1.TAPAS:ニューラルネットワークを使って表形式データから自動で答えを抽出まとめ
・TAPASはBERTを拡張し、質問に対する回答を表形式データから直接抽出する新モデル
・質問と表形式のデータ構造を一緒にエンコードするアプローチによりこれを実現している
・弱い教師あり学習を使い学習用データを整備する手間を極力減らしても最先端のスコアを出せた
2.TAPASとは?
以下、ai.googleblog.comより「Using Neural Networks to Find Answers in Tables」の意訳です。元記事の投稿は2020年4月30日、Thomas Müllerさんによる投稿です。
Weak Supervision、すなわち「弱い教師」のアイディアはもっと重視されるようになってくるのではないかと思っています。
強い教師「猫とは食肉目ネコ科ネコ属に分類されるリビアヤマネコが家畜化されたイエネコに対する通称だ!」
弱い教師「にゃーん、って鳴くのが猫ですよぉ~」
的なイメージで、初めて弱い教師のアイディアを知った時はとても衝撃を受けました。
ただし、正直、T5やMeenaの話を読んでしまうと、弱い教師でさえ近い将来に不要になるのではないかと思えてくる時もあります。しかし、まぁ、強大な企業群が膨大なコンピュータ資源を使って殴り合ってる世界にはおいそれとは入っていけませんから、あっちは「えっと、決着がついたら教えてください」のスタンスでも良いのかな、と思っています。
今回のお話のように特定分野の特定形式のデータを抽出して整理して(おそらく将来的には転移する)技術については最終的にはニッチな用途になるのかもしれませんが、やっぱり重要だし「使える」機械学習だと思うですよね。面白いと感じた方は以下も読んでおくと良いと思います。
Weak Supervision:機械学習のための新しいプログラミングパラダイム
Snorkel Drybell:既存知識を活用して機械学習用ラベル付きデータを自動作成
GWASkb:ゲノムワイド関連解析情報を論文から自動抽出
アイキャッチ画像はメキシコのストリートレスリングのレスラー。本文と関係なさそうに見えますが、おそらく元記事の著者はこの画像のチョイスを見たら喜ぶのとmaskとstrongにもひっかけてます。クレジットはPhoto by Joe Hernandez on Unsplash
表形式だけでなはく定型書式からデータを抽出する場合はこちら
2021年2月追記)TAPASを改良した後続研究のお話はこちら
世界の情報の多くは表形式で保存されており、インターネット上やデータベース、ドキュメント内に存在します。これらには、消費者製品の技術仕様から金融および国の開発統計、スポーツの結果など、あらゆるものが含まれます。
現在、表形式データから必要な情報を得るためには、これらの表を目で確認して質問への回答を見つけるか、特定の質問(スポーツの結果など)への回答を提供するサービスに依存する必要があります。しかし、表内に存在する欲しい情報を自然な文章で照会できれば、はるかにアクセスしやすく、役立つでしょう。
たとえば、次の図は、人々が質問する可能性のあるいくつかの質問に対する回答を含む表を示しています。
これらの質問への回答は、テーブルの1つまたは複数のセルに存在「Which wrestler had the most number of reigns?(どのレスラーが最も多く王座に就きましたか?)」か、複数のテーブルセルを集約する必要があります。「How many world champions are there with only one reign?(一度だけ王座に就いた世界チャンピオンは何人ですか?)」

予想される回答を含む表と質問。回答は選択(no1とno4)、または計算(no2とno3)する事で得られます。
最近の多くのアプローチでは、こういった問題に従来の意味解析を適用しています。つまり、自然言語による質問文を、SQLのようなデータベース用の問い合わせ文に変換し、それを用いて回答が引き出されるアプローチです。
例えば、自然言語の「How many world champions are there with only one reign?」はSQLの「select count(*) where column(“No. of reigns”) == 1;」のような問い合わせ文に変換されます。そしてこのSQLが実行されて答えが生成されます。
このアプローチは、多くの場合、構文的および意味的に有効な問い合わせ文を生成するためにかなりの技術的諸問題の解決を必要とし、特定のテーブル(スポーツの結果など)に関する質問を超えて、任意の質問に対応できるように規模を拡大する事は困難です。
ACL 2020で受理された論文「TAPAS: Weakly Supervised Table Parsing via Pre-training」では、BERTアーキテクチャを拡張し、結果を直接指すモデルを作成します。質問と表形式のデータ構造を一緒にエンコードするアプローチによりこれを実現します。
このアプローチでは、特定形式のテーブルに対してのみ機能するモデルを作成するのではなく、幅広い領域のテーブルに適用できるモデルが作成されます。Wikipediaに掲載されている数百万のテーブルで事前トレーニングを行った後、私達のアプローチが3つの学術テーブルに関する質問回答(QA)データセットで競争力のある精度を示す事を示します。
更に、この領域でよりエキサイティングな研究を促進するために、モデルのトレーニングとテスト、およびWikipediaテーブルで事前トレーニングされたモデルのコードをオープンソース化しました。これは、GitHubリポジトリで入手できます。
質問文の処理方法
「Average time as champion for top 2 wrestlers?(上位2レスラーの平均王座防衛期間は何日ですか?)」などの質問を処理するために、私達は、BERTモデルを使用して、質問と行毎のテーブルコンテンツを一緒にエンコードします。このBERTモデルは、テーブル構造をエンコードする特別なembeddingsに対応するように拡張されています。
transformerベースのBERTモデルへの主要な機能追加は、構造化された入力データをエンコード可能な特別なembeddingsです。このembeddingsは列インデックス、行インデックス、および数値列の要素の順位を示す特別なランクインデックスを学習しています。
次の画像は、これらの全てが入力でどのように加算され、transformerレイヤーに供給されるかを示しています。次の図は、質問がどのようにエンコードされるかを、左側に示す小さな表とともに示しています。
各セルトークンには、行、列、および列内の数値ランクを示す特別なembeddingを持ちます。
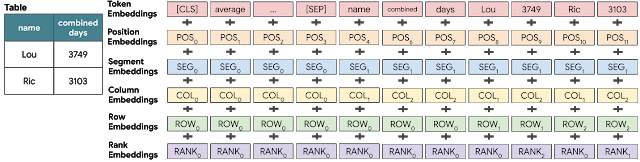
BERTレイヤーの入力
全ての入力トークンは、単語のembeddings、絶対位置、セグメント(質問文とテーブルのどちらに属しているか)、列と行、および数値ランク(列が数値でソートされた場合のセルの順位)の合計として表されます
モデルは2つの出力を持ちます。
(1)各テーブルセルについて、このセルが回答の一部になる確率
(2)最終的な回答を生成するために演算が必要な場合、その演算用の集約関数
次の図は、「Average time as champion for top 2 wrestlers?(上位2レスラーの平均王座防衛期間は何日ですか?)」という質問に対して、モデルが「Combined days(合計在位期間)」列の最初の2つのセルと「Average(平均)」操作を高い確率で選択する方法を示しています。
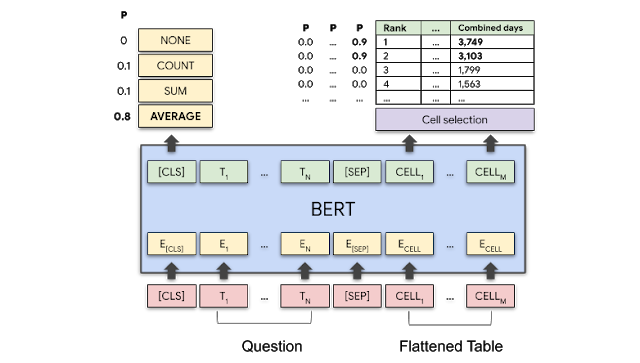
モデルの概略
BERTレイヤーは質問とテーブルの両方をエンコードします。
モデルは、全ての集計操作の確率と全てのテーブルセルについて選択される確率を出力します。質問「Average time as champion for top 2 wrestlers?」には AVERAGE演算と、3,749および3,103のセルが高い確率を持つはずです。
事前トレーニング
文章のみを使用してBERTをトレーニングする手法と同様の手法により、英語版ウィキペディアから抽出された620万のテーブルとテキストのペアでモデルを事前トレーニングしました。
事前トレーニング中、モデルには、テーブルとテキストの両方でマスクされた単語を復元する事を学習させました。その結果、モデルが比較的高い精度でマスクされた単語を復元できる事がわかりました。(トレーニング中に出現しなかったテーブルであっても、71.4%でマスクされた単語を正しく復元可能です)
定義ではなく回答のみを使って学習
モデルは微調整中にテーブルデータを使って質問に答える方法を学習します。これは、「強い教師有り学習(strong supervision)」または「弱い教師有り学習(weak supervision)」のいずれかによるトレーニングを通じて行われます。
強い教師の場合、特定のテーブルと質問に対して、選択すべきセルと集計操作(SUMやCOUNTなど)を厳密に指定する必要があります。これは、時間と手間が非常にかかるプロセスです。
より一般的なアプローチの1つは、弱い教師を使ってトレーニングを行う事です。弱い教師では、正しい答え(例えば、上記の例の質問では3426)のみが提供されます。
この場合、モデルは、正しい答えに近い答えを生成する集計操作とセルを見つけようとします。これは、計算可能な全ての集計操作に対する期待値を計算し、その計算結果を真の答えと比較する事によって行われます。
弱い教師を使ったアプローチは、機械学習の専門家ではない人であってもモデルのトレーニングに必要なデータを提供でき、強い教師よりも時間がかからないため、有益です。
結果
モデルを3つのデータセット(SQA、WikiTableQuestions(WTQ)、およびWikiSQL)を使って評価し、表形式データの解析で優秀なスコアを出す上位3つの最先端モデル(SOTA:state-of-the-art)とパフォーマンスを比較しました。
比較対象としたモデルは、WikiSQLではMin等による「A Discrete Hard EM Approach for Weakly Supervised Question Answering」、WTQではWang等による「Learning Semantic Parsers from Denotations with Latent Structured Alignments and Abstract Programs」、及び、SQAでは、私達自身の以前の作業「Answering Conversational Questions on Structured Data without Logical Forms」の論文によるモデルです。
全てのデータセットで、弱い教師でトレーニングしたモデルを検証用データセットで回答精度を測定しました。
SQAとWIkiSQLの場合は、Wikipediaで事前トレーニングしたベースモデルを使用しましたが、WTQの場合は、SQAデータで更に事前トレーニングすると有益であることがわかりました。
私達の最高のモデルは、SQAの以前のSOTAを12ポイント以上、WTQの以前のSOTAを4ポイント以上上回っており、WikiSQLでも公開されている最高のモデルと同等のスコアを出しました。
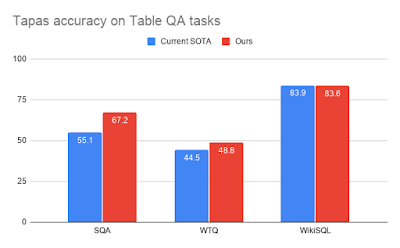
3つの学術的なTableQAデータセットにおける弱い教師を使った解答精度
謝辞
この作業は、チューリッヒのGoogle AI言語グループのJonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno および Julian Martin Eisenschlosによって行われました。
有用なコメントと提案を提供してくれたYasemin Altun, Srini Narayanan, Slav Petrov, William Cohen, Massimo Nicosia, Syrine Krichene, そして Jordan Boyd-Graberに感謝します。
3.TAPAS:ニューラルネットワークを使って表形式データから自動で答えを抽出関連リンク
1)ai.googleblog.com
Using Neural Networks to Find Answers in Tables
2)arxiv.org
TAPAS: Weakly Supervised Table Parsing via Pre-training
3)github.com
google-research/tapas
4)www.aclweb.org
A Discrete Hard EM Approach for Weakly Supervised Question Answering
Learning Semantic Parsers from Denotations with Latent Structured Alignments and Abstract Programs
Answering Conversational Questions on Structured Data without Logical Forms

