
1.PEGASUS:文章要約を行う最先端の人工知能(1/3)まとめ
・従来の自然言語の事前トレーニングは様々な下流タスクに流用できるように汎用的な目的だった
・事前トレーニングを最終的に実行するタスクに近づけたらパフォーマンスがどうなるか疑問を持った
・PEGASUSは欠落文を推測する事前トレーニングを行い要約タスクのパフォーマンスを向上した
2.PEGASUSとは?
以下、ai.googleblog.comより「PEGASUS: A State-of-the-Art Model for Abstractive Text Summarization」の意訳です。元記事の投稿は2020年6月9日、Peter J. LiuさんとYao Zhaoさんによる投稿です。
PEGASUSはペガサス、ギリシア神話に出て来る天馬、空を飛ぶことができる馬を意識した命名と思いますがペガサスは英語読みらしく、Wikipediaはラテン語読みのペーガススでした。アイキャッチ画像はピエール・ピュヴィス・ド・シャヴァンヌの『幻想』。岡山県倉敷市の大原美術館所蔵です。
2022年4月追記)PEGASUSで培われた技術が製品版のGoogleドキュメントの自動要約機能として取りこまれました
様々な場面で、学生は文書を読んで要約(例えば、本のレポート)を作成して、読解力と執筆能力の両方を実証する必要があります。
この文章を要約してまとめる作業は、長文の理解能力、情報の圧縮能力、言語の生成能力が求められるため、自然言語処理の中で最も困難な作業の1つです。
これを行うために機械学習モデルをトレーニングするために良く使われる枠組みは、シーケンスツーシーケンス(seq2seq)学習で、ニューラルネットワークは入力シーケンスを出力シーケンスに割り当てる事を学習します。
これらのseq2seqモデルは、当初はリカレントニューラルネットワークを使用して開発されました。しかし、最近は、Transformerエンコーダーデコーダーモデルが、要約作業時に遭遇する長文内の単語の依存関係のモデリングにより効果的であるため、好まれています。
自己教師型の事前トレーニングと組み合わせたTransformerモデル(例:BERT、GPT-2、RoBERTa、XLNet、ALBERT、T5、ELECTRA)は、言語学習のための強力なフレームワークであることが示されており、これらのモデルは様々な言語タスク用に微調整すると、最先端のパフォーマンスを出す事ができます。
以前の研究では、事前トレーニング用の自己教師は、一般性を優先するために、様々な下流タスクに流用できるような目的を設定されていました。
私達は、もし、自己教師の目的を最終的に実行するタスクにより厳密に近づけた場合、より良いパフォーマンスを達成できるのではないかと疑問に思いました。
論文「PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization」(ICML2020で発表)では、Transformerエンコーダー/デコーダーモデルの事前トレーニング時の自己教師の目標(gap-sentence generationと呼ばれます)を設計し、概要要約タスクの微調整のパフォーマンスを向上させました。
このモデルは12の多様な要約データセットで最先端の結果を達成しました。論文の補足として、GitHubでトレーニングコードとモデルチェックポイントも公開しています。
要約タスクのため自己教師
私達の仮説は、トレーニング前の自己教師の目的が最終的な下流タスクの内容に近いほど、微調整のパフォーマンスが向上するというものです
PEGASUS の事前トレーニングでは、いくつかの文が文書から削除され、モデルはそれらを復元する役割を求められます。
事前トレーニングの入力データは、欠落している文を含む文書全体ですが、出力は欠落している文を連結させた文章です。これは信じられないほど難しい作業であり、人間にとっても不可能に思えるかもしれません。
私達はモデルがこの作業を完全に解決することは期待していません。ただし、このようなチャレンジグなタスクにより、モデルは言語および世界の一般的な事実について学習し、ドキュメント全体から取得した情報を蒸留して、微調整の要約タスクと良く似た出力を生成する方法を学習できます。
この自己教師学習の利点は、人間による注釈が存在しなくても文書と同じ数だけデータを作成できることです。データの作成は、純粋な教師有り学習システムではボトルネックになる事がよくあります。
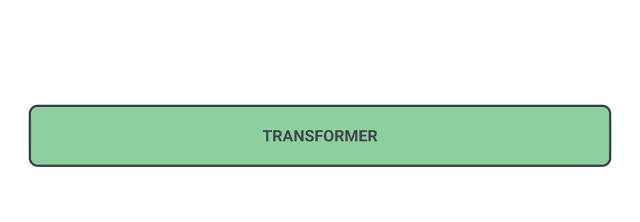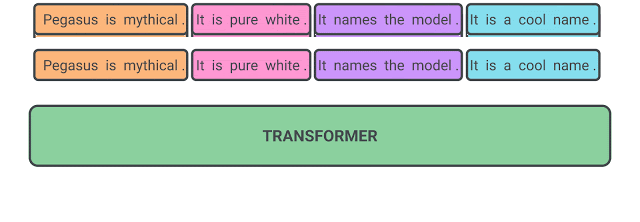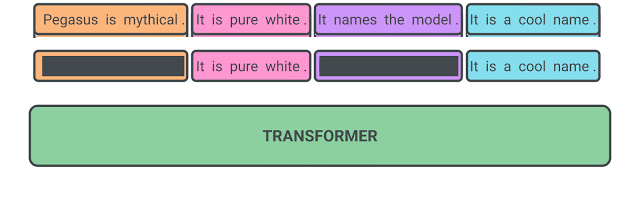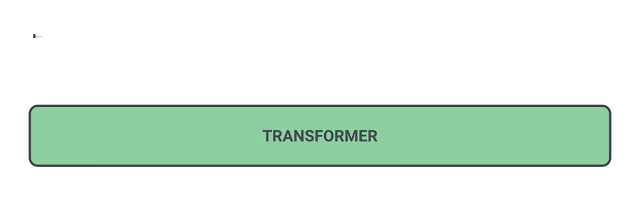
事前トレーニング中のPEGASUSの自己教師の例
モデルは欠落した全ての文を出力するようにトレーニングされます。
私達は「重要な文」をマスクする事が最も効果的であり、自己教師時に出力する文章を要約文に更に類似させることがわかりました。
ROUGEと呼ばれる基準を使い、文章の残りの部分に最も類似している文を見つけることにより、これらの「重要な文」を自動的に識別しました。
ROUGEは、0~100のスコアを使用してn-gramの重複を計算することにより、2つのテキストの類似度を計算します。(ROUGE-1、ROUGE-2、およびROUGE-Lの三つのバージョンがあります)
T5などの他の最近の手法と同様に、インターネットから収集した非常に大きなデータを使ってモデルを事前トレーニングし、次に12の公開されている概要要約用データセットでモデルを微調整しました。
パラメーター数はT5の5%相当数のみでありながら、自動で測定された基準では新たな最先端のスコアをもたらしました。
データセットは多様であるように選択されており、ニュース記事、科学論文、特許、短編小説、電子メール、法的文書、ハウツーの指示など、モデルが様々なトピックに適応していることを示しています。
3.PEGASUS:文章要約を行う最先端の人工知能(1/3)関連リンク
1)ai.googleblog.com
PEGASUS: A State-of-the-Art Model for Abstractive Text Summarization
2)arxiv.org
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
3)github.com
google-research/pegasus
4)www.aclweb.org
ROUGE: A Package for Automatic Evaluation of Summaries

