
1.Performers:Attentionの規模拡大を容易にする(1/3)まとめ
・Transformerの中心となるAttentionモジュールはデータが長くなると計算が困難になる
・類似性スコアを計算するため指数関数的に計算量と必要メモリが増大してしまうため
・Performerは線形に一般化されたAttentionで規模拡大がしやすく応用範囲が広い
2.Performersとは?
以下、ai.googleblog.comより「Rethinking Attention with Performers」の意訳です。元記事の投稿は2020年10月23日、Krzysztof ChoromanskiさんとLucy Colwellさんによる投稿です。
Attentionは内部的にペアを行列として計算/保存するので、入力が長くなると2次関数的に計算量もメモリ使用量も多くなってしまって規模拡大が難しかったのを、工夫して行と列で表現できるようにしたので、入力が長くなっても一次関数的に計算機資源が増えるだけで済むようになった!と言うお話で、つまりTransformerの輝きが更に増していくと言う事ですね。
アイキャッチ画像はPerformerで検索すると映画Jokerの影響でダークな感じの画像が多く出て来る中で明るいながらも哀しみを同時に表現できているように見えたPerformerでクレジットはPhoto by Marine Golfetto on Unsplash
Transformerを使ったモデルは、自然言語、人間とのチャット、画像、更には音楽など、様々な分野で最先端の結果を達成しています。
全てのTransformerアーキテクチャの中心となる箇所はAttentionモジュールです。これは、連続した入力データ内の位置の全てのペアの類似性スコアを計算します。
ただし、Attentionは入力データが長くなるにつれてに対応が困難になります。入力データが長くなるにつれて、全ての類似性スコアを計算するために指数関数的に計算量が増大し、更にこれらのスコアを格納する行列を構築するために必要なメモリサイズも指数関数的に増大します。
遠く離れた位置に関してもAttentionが必要になるアプリケーションでは、メモリキャッシュ技術など、高速で空間効率が高い代替手段がいくつか提案されていますが、はるかに一般的な方法は、Sparse Attention(まばらな注意)を使う事です。
Sparse Attentionとは、全ての取りうるペアではなく連続データから限定した類似性スコアを選択して計算することにより、計算時間とAttentionメカニズムのメモリ要件を削減し、完全な行列ではなくsparse matrix(まばらな行列)を生成します。
これらのまばらな手法はSparse Transformers、Longformers、Routing Transformers、Reformers、そしてBig Birdなどのモデルで実現されています。これらは、手動で設計されていたり、最適化方法を追求する中で発見されたり、学習結果であったり、ランダム化した結果であったりします。
sparse matrixはグラフとエッジで表現する事もできるため、まばらにする手法もグラフニューラルネットワークの文献によって活発に行われており、Attentionとグラフの特定の関係はGraph Attention Networksで概説されています。
まばらにする事、つまりスパース化をベースとしたアーキテクチャでは、通常、完全なAttentionメカニズムを暗黙的に生成するために追加のレイヤーが必要です。
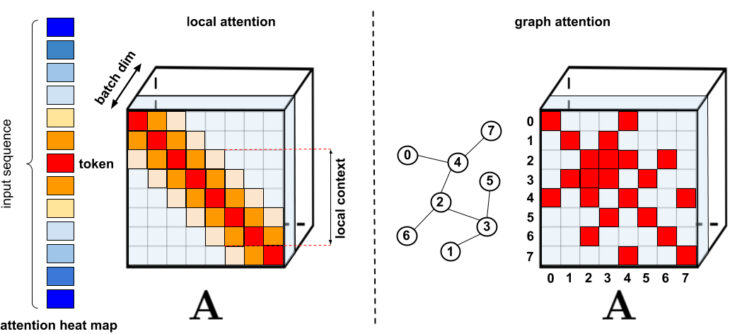
標準的なスパース化手法
左:local attention、近くに存在するトークンのみを対象とするスパースパターン
右:グラフアテンションネットワークでは、グラフ内の隣接するトークンのみ対象とします。グラフ内で近隣であれば、他のトークンよりも関連性が高いはずだからです。様々な手法の包括的な分類については、論文「Efficient Transformers: A Survey」を参照してください。
残念ながら、Sparse Attentionメソッドにはまだいくつかの制限があります。
(1)効率的にまばらな行列の行列演算を行う事が必要ですが、全てのアクセラレータ(GPU,TPU)で実装されているわけではありません。
(2)通常、こらの表現力に対する厳密な理論的保証が提供されていません。
(3)これらは主にTransformerモデルと生成的事前トレーニング(generative pre-training)用に最適化されています。
(4)通常、スパース表現を補正するためにより多くのAttentionレイヤーを積み重ねるため、他の事前トレーニング済みモデルでの使用する事が困難になり、再トレーニングと大量のエネルギー消費が必要になります。
これらの欠点に加えて、Sparse Attentionメカニズムは、通常のAttentionが適用される全ての問題に対処するにはまだ十分ではないことがよくあります。Pointer Networksなどは扱う事ができません。
また、一般的に使用されるソフトマックス演算など、スパース化できない演算もあります。
この操作は、Attentionメカニズムの類似性スコアを正規化するものであり、youtubeの推薦システムなどのような巨大な業界規模のシステムで頻繁に使用されます。
これらの問題を解決するために、指数関数的でなく線形に規模を拡大するAttentionメカニズムを備えたTransformerアーキテクチャであるPerformerを導入します。これにより、ImageNet64などの特定の画像データセットやPG-19などのテキストデータセットに必要な、モデルがより長い長さを処理できるようにしながら、より高速なトレーニングが可能になります。
Performerは、効率的に(線形に)一般化されたAttentionフレームワークを使用します。これにより、様々な類似性の尺度(カーネル)に基づいた幅広いクラスのAttentionメカニズムが可能になります。
このフレームワークは、FAVOR+(Fast Attention Via Positive Orthogonal Random Features)アルゴリズムを介して実装されています。
FAVOR+は、規模拡大がしやすい低分散で偏りのないAttentionメカニズムの推定を提供します。これは、random feature map分解(特に、通常のsoftmax-attention)によって表現されます。
私達は線形空間と時間の複雑さを維持しながら、この手法の精度を強力に保証します。これは、単独のソフトマックス操作にも適用できます。
3.Performers:Attentionの規模拡大を容易にする(1/3)関連リンク
1)ai.googleblog.com
Rethinking Attention with Performers
2)arxiv.org
Rethinking Attention with Performers
Efficient Transformers: A Survey
3)github.com
google-research/performer/fast_self_attention/
google-research/performer/
google-research/protein_lm/

