
1.RigL:ニューラルネットワークの冗長性を動的に最適化(1/3)まとめ
・最新のディープニューラルネットワークアーキテクチャは冗長性が高い場合が多い
・重要度の低い接続を刈り取る事で疎なニューラルネットワークに改良すると性能が上がる
・しかし、刈り込みは非効率的でモデルの最大サイズが制限されると言う制限があった
2.sparse neural networkとは?
以下、ai.googleblog.comより「Improving Sparse Training with RigL」の意訳です。元記事の投稿は2020年9月16日、Utku EvciさんとPablo Samuel Castroさんによる投稿です。
pruning、つまり枝刈りをイメージしたアイキャッチ画像のクレジットはPhoto by fran hogan on Unsplash
最新のディープニューラルネットワークアーキテクチャは冗長性が高い場合が多く、パフォーマンスを損なうことなくネットワーク接続のかなりの部分を削除することができます。
結果として生じる「疎なニューラルネットワーク(sparse neural networks)」は、「密なニューラルネットワーク(dense neural networks)」と比較してより多くの有効パラメーターと計算効率を示し、多くの場合、推定にかかる時間を大幅に短縮できます。
疎なニューラルネットワークをトレーニングするための最も一般的な方法は、刈り込み(pruning、dense-to-sparse training)です。
これは通常、最初に密なモデルをトレーニングし、次に無視できる重みとその接続を刈り取ることによって「疎に」する手法です。ただし、この手法には2つの制限があります。
(1)疎なモデルの最大サイズは、密なモデルのサイズによって制限されます。
疎なモデルの方がパラメータ効率が高い場合でも、刈り込みを使用して、密なモデルよりも大きくて正確なモデルをトレーニングすることはできません。
(2)刈り込みは非効率的です。
例えば値がゼロのパラメータ、または推論中に値がゼロになるパラメーターに対しても大量の計算を実行する必要があります。更に、現在の最良の刈り取るアルゴリズムのパフォーマンスが疎なモデルの品質上限であるかどうかは不明のままです。
しかしながら、疎なネットワークを最初からトレーニングすることは効率的ですが、刈り取り手法に比べて推論パフォーマンスが劣ることがよくあります。
ICML 2020で発表した論文「Rigging the Lottery: Making All Tickets Winners」ではRigLを紹介しています。
RigLは既存の密から疎へのトレーニング方法と比較して精度を犠牲にしません。パラメータ数と計算コストを固定して疎なニューラルネットワークをトレーニングする新しいアルゴリズムです。
RigLは、トレーニング中に活性化する必要があるニューロンを識別します。これにより、最適化プロセスが最も関連性の高い接続を利用する事が可能になり、粗密問題を改善できます。
これの例を以下に示します。MNISTを使った多層パーセプトロン(MLP:Multilayer Perceptron)ネットワークのトレーニング中に、RigLでトレーニングされた疎ネットワークは、文字が存在する画像中心部に焦点を合わせ、文字が存在しない外縁部の画素情報を破棄する事を学習します。
他の3つの比較対象手法(SET、SNFS、SNIP)とともに、RigLのTensorflow実装がgithub.com/google-research/riglで公開されています。
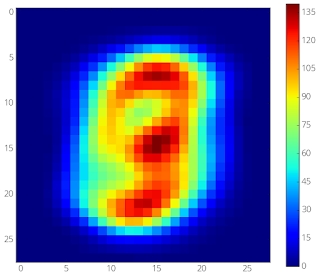
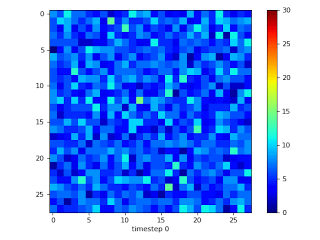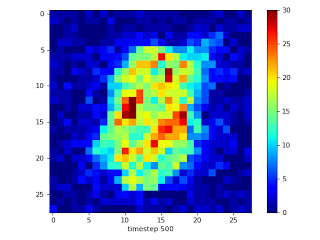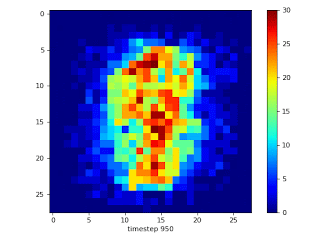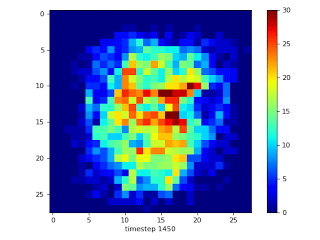
左:平均的なMNIST画像
右:MNISTを使って98%疎な2層MLPをトレーニングした際に接続が進化していく様子。トレーニングは、ランダムに疎にマスクする事から始まります。このマスクにより各入力画素に約6つの接続が残されます。周辺部を入力とする接続は意味のある勾配を示さないため、中央部の画素を入力とする有益な接続に置き換えられます。
3.RigL:ニューラルネットワークの冗長性を動的に最適化(1/3)関連リンク
1)ai.googleblog.com
Improving Sparse Training with RigL
2)proceedings.icml.cc
Rigging the Lottery:Making All Ticket Winners(PDF)
3)github.com
google-research/rigl
4)www.nature.com
Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science(SET)
5)arxiv.org
Sparse Networks from Scratch: Faster Training without Losing Performance(SNFS)
SNIP: Single-shot Network Pruning based on Connection Sensitivity

