えない時のみ、Federated Learningに参加します。
このシステムでは、安全で、効率的で、拡張性が高く、耐障害性のある方法で、モデルの更新を通信し、集約する必要があり、これには強力なインフラストラクチャが必要になります。Federated Learningの利点を生かすことができるのは、このインフラストラクチャと研究結果を組合せる事が出来たためえす。
Federated Learningは、ユーザーデータをクラウドに格納する必要なく動作しますが、それだけで終わりなわけではありません。暗号化技術を使用する Secure Aggregationプロトコルを開発しました。コーディネーションサーバーは、100人または1000人のユーザーが参加している場合にのみ平均更新を解読でき、集約化前に個々の電話の更新を検査することはできません。(訳注:つまり、コーディネーションサーバーに悪者が侵入しても、個人を特定する事が難しいと言う事です)
これは、ディープネットワークに関する問題や現実世界の接続制約に対対応した実用的な最初のプロトコルです。Federated Averagingは、コーディネーションサーバーが平均化した更新を必要とするようにデザインしたので、安全な集約を実現できます。しかし、この手法は一般化可能であり、他の問題にも適用することができます。 私たちはこの手法の実用化に向けて努力しており、近い将来Federated Learningをアプリケーション用に展開する予定です。
私たちの今回の仕事は、まだ表面的な部分を可能にしただけです。Federated Learningは、機械学習の全ての問題を解決することはできません。(例:注意深くラベル付けされたデータを使って犬種を分類することを学ぶなど)。また、他の多くのモデルでは、必要なトレーニングデータが既にクラウドに保存されています(Gmailの迷惑メールフィルタのトレーニングなど)。
そのため、GoogleはクラウドベースのMLの最先端技術を進化させ続けますが、Federated Learningで解決できる問題の範囲を広げるための継続的な研究にも取り組みます。Gboardの推測変換機能を超えて、たとえば、私たちはあなたがスマホに実際に入力したものに基づいてキーボードを改良するように言語モデルを改善したり、人々がどの種類の写真を見て、共有し、または削除するかに基づいて写真のランキングを作りたいと考えています。
機械学習の実践者が、Federated Learningを使いこなすためには、新しいツールと新しい考え方を学ぶ必要があります。通信コストが制限となり、モデルの作成、訓練、評価の際には生データやラベル付けデータに直接アクセスする事はできません。しかし、Federated Learningのユーザーメリットは、このような技術的な課題に取り組む価値のある事だと考えています。また、機械学習のコミュニティ内で広く議論される事を希望して私たちはこの成果を発表しました。
謝辞
この記事は、Google Researchの多くの人々の成果を反映しています。
BlaiseAgüeray Arcas, Galen Andrew, Dave Bacon, Keith Bonawitz, Chris Brumme, Arlie Davis, Jac de Haan, Hubert Eichner, Wolfgang Grieskamp, Wei Huang, Vladimir Ivanov, Chloé Kiddon, Jakub Konečný, Nicholas Kong, Ben Kreuter, Alison Lentz, Stefano Mazzocchi, Sarvar Patel, Martin Pelikan, Aaron Segal, Karn Seth, Ananda Theertha Suresh, Iulia Turc, Felix Yu, Antonio Marcedone, そしてGboardチームのパートナー。
3.Federated Learning:分散した学習データを処理可能な統合的機械学習関連リンク
1)ai.googleblog.com
Federated Learning: Collaborative Machine Learning without Centralized Training Data
