
1.Google Research:2020年の振り返りと2021年以降に向けて(3/5)まとめ
・機械学習アルゴリズムや基礎理論の研究により効率的な手法の探求が前進
・強化学習は履歴データの利用やサンプル効率の向上、適用分野の拡大
・AutoMLは最新のアルゴリズムを自律的に発見し、効率的なモデルを創造
2.アルゴリズム、強化学習、AutoML、機械学習の理解
以下、ai.googleblog.comより「Google Research: Looking Back at 2020, and Forward to 2021」の意訳です。元記事の投稿は2021年1月12日、Jeff Deanによる投稿です。
元記事の方でarxiv.orgやneurips.cc等に直リンクしているものが多すぎて関連リンクにまとめる事を断念しています。
アイキャッチ画像のクレジットはPhoto by Roberto Nickson on Unsplash
(9)機械学習アルゴリズム
私達は、システムがより迅速に、より少ない教師付きデータから学習できるようにする新しい機械学習アルゴリズムとアプローチの開発を続けています。
ニューラルネットワークのトレーニング中に中間結果を再生することで、MLアクセラレータのアイドル時間を埋めることができ、したがってニューラルネットワークをより速くトレーニングできることがわかりました。
トレーニング中にニューロンの接続を動的に変更することにより、静的に接続されたニューラルネットワークと比較してより良いソリューションを見つけることができる事がわかりました。
また、「同じ画像に異なる変換を加えてそれらの間の一致を最大化」し、「異なる画像に異なる変換を加えてそれらの間の一致を最小化」する、新しい自己監視および半教師あり学習手法であるSimCLRも開発しました。このアプローチは、最高の自己教師あり学習手法を大幅に改善します。
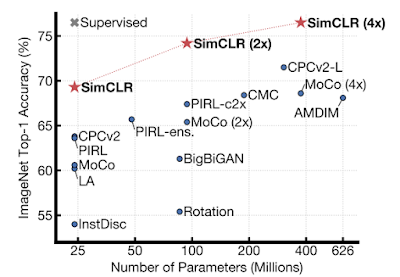
様々な自己教師あり手法で学習された特徴表現でトレーニングされた線形分類器のImageNetのTop1精度
(ImageNetで事前トレーニング済み)。 灰色の×印は、教師あり学習のResNet-50です。
また、対照学習の概念を教師あり学習に拡張した教師あり対照学習(Supervised Contrastive Learning)を発表し、教師あり分類問題のクロスエントロピーを大幅に改善する損失関数を作成しました。
(10)強化学習
限られた経験から長期的に適切な意思決定を行うことを学ぶ強化学習(RL:Reinforcement Learning)は、私たちにとって重要な重点分野です。RLの重要な課題は、限られたデータポイントから意思決定を行うことを学ぶことです。固定データセットからの学習、他のエージェントの経験からの学習、探索の改善を通じて、RLアルゴリズムの効率を改善しました。
今年の主な重点分野はオフラインRLでした。これは、以前に収集された固定のデータセット(例えば、以前の実験や人間によるデモンストレーションから)を使って学習する強化学習です。本番環境からトレーニングデータを収集できないようなアプリケーションにも強化学習が拡張可能になります。
RLに双対性(Duality)アプローチを導入し、ポリシー外評価、信頼区間の推定、およびオフラインポリシー最適化のための改善されたアルゴリズムを開発しました。さらに、オープンソースのベンチマークデータセットとAtariのDQNデータセットをリリースすることで、これらの問題に取り組むために幅広いコミュニティと協力しています。

DQNリプレイデータセットを使用したAtariゲームのオフラインRL
別の一連の研究では、見習い学習(apprenticeship learning)を通じて他のエージェントから学習することにより、サンプルの効率が向上しました。知識を持つエージェント(informed agents)から学習する方法、他のエージェントの分布と一致させる方法、または敵対的なサンプルから学習する方法を開発しました。
RLでの探索を改善するために、ボーナスベースの探索方法を探索しました。これには環境について事前の知識を持っているエージェントによる構造化された探索を模倣できる模倣技術を含みます。
また、強化学習の数学的理論も大幅に進歩しました。私達の主な研究分野の1つは、最適化プロセスとしての強化学習の研究でした。
フランク・ウルフアルゴリズム(Frank-Wolfe algorithm)、モメンタム法、カルバック・ライブラー発散正則化(KL divergence regularization)、作用素論(operator theory)、および収束分析と強化学習の関連性を見いだしました。
これらの洞察のいくつかは、挑戦的なRLベンチマークで最先端のパフォーマンスを実現するアルゴリズムと、RLと教師あり学習の両方で多項式伝達関数がソフトマックスに関連する収束問題を回避するという発見につながりました。
安全な強化学習についても、いくつかのエキサイティングな進歩を遂げました。ここでは、重要な実験的制約を尊重しながら、最適な制御ルールを見つけようとしています。これには、安全なポリシー最適化のためのフレームワークが含まれます。
モバイルネットワークから電力網まで、多数の意思決定者がいるシステムをモデル化する平均フィールドゲームと呼ばれる問題のクラスを解決するための効率的なRLベースのアルゴリズムを研究しました。
RLを複雑な現実世界の問題にスケールアップするための重要な課題である、新しいタスクと環境への一般化に向けたブレークスルーを実現しました。
2020年の重点分野は、集団ベースのlearning-to-learn手法でした。ここで、別のRLまたは進化的エージェントがRLエージェントの母集団をトレーニングして、創発的(個々の性質の単純な総和にとどまらない性質が、全体として現れること)な複雑さのカリキュラムを作成し、新しい最先端のRLアルゴリズムを発見しました。
「Estimating the Impact of Training Data with Reinforcement Learning」と「Using Selective Attention in Reinforcement Learning Agents」では、はるかに熟練したRLエージェントを生みだしました。
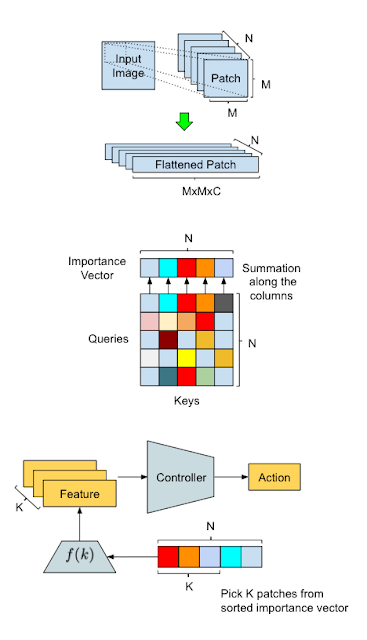
AttentionAgentでの手法概要とデータ処理フロー図
上部:入力変換。スライディングウィンドウは入力画像を小さな断片に分割し、将来の処理のためにそれらを「平坦化」します。中央部:分割した断片の選択。変更された自己Attentionモジュールは、断片間の投票を保持して、断片の重要度ベクトルを生成します。下部:アクションの生成。AttentionAgentは最も重要な断片を選択し、対応する特徴表現を抽出して、それらに基づいて決定を下します。
更に、予測行動モデルの学習がRL学習を加速することを示すことにより、モデルベースのRLを進歩させました。これは、多様なチームでの分散型の協調型マルチエージェントタスクを可能にし、長期目線の行動モデルを学習する事に繋がります。
スキルが環境に予測可能な変化をもたらすことを観察する事により、教師なしでスキルを発見する事ができました。より良い特徴表現はRL学習を安定させ、階層的な潜在空間(hierarchical latent spaces)と価値向上パス(value-improvement paths)はより良いパフォーマンスをもたらす事がわかりました。
RLを規模拡大して製品化するためのオープンソースツールを共有しました。ユーザーが取り組む範囲と問題を拡大するために、超並列RLエージェントであるSEEDを導入し、RLアルゴリズムの信頼性を測定するためのライブラリをリリースしました。
新しいバージョンのTFエージェントをリリースしました。これには分散RL、TPUのサポート、およびバンディットアルゴリズムのフルセットが含まれます。
さらに、ハイパーパラメータの選択とアルゴリズムの設計を改善するために、RLアルゴリズムの大規模な実証研究を実施しました。
最後に、Loonと共同で、成層圏気球をより効率的に制御するためにRLをトレーニングおよび展開し、電力使用量とナビゲート能力の両方を改善しました。
(11)AutoML
学習アルゴリズムを使用して新しい機械学習の手法とソリューション、つまりメタ学習を開発することは、非常に活発で刺激的な研究分野です。
この分野でのこれまでの多くの研究で、洗練された手動設計部品を興味深い方法で組み合わせる方法を見つける方法を検討する探索スペースを作成しました。
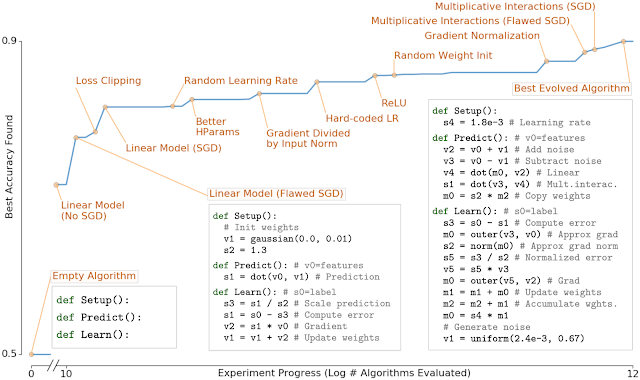
「AutoML-Zero:Evolveing Code that Learns」では、進化的アルゴリズムに非常に原始的な操作(加算、減算、変数の割り当て、行列の乗算など)で構成される探索スペースを与えて、最新のMLアルゴリズムをゼロから進化させる事が可能かどうかを確認するという、別のアプローチを採用しました。
この分野での有用な学習アルゴリズムの存在は非常にまばらであるため、システムがますます高度化するMLアルゴリズムを徐々に進化させることができたことは注目に値します。次の図に示すように、システムは、線形モデル、勾配降下法、正規化線形単位、効果的な学習率の設定と重みの初期化、勾配の正規化など、過去30年間で最も重要なMLの発見の多くを再発明できました。
また、メタ学習を使用して、静止画像とビデオの両方でオブジェクトを検出するためのさまざまな新しい効率的なアーキテクチャを発見しました。
効率的な画像分類アーキテクチャのためのEfficientNetに関する2019年の作業では、画像分類の精度が大幅に向上し、計算コストが削減されました。
2020年の後続の作業「EfficientDet: Towards Scalable and Efficient Object Detection」ではEfficientNetの作業に基づいて、オブジェクトの検出と局所化のための新しい効率的なアーキテクチャを導き出し、最高の絶対精度と計算コストの削減の両方で顕著な改善を示しています。 所定のレベルの精度を達成するために、以前のアプローチに比較して13~42倍の計算量を削減しました。
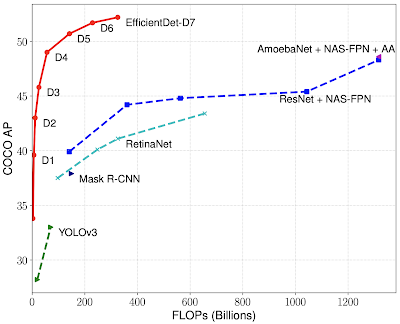
EfficientDetは、同じ設定でCOCO test-devを使用して、最新の52.2 mAPを達成しました。これは、以前の最先端技術(3045B FLOPであるため図には表示されていません)から1.5ポイントの上昇です。同じ精度を達成するという制約の下で、EfficientDetモデルは4倍から9倍小さく、以前の検出器よりも13倍から42倍少ない計算量しか必要としません。
SpineNetの研究では、空間情報をより効果的に保持できるメタ学習アーキテクチャについて説明しており、より細かい解像度で検出を行うことができました。
また、様々なビデオ分類問題の効果的なアーキテクチャの学習にも焦点を当てました。「AssembleNet: Searching for Multi-Stream Neural Connectivity in Video Architectures」、「AssembleNet++: Assembling Modality Representations via Attention Connections」および「AttentionNAS: Spatiotemporal Attention Cell Search for Video Classification」では、進化的アルゴリズムを使用して新しい最先端のビデオ処理を行う機械学習アーキテクチャを作成する手法を示しまた。
このアプローチは、時系列予測のための効果的なモデルアーキテクチャを開発するためにも使用できます。「Using AutoML for Time Series Forecasting」ではAutoMLを使用して、多くの興味深い種類の低レベルな基礎的土台を含む探索スペースでの自動探索を介して新しい予測モデルを検出するシステムについて説明しました。その有効性は、生成したアルゴリズムでKaggleのM5予測コンペティションに参加する事で実証されました。
本アルゴリズムは5558人の参加者のうち138位(上位2.5%)を達成しました。
競合する予測モデルの多くは、作成に数か月の手作業が必要でしたが、AutoMLソリューションは、適度な計算コスト(500 CPUで2時間)を使用し、人の介入なしでモデルを短時間で作成できました。
(12)MLアルゴリズムとモデルのより良い理解
機械学習のアルゴリズムとモデルをより深く理解することは、より効果的なモデルを設計およびトレーニングするため、またモデルが失敗する可能性がある場合を理解するために重要です。
昨年は、表現力、最適化、モデルの一般化、ラベルノイズなどに関する基本的な質問に焦点を当てました。
この投稿で前述したように、Transformerネットワークは、言語、音声、および視覚の問題のモデリングに大きな影響を与えましたが、これらのモデルによって表される関数のクラスは何でしょうか?
最近、Transformerがsequence-to-sequence関数の普遍近似器(universal approximators)であることを示しました。更に、sparse transformersは、トークン間の相互作用を線形にのみを使用する場合でも、普遍近似器のままです。
Transformerの収束速度を改善するために、レイヤーごとのアダプティブラーニングレートに基づく新しい最適化手法を開発しています。例えば「Large batch optimization for deep learning (LAMB): Training BERT in 76 minutes.」です。
ニューラルネットワークがより広く、より深くなるにつれて、それらはしばしばより速く訓練出来、よりよく一般化するようになります。古典的な学習理論は大規模なネットワークがより過剰適合する必要があることを示唆しているため、これはディープラーニングの中心的な謎です。私たちは、この過剰にパラメータ化された体制でニューラルネットワークを理解するために取り組んでいます。
無限幅の境界では、ニューラルネットワークは驚くほど単純な形を取り、ニューラルネットワークガウスプロセス(NNGP:Neural Network Gaussian Process)、またはニューラルタンジェントカーネル(NTK:Neural Tangent Kernel)によって記述できます。この現象を理論的および実験的に研究し、研究者が無限幅のニューラルネットワークを構築およびトレーニングできるようにするJAXで記述されたオープンソースソフトウェアライブラリであるNeural Tangentsをリリースしました。
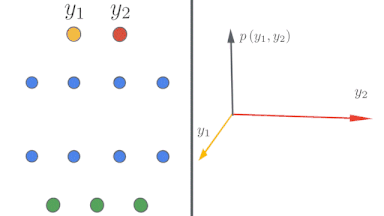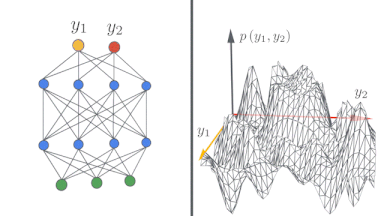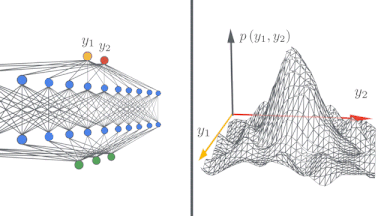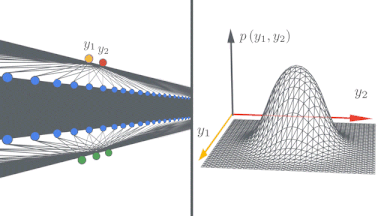
左:ディープニューラルネットワークが無限に広くなるにつれて、単純な入力/出力マップがどのようになっていくかを示す概略図。
右:ニューラルネットワークの幅が広がるにつれて、ネットワークのさまざまなランダムな実体に対する出力の分布がガウス分布になることがわかります。
有限幅のネットワークが大きくなると、それらは独特の二重降下現象も示します。一般化が向上し、次に悪化し、幅が大きくなるにつれて再び向上します。この現象は、偏りと分散の分解(bias-variance decomposition)によって説明できる事、更に、三重降下として現れることもあることを示しました。
最後に、現実世界の問題では、多くの場合、重大なラベルノイズに対処する必要があります。たとえば、大規模な学習シナリオでは、大量に利用可能なのは簡易的にラベル付けされた弱い教師データであり、ラベルが持つノイズが大きくなります。激しいノイズを持つラベルから効果的な教師を抽出し、最先端の結果をもたらすための新しい技術を開発しました。
ランダムなラベルを使用してニューラルネットワークをトレーニングする効果をさらに分析しました。それはネットワークパラメータと入力データ間の調整につながり、ゼロから初期化するよりも高速に下流タスクをトレーニング可能になることを示しました。
また、ラベルスムージングまたは勾配クリッピングがラベルのノイズを軽減できるかどうかなどの疑問を調査し、ノイズの多いラベルを使用した堅牢なトレーニング手法を開発するための新しい洞察をもたらしました。
3.Google Research:2020年の振り返りと2021年以降に向けて(3/5)関連リンク
1)ai.googleblog.com
Google Research: Looking Back at 2020, and Forward to 2021
2)research.google
Publication database
