
1.オフライン強化学習に関する楽観的な見解(1/2)まとめ
・ほとんどの強化学習は、エージェントが直接オンライン環境と対話するオンライン強化学習が前提
・オフライン強化学習はエージェントが収集済みデータにないアクションを実行した際の評価が困難
・しかしオフライン強化学習でもパフォーマンスの高いエージェントを実現できそうな事がわかった
2.オンライン強化学習とオフライン強化学習
以下、ai.googleblog.comより「An Optimistic Perspective on Offline Reinforcement Learning」の意訳です。元記事は2020年4月14日、Rishabh AgarwalさんとMohammad Norouziさんによる投稿です。
オフラインで学習を強化しているようにみえるアイキャッチ画像のクレジットはPhoto by Trent Szmolnik on Unsplash
2020年8月追記)関連記事の「オフライン強化学習における未解決の課題への取り組み」がアップされました。
オフポリシー学習の可能性は依然として魅力的であり、それを達成するための最良の方法はまだ謎に包まれています Sutton & Barto (Reinforcement Learningの著者)
ほとんどの強化学習(RL:Reinforcement Learning)アルゴリズムは、エージェントが自身の収集した経験から学ぶためにオンライン環境とアクティブに対話することを前提としています。
しかし、これらのアルゴリズムは、複雑な現実世界の問題(ロボット工学や自動運転など)に適用するのは困難です。
現実世界からデータを広く収集する事はサンプル効率が非常に悪く(訳注:例えば、現実のロボットを物理的に複数台用意して並行学習させる必要が出て来る事など)、意図しない動作を引き起こす可能性(訳注:例えば、突然ロボットが壊れてしまう事など)があります。現実の世界ではなくシミュレーション環境で動作させようとしても、現実世界にスムーズに学習結果を転移できるような忠実度の高いシミュレータを構築する事は容易ではありません。
ただし、多くのRLアプリケーションでは、過去に収集した相互作用データ、つまり環境とエージェントがヤリトリした記録が大量に存在し、それらを利用して強化学習を実現し、多様な過去の経験を組み込むことでより一般化性能を向上させる事ができます。
既存の相互作用データはオフライン強化学習により効果的に使用できます。完全オフポリシー強化学習では、エージェントは、固定した相互作用データ、つまり記録された過去の経験から、環境との追加の対話なしにトレーニングされます。
オフライン強化学習は以下のようにして役立てる事ができます。
(1)既存のデータを使用してRLエージェントを事前トレーニングします。
(2)収集済み相互作用データとのヤリトリに基づいて、RLアルゴリズムを経験的に評価します。
(3)現実世界に影響を与えます。
ただし、オフラインの強化学習は、「オンラインの相互作用」と「ログに記録された固定の相互作用」の間に分布の不一致が存在するために難しいと考えられています。つまり、「学習用エージェント」が「データ収集用エージェント」とは異なるアクションを実行した場合、それが失敗するか成功するかわからないため、どのような報酬を提供すべきかがわからないのです。
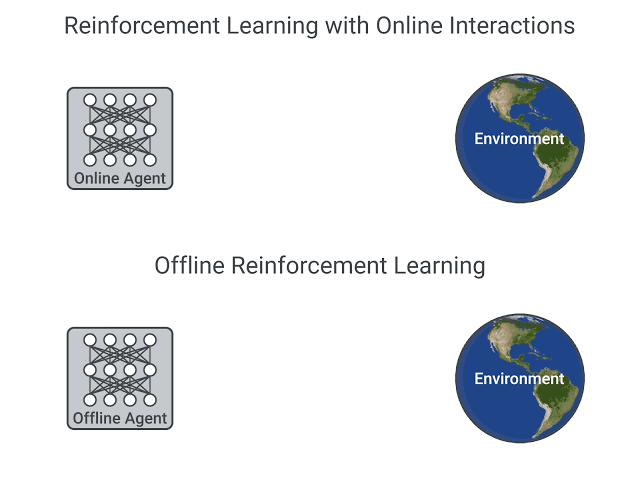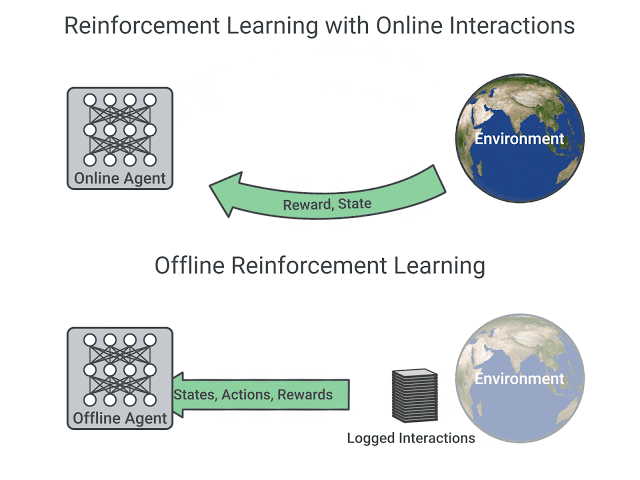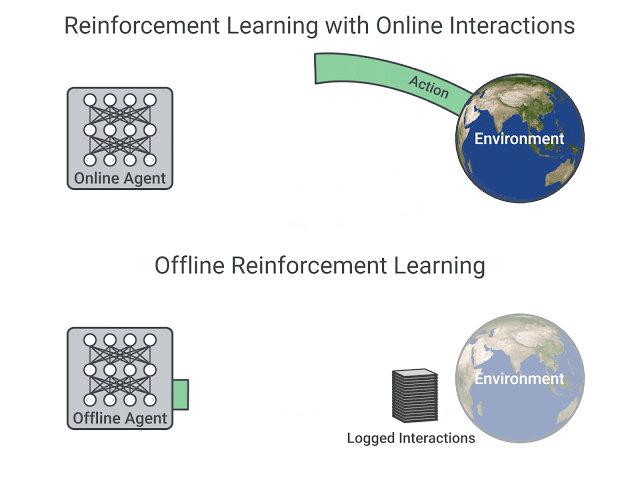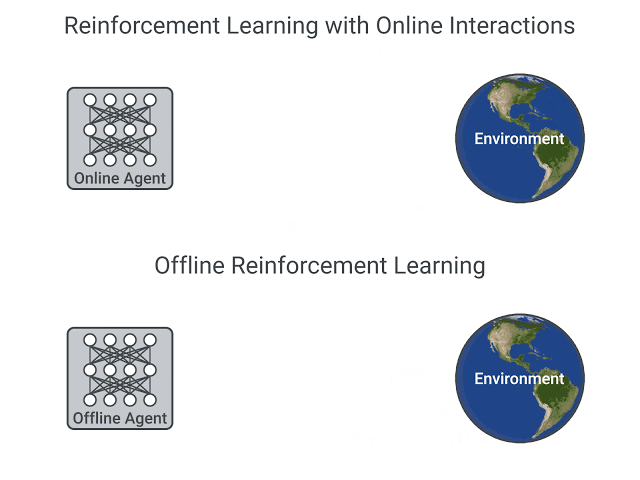
オンラインの相互作用を使用したRLとオフラインRLの比較
論文「An Optimistic Perspective on Offline RL」では、DQNエージェントのログに記録された経験に基づいて、Atari 2600ゲームをオフラインRLでプレイする簡単な実験を行っています。
この論文では分布の不一致を明示的に修正しなくても、標準的なオフポリシーRLアルゴリズムを使用して、データ収集エージェントよりもパフォーマンスの高いエージェントをトレーニングできることを示しています。
また、ランダムアンサンブル混合(REM:Random Ensemble Mixture)と呼ばれる堅牢なRLアルゴリズムを開発し、これが有望なオフラインRLアルゴリズムである事を示します。
結論として、十分に大きく多様なオフラインデータセットでトレーニングされた堅牢なRLアルゴリズムが高品質な動作につながり、新しいデータ駆動型RLパラダイムを強化できるという楽観的な見方を示します。
オフラインRLメソッドの開発と評価を容易にするために、DQN Replay Datasetも公開しており、コードをオープンソース化しています。 詳細については、offline-rl.github.ioをご覧ください。
オフポリシーRLおよびオフラインRL入門
以下に、強化学習の様々なアプローチをまとめます。
| – | 現在のエージェントが収集したデータのみを使う | 他のエージェントが収集したデータを使う |
| 現在のエージェントを使用してデータ収集を行う | オンライン、オンポリシー強化学習 | オンライン、オフポリシー強化学習 |
| 固定データセットを使用する(追加のデータ収集は行わない) | 実現不可 | オフライン(完全オフポリシー)強化学習 |
DQNなどのオンライン、オフポリシーRLエージェントは、ゲームに関する明確な知識なしにゲーム画面を観察するだけで、Atari 2600ゲームで人間レベルのパフォーマンスを実現します。
DQNは、達成可能な将来の最大の報酬(つまり、Q値)に関して、環境の特定状態における各アクションの有効性を推定します。更に、QR-DQNなどの最近の分布型RLエージェント(distributional RL agents)は、「各状態とアクションのペア」を単一の期待値として算出するのではなく、「予想される将来の報酬の分布全体」をモデル化しています。
DQNやQR-DQNなどのエージェントは、「ポリシーの最適化(特定の状態でのエージェントの動作)」と「そのポリシーを使用してより多くのデータを収集する事」を交互に行うため、「オンライン」と見なされます。
原則として、オフポリシーのRLエージェントは、最適化されているポリシーだけでなく、任意のポリシーによって収集されたデータから学習できます。
ただし、最近の研究では、オフライン強化学習に対する悲観的な見解が示されています。標準的なオフポリシーエージェントは発散してしまったり、もしくはパフォーマンスが低下してしまうという研究があるのです。
この悲観的な見解を訂正するために、以前の研究は、学習したポリシーを正規化する事で、オフラインの相互作用データセットから分布が離れすぎないようにする事を対策として提案しています。
3.オフライン強化学習に関する楽観的な見解(1/2)関連リンク
1)ai.googleblog.com
An Optimistic Perspective on Offline Reinforcement Learning
2)arxiv.org
An Optimistic Perspective on Offline Reinforcement Learning
3)offline-rl.github.io
An Optimistic Perspective on Offline Reinforcement Learning
4)console.cloud.google.com
atari-replay-datasets
5)incompleteideas.net
Reinforcement Learning: An Introduction second edition(PDF)

