
1.Deep Double Descent:ディープラーニングは二度、パフォーマンスが向上する(1/2)まとめ
・モデルサイズ、データサイズ、トレーニング時間を増加させるとパフォーマンスは向上し悪化し向上する
・この現象はCNN、ResNet、およびTransformerなどの最新モデルでも発生し二重降下現象と呼ばれる
・より多くのデータを使ったためにパフォーマンスが劣化してしまう可能性がある事を示唆している
2.Double Descentとは?
以下、openai.comより「Deep Double Descent」の意訳です。元記事は2019年12月3日、Preetum Nakkiranさん、Gal Kaplunさん、Yamini Bansalさん、Tristan Yangさん、Boaz Barakさん、Ilya Sutskeverによる投稿です。
要約
私達の研究は、CNN、ResNet、およびTransformerで二重降下現象(double descent phenomenon)が発生することを示しています。
モデルのサイズ、データのサイズ、またはトレーニング時間を増加させると、パフォーマンスは最初に向上しますが、次に悪化し、その後再び向上します。
この影響は、慎重に正則化を行う事により回避される事がよくあります。この振る舞いはかなり普遍的であるように見えますが、何故それが起こるのかはまだ完全には理解されておらず、この現象を更に研究する事は重要と考えています。
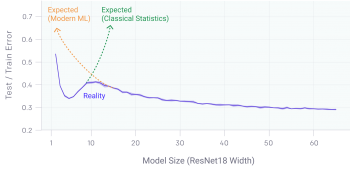
CNN、ResNet、トランスフォーマーなど、多くの最新の深層学習モデルは、早期停止(early stopping)または正則化を使用しない場合、従来より観察されている二重降下現象が現れます。
ピークは、モデルがトレーニングセットをかろうじて学習出来るパラメータサイズ「クリティカルレジーム(critical regime)」である時に予測可能に発生します。
ニューラルネットワークのパラメーターの数を増やすと、当初テストエラーは減少し、そして増加し、モデルが学習データに十分適合できるようなサイズになると、二度目のパフォーマンス向上が始まります。
モデルが大きすぎるのは良くないという従来の統計学の常識にも、モデルが大きいほど支持される現代の機械学習研究のパラダイムにも当て嵌まる事ではありません。
私達はエポック単位の学習、つまり学習データを分割して繰り返し学習させる際にも二重降下が発生する事を発見しました。この驚くべき発見は、二重降下現象によって、より多くのデータを使ったためにパフォーマンスが劣化してしまったり、より大きなエポック単位でディープラーニングを訓練した事によって、実際にはパフォーマンスが低下するような状況に陥る可能性がある事を示唆しています。
1.より大きなモデルになるほどパフォーマンスが悪くなる状況が存在します。
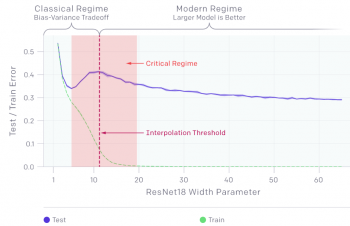
二重降下現象は、より多くのデータでトレーニングする事でモデルが劣化する状況に繋がる可能性があります。上のグラフでは、モデルが学習データにかろうじて適合する程度の大きさであった場合、テストエラーのピークは補間しきい値(interpolation threshold)付近で発生します。
全てのケースで、補間しきい値に影響する変更(最適化アルゴリズム、学習サンプルの数、ラベルノイズの量の変更など)は、テストエラーのピークの位置にも影響します。
二重降下現象は、ラベルノイズが追加された設定で最も顕著となります。この現象がないと、ピークは小さくなり、見逃しやすくなります。ラベルノイズを追加すると、二重降下が増幅され、簡単に調査できます。
3.Deep Double Descent:ディープラーニングは二度、パフォーマンスが向上する(1/2)まとめ
1)openai.com
Deep Double Descent
2)windowsontheory.org
Deep Double Descent (cross-posted on OpenAI blog)
