
1.PlaNet:画像入力から世界モデルを学ぶ強化学習(1/3)まとめ
・PlaNetはモデルベース(Model-based)強化学習であり世界モデルを学ぶ強化学習
・世界モデルを学ぶと従来より少ないデータで効率的な学習を行う事ができる
・PlaNetは画像入力からダイナミクスを学習しそれを効率的に利用して新たな経験を得る
2.世界モデルとは?
以下、ai.googleblog.comより「Introducing PlaNet: A Deep Planning Network for Reinforcement Learning」の意訳です。元記事は2019年2月15日、Danijar Hafnerさんによる投稿です。続きはこちら。
人工知能が彼ら自身の決定を改善する手法の研究は強化学習によって急速に進歩しています。強化学習では、人工知能エージェントは、センサーの入力を受け取って観察しながら(例えばカメラ画像)、行動を選択(例えばモーターを動かす)し、そして時には特定の目標を達成した事に対して報酬を受け取ります。
モデルフリー(Model-free)強化学習のアプローチは、感覚的観察から望ましい行動を直接予測することを目的としており、DeepMindのDQNがAtariのゲームをプレイする事や人工知能エージェントがロボットを制御することを可能にします。しかしながら、このブラックボックスアプローチは試行錯誤を通して学ぶために数週間のトライアンドエラーをしばしば必要とし、実践時にはその有用性が制限されます。
対照的に、モデルベース(Model-based)強化学習は、人工知能エージェントに自身が関わっている世界がどのような法則に従っているか学習させようと試みます。
入力と行動を人間が直接関連づけないので、エージェントは長期的な結果を「想像する」ことによって行動をより慎重に選択する事が可能になり、前もって明確に計画することができるようになります。
モデルベースのアプローチは、碁の世界チャンピオンを打ち破ったAlphaGoを含み、かなりの成功を収めました。AlphaGoは、碁のルールに基づいて架空の碁盤上で碁を打つ事を想像しました。ただし、未知の環境(入力としてカメラからの画素のみが与えられてロボットを制御するケースなど)でプランニングするには、エージェントは経験からルールまたはダイナミクス(相互作用)を学習する必要があります。
ダイナミクスを学習したモデルは原則としてより高い効率と自然なマルチタスク学習を可能にするので、プランニングを成功させるのに十分正確なダイナミクスモデルを作成することは強化学習の長年の研究課題です。DeepMind社と共同でこの研究課題の進展を促進するために、画像入力のみから世界モデルを学習し、それをプランニングにうまく活用するDeep Planning Network(PlaNet)エージェントを紹介します。
PlaNetはさまざまな画像ベースの制御タスクを解決し、最終的なパフォーマンスに関しては高度なモデルフリーエージェントと競合しながら、平均で5000%以上のデータ効率性を実現します。私たちはさらに研究コミュニティが構築するためのソースコードを公開しています。
2000回の試みで、PlaNetエージェントは画像からさまざまな連続制御タスクを解決することを学びました。世界モデルを学習していない従来のエージェントは、同等のパフォーマンスを達成するために約50倍の試行回数を必要とします。
PlaNetのしくみ
端的に言えば、PlaNetは与えられた画像入力からダイナミクスモデルを学習し、それを効率的に利用して新たな経験を得ます。画像をそのまま使ってプランニングする従来の手法とは対照的に、私達は隠されたまたは潜在的なシンプルな法則に頼ります。これは潜在ダイナミクスモデル(latent dynamics model)と呼ばれます。
ある画像から次の画像を直接予測するのではなく、潜在状態の変化を予測します。各ステップでの画像と報酬は、対応する潜在状態から生成されます。このように画像を圧縮することによって、エージェントは自動的にオブジェクトの位置や速度などのより抽象的な表現を学ぶことができます。そして、作業途中で画像を生成せずに前方予測を簡単にする事ができます。
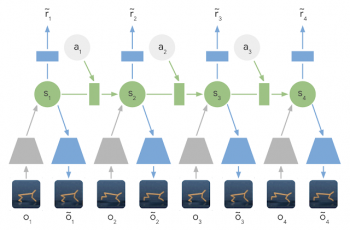
潜在ダイナミクスモデルの学習:潜在ダイナミクスモデルでは、入力画像の情報は、エンコーダネットワーク(灰色の台形)を使用して隠れ層(緑色)に統合されます。隠れ層は、将来の画像(青い台形)と報酬(青い長方形)を予測するために時間的に前に投影されます。
(PlaNet:画像入力から世界モデルを学ぶ強化学習(2/3)に続きます)
3.PlaNet:画像入力から世界モデルを学ぶ強化学習(1/3)関連リンク
1)ai.googleblog.com
Introducing PlaNet: A Deep Planning Network for Reinforcement Learning

訳注:ここでいっているモデルはニューラルネットワークや機械学習の「モデル」でなく、世界モデルの「モデル」です。例えば、人間は物理世界のモデル、つまり物理世界が重力などの様々な法則や原理に基づいている事を知っているので物体Aを投げると床に落下するならば、物体Bを今まで見た事がなくとても同様に投げれば床に落下するであろうと推測できます。人工知能は物理世界のモデルを理解していないので、物体Bを実際に投げなければ物体Bがどうなるか予測する事ができず、人間に比べて学習に必要な試行回数も時間も大幅に増えてしまうのです。