
1.オフライン強化学習における未解決の課題への取り組み(1/3)まとめ
・強化学習は医療など試行錯誤によるデータ収集が難しい現実世界には適用が難しい
・オフラインRLは実際に動かさなくても過去に収集されたデータを使って学習可能なため有望
・オフラインRLにはまだ課題が多いため現在の手法の能力を理解するためD4RLをリリース
2.D4RLとは?
以下、ai.googleblog.comより「Tackling Open Challenges in Offline Reinforcement Learning」の意訳です。元記事の投稿は2020年8月20日、George TuckerさんとSergey Levineさんによる投稿です。
未読だったら以下も読んでおいた方が良いです。
オフライン強化学習に関する楽観的な見解(1/2)
オフライン強化学習に関する楽観的な見解(2/2)
オフラインで保守的に学習を行っているように見えるアイキャッチ画像のクレジットはPhoto by Jilbert Ebrahimi on Unsplash
過去数年にわたって、ゲームプレイやロボット制御で注目を集めた成功に牽引され、強化学習(RL:Reinforcement Learning)への関心が高まっています。
ただし、一度収集した後は再利用可能な大量のデータセットから学習する教師あり学習とは異なり、RLアルゴリズムは試行錯誤を行うフィードバックループから学習します。このループは学習中にアクティブな相互作用を必要とし、新しいポリシーが学習される度にデータを収集を繰り返す必要があります。
このようなアプローチは、医療、自動運転、対話システムなど、試行錯誤によるデータ収集が大きなコスト、多大な時間、または無責任な態度と見なされる現実世界の多くの場面で禁止されています。一部のアクティブなデータ収集を容認できる環境でも、インタラクティブにデータを収集する必要があるため、データセットのサイズや多様性が制限されます。
オフラインRL(バッチRLまたは完全オフポリシーRLとも呼ばれます)は、以前に収集されたデータセットのみに依存し、それ以上の相互作用を必要としません。
意思決定を行うための戦略を自動的に学習するため、以前に収集したデータセット、例えば、過去のRL実験の記録、人間が行ったデモンストレーションの記録、または手動で設計された探索戦略の記録、などを利用する方法を提供します。
原則として、オフポリシーのRLアルゴリズムはオフライン設定で使用できますが(完全オフポリシー)、一般的には、環境とアクティブな相互作用を行える状況で使用した場合にのみ成功します。環境から直接フィードバックを受け取らないと、実際には望ましくないパフォーマンスを示すことがよくあるのです。
その結果、オフラインRLには非常に大きな可能性がありますが、重要なアルゴリズム上の課題を解決しない限り、その可能性に到達することはできません。
論文「Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems」では、オフラインRLの課題に取り組むためのアプローチに関する包括的なチュートリアルを提供し、残っている多くの問題について説明します。
これらの問題に対処するために、オープンソースのベンチマークフレームワークであるディープデータ駆動型強化学習用データセット(D4RL)を設計してリリースしました。また、保守的Qラーニング(CQL:Conservative Q-learning)と呼ばれる、新しくシンプルで非常に効果的なオフラインRLアルゴリズムも紹介します。
オフラインRLのベンチマーク
現在の手法の能力を理解し、将来の進歩を導くためには、まず効果的なベンチマークが必要です。
従来の研究で行われた一般的なやり方は、成功したオンラインRLの実行時に生成されたデータを単に流用することでした。ただし、このデータ収集アプローチは簡単ですが、人工的なものです。前述のように多くの現実世界の環境ではオンラインRLエージェントのトレーニングが禁止されていますが、そのような環境でのデータも含まれているからです。
ここで、タスクを適切にカバーしている多様なデータソースから、現在よりも優れたポリシーを学習したいと考えたとしましょう。例えば、手動設計されたロボットアーム制御システムからデータを収集し、オフラインRLを使用して、より優れた制御システムをトレーニングすることができるかもしれません。
現実世界の環境でこのような進歩を可能にするには、これらの環境設定を正確に反映し、且つ、迅速な実験を可能にするために十分にシンプルで利用可能な一連のベンチマークが必要です。
D4RL(Datasets for Deep Data-Driven Reinforcement Learning)は、標準化された環境、データセット、評価手順、およびこれを達成するのに役立つ最近のアルゴリズムの参照スコアを提供します。これは「バッテリー付き」のリソースであるため、誰でも簡単に、最低限の手間で始めることができます。
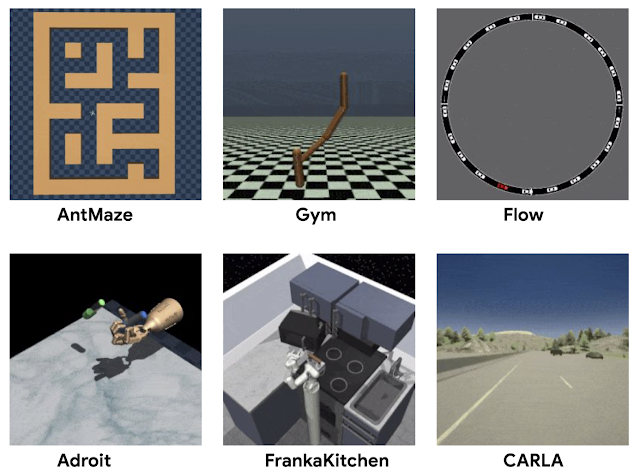
D4RLの環境
D4RLの主要な設計目標は、現実世界のデータセットとアプリケーションの両方の課題を反映するようなタスクを開発することでした。
従来のデータセットは、ランダムなエージェントまたはRLでトレーニングされたエージェントから収集されたデータを使用していました。
代わりに、自動運転、ロボット工学、その他の領域での潜在的なアプリケーションを検討することにより、現実世界のオフラインRLアプリケーションでどのようなデータを処理する必要があるかを検討しました。
人間が行ったデモのデータ、ハードコードされたコントローラーから生成されたデータ、異種のデータソースから収集されたデータ、及び、様々な異なる目標を持つエージェントによって収集されたデータなどです。
3.オフライン強化学習における未解決の課題への取り組み(1/3)関連リンク
1)ai.googleblog.com
Tackling Open Challenges in Offline Reinforcement Learning
2)sites.google.com
Datasets for Deep Data-Driven Reinforcement Learning
CONSERVATIVE Q-LEARNING FOR OFFLINE RL
3)arxiv.org
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Behavior Regularized Offline Reinforcement Learning
4)github.com
google-research / relay-policy-learning / adept_envs

