
1.Zari:事前トレーニング済みNLPモデル内の性別決めつけを緩和(1/2)まとめ
・NLPの事前トレーニングでは外科医とメスの関係などの概念間の相関関係も学習している
・概念間の相関関係は実タスクで性別の決めつけのようなバイアスをもたらす可能性がある
・モデルが性別や職業を「~であるべき」という性別を決めつけていないか確認をした
2.Zariとは?
以下、ai.googleblog.comより「Measuring Gendered Correlations in Pre-trained NLP Models」の意訳です。元記事の投稿は2020年10月14日、Kellie Websterさんによる投稿です。
アイキャッチ画像のZARIはアフガニスタンで「きらめく」を意味する名前で「小さな女の子も他の人と同じようにできるという事実を強調するために」生み出されたアフガニスタンのローカル番組向けのマペットだそうで、アフガニスタンに住んでいる何事にも前向きで熱心な6歳の女の子の設定です。
言語モデルとしてのZariは、Bert兄ちゃんの親戚で、Bert、Albert兄ちゃんズより代名詞を文脈に沿って解釈できる素直な子くらいのイメージで良いと思います。
自然言語処理(NLP)は、BERT、ALBERT、ELECTRA、XLNetなどの事前トレーニング済みモデルがさまざまなタスクで驚くべき精度を達成することで、過去数年間で大きな進歩を遂げました。
事前トレーニングでは、特徴表現は巨大なテキスト、例えば、Wikipediaなどの資料から学習されます。文章内の単語の一部を隠してその内容を予測させる事を繰り返して学習させます。この手法はマスク言語モデリング(masked language modeling)と呼ばれます。
結果として得られる特徴表現は、言語に関する豊富な情報、例えば外科医とメスの関係などの概念間の相関関係を内包します。
次に、2番目のトレーニング段階である微調整があります。この段階では、モデルはタスクに固有のトレーニングデータを使用します。分類などの具体的なタスクを実行するために、どのように第一段階で学習した一般的な事前トレーニング済み特徴表現を使用するかを学習します。
多くのNLPタスクでこれらの特徴表現が広く採用されていることを考えると、これらのモデルを適用する際に、それがGoogleのAI原則に沿っていることを確認する事は重要です。
そのためには、それらが事前学習で学んだ情報と、概念間の相関関係が実際のタスクでどのようにパフォーマンスに影響するかを理解することが重要です。
論文「Measuring and Reducing Gendered Correlations in Pre-trained Models」では、BERTとそれに対応するメモリ使用量が少ないALBERTで事例調査を実行し、性別に関連する相関関係を調べ、事前トレーニングされた言語モデルを使用するための一連の効率良い手法を策定します。
公開モデルのチェックポイントと学術的データセットを用いた実験結果を提示して、効率良い手法がどのように適用されるかを示し、この事例の範囲を超えて調査を行うための基盤を提供します。
私達は間もなく一連のチェックポイントとしてZariをリリースします。これは、標準のNLPタスクで最先端の精度を維持しながら、性別による相関関係の影響を軽減します。
相関関係の測定
事前トレーニングされた特徴表現の相関関係が実際のタスクのパフォーマンスにどのように影響するかを理解するために、性差研究の様々な評価指標をセットで適用します。
以下では、これらのテスト結果の1つについて説明します。
このテストは共参照解決(coreference resolution)に基づくもので、モデルが「文中の代名詞が指している実体」を理解できるかを確かめます。
例えば、次の文では、モデルは、his(彼)がpatient(患者)ではなくnurse(看護師)を指していることを認識する必要があります。
The nurse notified the patient that his shift would be ending in an hour.
このタスクで標準的に用いられる学術的定式化は、OntoNotesテストです。(Hovy等による2006の研究「OntoNotes: The 90% Solution」)。
そして、このデータのF1スコアを使用して、標準的な設定でモデルが共参照をどれほど正確に解決しているかを測定します(Tenney等による2019年の研究「What do you learn from context? Probing for sentence structure in contextualized word representations」のように)。
OntoNotesは1つのデータ分布しか表現できないため、モデルが内包する性別と職業間の関連付けが、共参照を解決する際に誤った影響を及ぼしてしまったケースを識別できるように設計された、バランスの取れたデータを提供するWinoGenderベンチマークも追加で検討します。
WinoGenderで高い値(1に近い)が測定されたと言う事は、モデルが性別と職業を規範的な関連付け(normative associations、~であるべきという慣習な関連付け)に基づいて判断している事を示します。(例えば、看護師を男性ではなく女性の性別と関連付けてしまう)
モデルの決定に性別と職業の間に一貫した関連性がない場合、スコアはゼロです。これは、決定が文の構造や意味などの他の情報に基づいていることを示しています。
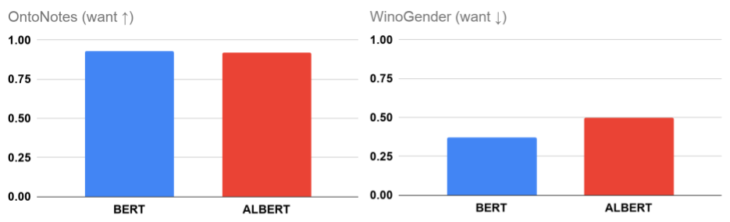
BERTおよびALBERTのOntoNotes(精度)およびWinoGender(性別相関)の測定値
WinoGenderの測定値が低い場合は、モデルが推論時に性別相関を優先的に使用していないことを示します。
この調査では、OntoNotesで印象的な精度(100%に近い)を達成しているにもかかわらず、(Large) BERT及びALBERTの公開モデルのどちらもWinoGenderではスコアゼロを達成していないことがわかります。
この結果は少なくとも一部では、モデルが推論時に性別相関を優先的に使用してしまっている事が原因です。
これは衝撃を受けるべき事ではありません。
テキストを理解するために利用できる様々な手がかりがあり、汎用的なモデルはこれらのいずれかまたは全てを理解することが可能です。しかしながら、モデルが、入力された文章内に存在する手がかりではなく、事前に学習した性別相関に主に基づいて予測を行うことは望ましくないため、注意が必要です。
3.Zari:事前トレーニング済みNLPモデル内の性別決めつけを緩和(1/2)関連リンク
1)ai.googleblog.com
Measuring Gendered Correlations in Pre-trained NLP Models
2)arxiv.org
Measuring and Reducing Gendered Correlations in Pre-trained Models
3)www.aclweb.org
OntoNotes: The 90% Solution
4)catalog.ldc.upenn.edu
OntoNotes Release 5.0
5)openreview.net
What do you learn from context? Probing for sentence structure in contextualized word representations
6)github.com
rudinger / winogender-schemas

