
1.酵母と機械学習の力で老化現象の謎に挑むまとめ
・酵母は実験室で成長しやすく、人間の細胞と同様に細胞核を持っているため遺伝子実験に使いやすい
・更に酵母は単細胞生物でありながら、成長して老化し、通常30回発芽を行った後に死亡する
・酵母を使って遺伝子の影響をデータ化し機械学習で処理すれば老化現象に迫る事ができるかもしれない
2.酵母と機械学習
以下、ai.googleblog.comより「Applying Machine Learning to…..Yeast?」の意訳です。元記事の投稿は2020年4月29日、Ted Baltzさんによる投稿です。
健康診断を受けると、どうみても私より不健康な生活をしている人が私よりコレステロール値が良いと言う事が良くあります。お医者さんに聞くと「うーん、こういうのって遺伝による影響が大きいんですよね~」と言われるので、おそらく私は高コレステロール体質になる遺伝子を持っていると思うのですが、遺伝子とはそんなにシンプルに因果関係が把握できるものではないそうです。
「遺伝子Aが多くて、遺伝子Bが少なくて、その影響で遺伝子Cが時間の経過と共に多くなり、更に遺伝子Dが・・・・その結果、食べた分がダイレクトに体重に反映される体質になる」
といった感じで、非常に関係が複雑で、遺伝子情報を格納する共通学術データベースでさえ整備しきれていない可能性を指摘される現状です。
でもこういった「何か良くわからない非常に複雑なデータ」を使って「予測」を行うのって機械学習が大得意な分野じゃないですか。そして、酵母を使うと比較的データの収集がしやすいので、細胞の老化現象を引き起こしている遺伝子が何なのかわかってくるかもしれない、って事が今回のお話です。
アイキャッチ画像は遺伝の不思議から連想したインドネシアの三つ子さんでクレジットはPhoto by rahmani KRESNA on Unsplash
人類と酵母には長い歴史があり、これは穀物の栽培化の始まりと結びついています。
パン屋さん(または醸造家)が使う酵母であるSaccharomyces cerevisiae(出芽酵母)は、数千年にわたって穀物をパン(またはビール)の形にし、より消化しやすくするために使用されてきました。
現代も酵母は大きな影響を与えており、生物学者はそれを生物学的研究、特に遺伝学を研究する際のモデル生命体として採用しています。これは、酵母が実験室で成長しやすく、真核生物(つまり、バクテリアとは異なり、人間の細胞と同様に細胞核を持っています)であるためです。
酵母は生物学的コミュニティ内で「the awesome power of yeast genetics(酵母遺伝学の脅威の力)」という独自のキャッチフレーズさえ獲得しています。
遺伝学の基礎を学ぶために酵母を研究する事は人類の遺伝子を研究するよりはるかに簡単です。しかし、約1000の酵母遺伝子には人類の遺伝子と共通の祖先をもつ箇所があるため、研究結果は人類にも適用できるのです。遺伝子がシステムとしてどのように連携しているかを理解することは、あらゆる生物を理解するための中核です。そして、これがこの微生物への関心を高めています。
Calico Life Sciences社(訳注:老化とそれに伴う病気に関する研究をしているGoogleの子会社の一つです)との共同研究として、Molecular Systems Biology誌に掲載された論文「Learning causal networks using inducible transcription factors and transcriptome-wide time series」を発表します。
徹底的な実験に基づいて、出芽酵母における遺伝子発現の制御を調べるために統計的な手法で機械学習モデルを構築し、結果の一部を実験的に検証し、まだあまりよく理解されていない生物分野への将来の調査を可能にしました。
Induction Dynamics gene Expression Atlasは、Pythonで簡単に操作できる形式でCalicoのWebサイトから入手できます。また、操作用のコードもオープンソースで公開されておりGoogle ResearchのGitHubからダウンロードできます。データは標準的なGene Expression Omnibus形式で提供されています。
酵母を使用して老化現象への洞察を提供
酵母は出芽と呼ばれるプロセスを通じて繁殖します。このプロセスでは、小さな芽が親の表面から成長し、ほとんど遺伝的に同一の子孫が生まれます。
興味深いことに、酵母は単細胞生物ですが、成長して年を取り、通常30回発芽を行った後に死に至ります。実際、出芽による「傷跡」は強力な顕微鏡ではっきりと見えるので、見るだけで細胞の年齢を知ることができます。問題は、研究者が何故老化が起こるのか原因をまだ知らないことです。
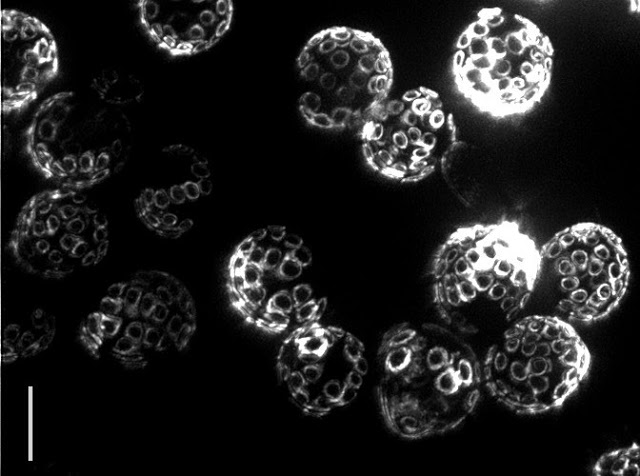
古い酵母細胞の芽の傷跡。(左下の縦棒は5μmの長さを表してます)写真クレジト:Ian Foe(Calico)
Calico Life Sciences社の科学者達は、老化が分子レベルでどのように機能するかを理解することを目的として、酵母の遺伝子に摂動を与えて発現を促す技術(つまり、特定の遺伝子の活動をオンにしたりオフにしたりする事を可能にする技術)を開発しました。
酵母の老化を理解することが、人間などのより複雑な生物の老化にも当てはまる事が期待されています。この作業は、時間の経過と共に細胞の挙動がどのように変化するかを理解し、変化を予測するフレームワークを構築するための最初の一歩です。
遺伝子発現実験
訳注:映画や小説などから「DNA」と言う単語がなんとなく遺伝に関連するものと言うイメージは持っていると思うのですが、DNAとは遺伝情報を書いておく設計図みたいなものです。設計図を元に製品化する、つまり細胞を作りあげる際にはRNAが活躍します。この製品化過程の事を遺伝子発現(Gene Expression)と言います。このあたりの話が面白く感じたら現実世界で始まっている遺伝子治療の実例であるLydian Acceleratorのお話も読んでおくと良いです、去年末に無事に一歳のお誕生日を迎えたそうです。
DNA内に書かれている遺伝子は、RNAに転写された後にのみ機能するようになります。RNAがリボソームによって「翻訳」または「読み取り」されてタンパク質が生成され、タンパク質が遺伝情報に基づいた生物の体を構成します。
タンパク質の生産レベルは、DNAから転写されるRNAの量によって決まります。細胞で行われる作業のほとんどはタンパク質が関わるため、タンパク質は細胞の挙動を理解するための鍵となります。
そのため、タンパク質の生産レベルを測定したいのですが、この微少な規模のタンパク質を特定する作業は非常に手間がかかります。RNAレベルの測定の方がより簡単なため、本実験では、代わりに代替手段としてRNAを使用します。
遺伝子発現実験とは、個々の遺伝子を攪乱し、他の全ての遺伝子がどのように反応するかを時間をかけて測定する実験です。個々の遺伝子の変化が引き起こす挙動を迅速に追跡できるため、他のほとんどの実験では捕捉できない因果関係や非線形的な関係を調べる事ができます。
この実験データは、機械学習の予測モデルのトレーニングにも使用できます。
これは、外部からの刺激(本実験ではβ-estradiolホルモン)に反応する単一の遺伝子を持つ酵母菌株によって可能になりました。遺伝子を攪乱させるために、ホルモンを注入します。刺激を受けた遺伝子は10分以内に50倍過剰生産されるようになります。次に、培養した酵母を様々なタイミングでサンプリングして、遺伝子発現レベルを測定します。この実験は並行して行う事が可能で、培養毎に1つの酵母株を使って同時に実行されました。
ほとんどの実験は、転写因子(TF:transcription factors)を持つ特定種の遺伝子に対して行われました。これらの遺伝子は、遺伝子発現を制御する主要因子であり、実際にDNA鎖に結合するタンパク質を設計し、特定の遺伝子の転写を許可またはブロックします。
遺伝子(a)がオンになると、遺伝子(b)が増加し、遺伝子(c)が減少し、一定時間後に遺伝子(d)が増加する可能性があります。酵母には6000を超える遺伝子があるため、単一の遺伝子を混乱させることによる下流への影響を追跡することは、非常に複雑になります。異なる遺伝子の実験を組み合わせることにより、正確な制御メカニズムを明確にしたいと考えました。
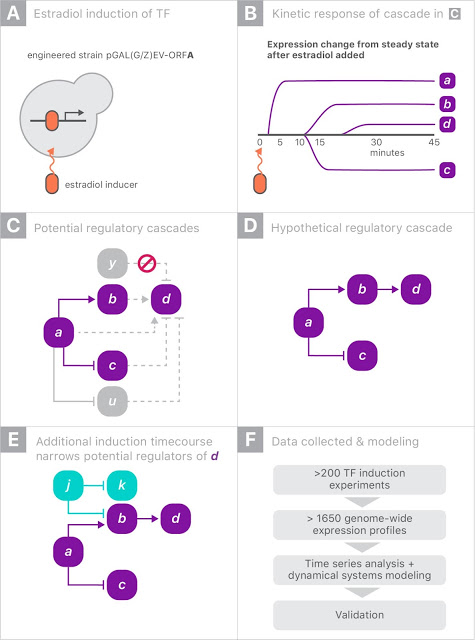
遺伝子摂動実験の模式図
制御可能な遺伝子を持つ酵母株(a)が存在するとします。
「(A)単一の遺伝子をオンにする」と「(B)時間の経過と共に異なるレベルの遺伝子発現b,c,d」が生じます。「(CおよびD)他の遺伝子をオンにする」ことによって引き起こされる変化を追跡し、比較することで、「(E)遺伝子の調節メカニズムに対する洞察」を得ることができます。
遺伝子発現モデル
この実験では、データの規模と、Googleの機械学習の専門知識とコンピューティングリソースを活用する機会があることから、Calico社と提携しました。
様々な酵母株に対して200以上の摂動実験を行い、それぞれの実験で単一の遺伝子を活性化しました。各実験では、6000の遺伝子全てに関して発現レベルが90分間に8回測定され、合計でほぼ2,000万の個別測定値が得られました(上図のパネルF)。
このデータを分析するためには 明らかに、幾つかの作業を自動化する必要がありました。
私達のアプローチは、プロセス全体を微分方程式としてモデル化することでした。「遺伝子の発現の変化率」は「全ての遺伝子の発現レベルの加重和」に比例します。
最初に、各時点間の発現レベルを単純に引き算する事で、データから時間による変化率(時間微分)を推定しました。次に、生の発現レベルのみを使用して時間微分を予測しました。
線形回帰式に当てはめることにより、遺伝子制御を表現する微分方程式系の係数を当てはめます。私達の希望は、微分方程式モデルが、より簡単に解釈できるデータの低次元表現になることです。過学習を避けるため、情報量の少ないパラメーターをゼロに設定することを好むL1-normを使用してモデルを正則化しました。
200の実験のそれぞれが一意であるため、それぞれを順に学習しました。モデルを再適合し、最適なハイパーパラメータを選択し、サンプルデータに存在しないデータにも対応できるように損失関数を最適化しました。
結局、作業にはかなりの量の計算が必要になり、合計で5,000万を超える試行錯誤が必要となりました。
モデル結果
私たちのモデルは、どの遺伝子が遺伝子発現を中間制御するかについて予測を行いました。これは、生物の完全な遺伝子制御ネットワークをモデル化する試みです。
これらの予測を検証するために、Calicoの共同研究者は、新しい10の酵母からより多くのデータを収集しました。10のうち3は今回の実験で予測されたものです。
モデルが有効と予測した遺伝子の1つは、従来は検証されていなかった転写因子を含んでいました。また以前に制御機能を持っていると識別されていたけれども、深く追求されていなかったもう1つは、非常に有効な制御機能を持つ事がモデルによって発見されました。
ゲノミクス分野内での本研究の影響についてのより多くの議論は、www.embopress.orgで閲覧可能です。
謝辞
Marc Coram, Minjie Fan, and Marc Berndlがこの作業の基礎を成す貢献をしてくれた事、Google Accelerated Scienceチームの継続的なサポート、及びCalico社の全チームの皆さんに協力して実験をする機会を頂けた事に感謝します。
3.酵母と機械学習の力で老化現象の謎に挑む関連リンク
1)ai.googleblog.com
Applying Machine Learning to…..Yeast?
2)www.embopress.org
Learning causal networks using inducible transcription factors and transcriptome‐wide time series
A Bright IDEA
3)idea.research.calicolabs.com
IDEA: Induction dynamics gene expression atlas
4)github.com
google-research/yeast_transcription_network/

