
1.Dreamer:長期視点で考える事が出来る強化学習(1/3)まとめ
・世界モデルを使用しない強化学習は学習に大量の試行錯誤と時間が必要なため実用性が制限される
・世界モデルを使用する強化学習もプランニングメカニズムがネックになり能力が制限されている
・既存モデルを改良し長期視点から最適な行動を学習出来る強化学習エージェントDreamerが発表
2.Dreamerとは?
以下、ai.googleblog.comより「Introducing Dreamer: Scalable Reinforcement Learning Using World Models」の意訳です。
元記事の投稿は2020年3月18日、Danijar Hafnerさんによる投稿です。
比較的簡単にイメージ画像が見つかる命名でありがたかったDreamerな赤ちゃんのアイキャッチ画像のクレジットはPhoto by Dakota Corbin on Unsplash
2021年2月追記)後続研究のDreamer V2が発表されています。
どのようすれば人工知能エージェントが目標を達成するためのアクションを自動で選択する事ができるようになるかについての研究は、主に強化学習(RL)により、急速な進歩を遂げています。試行錯誤によって成功するアクションを予測することを学習するモデルフリーな(世界モデルを使用しない)RLアプローチにより、DeepMindのDQNはAtariのゲームをプレイする事ができ、AlphaStarはStarcraft IIで世界チャンピオンを倒すことができましたが、実行環境と大量の相互作用を必要とするため(つまり、非常に時間がかかったりハードウェアが摩耗したりしてしまうため)、現実世界での実際の有用性は制限されています。
対照的に、(世界モデルを使用する)モデルベースのRLアプローチは、単純化された実行環境の世界モデルを学習します。この世界モデルにより、エージェントは一連のアクションの結果を潜在的に予測できるようになるため、仮想シナリオを介して新しい状況で十分な情報に基づいた決定を下すことができるので、目標を達成するために必要な試行錯誤を減らすことができます。
従来は、正確な世界モデルを学習し、それらを活用して成功する行動を学習することは困難でした。Deep Planning Network(PlaNet)などの最近の研究は、画像から正確な世界モデルを学習することでこれらの限界を押し広げましたが、モデルベースのアプローチは、非効率的または計算コストの高いプランニングメカニズムによって依然として抑制されており、困難なタスクを解決する能力が制限されています 。
本日、DeepMindと共同で、画像から世界モデルを学習し、それを使用して長期視点から考えて最適な行動を学習する事が出来るRLエージェントであるDreamerを紹介します。Dreamerは、その世界モデルを活用して、モデルの予測を逆伝播して行動を効率的に学習します。生の画像からコンパクトなモデルの状態を計算することを学習して、エージェントはたった1つのGPUで、数千の予測された行動を効率的に並列学習できます。Dreamerは、生の画像入力を与えられた20の連続制御タスクから構成されるベンチマークで、パフォーマンス、データ効率、および計算時間の短さで最先端のスコアを達成しました。RLのさらなる進歩を促進するために、ソースコードを研究コミュニティにリリースしています。
Dreamerの仕組み
Dreamerは、典型的なモデルベース手法の3つのプロセスで構成されています。世界モデルを学習し、世界モデルを使って行われた予測から行動を学習し、学習した行動を実行環境で実行して新しい経験を収集するのです。行動を学ぶために、Dreamerはバリューネットワークを使用して計画期間を超えた長期目線で報酬を考慮し、アクターネットワークを使用してアクションを効率的に計算します。この3つのプロセスは並行して実行可能で、エージェントが目標を達成するまで繰り返されます。
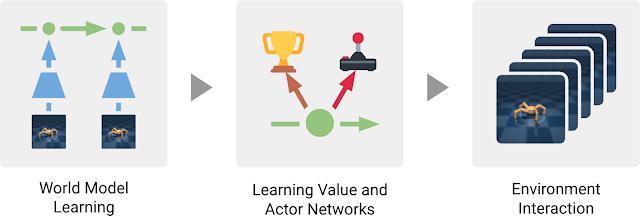
Dreamerエージェントの3つのプロセス。世界モデルは過去の経験から学習されます。このモデルの予測から、エージェントはバリューネットワークを学習して将来の報酬を予測し、アクターネットワークを学習してアクションを選択します。アクターネットワークは、環境と対話するために使用されます。
世界モデルを学ぶ
DreamerはPlaNetの世界モデルを活用します。PlaNet世界モデルは、ある画像から次の画像を直接予測するのではなく、入力画像から計算されるコンパクトな世界モデルに基づいて結果を予測します。
一連のコンパクトな世界モデルの状態を自動的に生成する事を学習し、これを使って物体の種類、物体の位置、物体とその周辺環境との相互作用など、将来の結果を予測するのに役立つ概念を取得します。
エージェントの過去の経験のデータセットから一連の画像、アクション、および報酬が与えられると、Dreamerは次のようにして世界モデルを学習します。
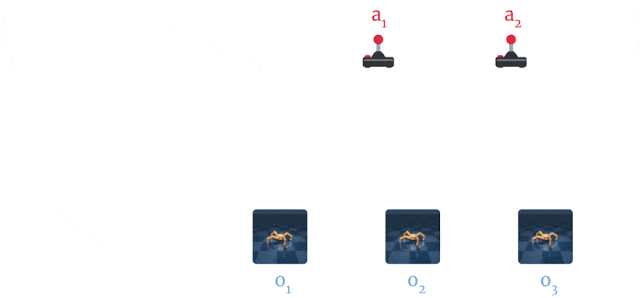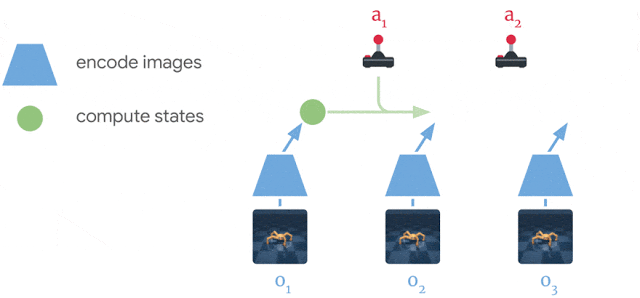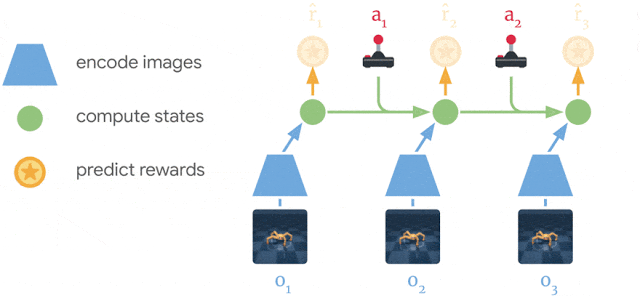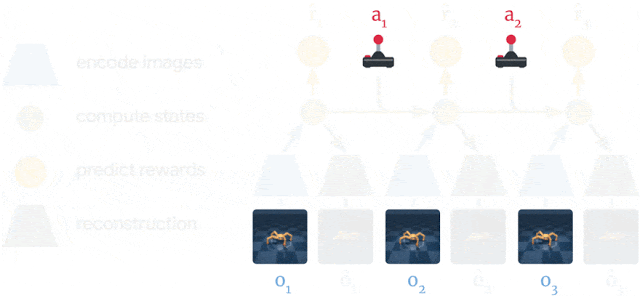
ドリーマーは経験から世界モデルを学びます。
過去の画像(o1–o3)とアクション(a1–a2)を使用して、一連のコンパクトなモデル状態(緑色の円)を計算し、そこから画像(ô1–ô3)を再構築し、報酬(r̂1–r̂3)を予測します。
3.Dreamer:長期視点で考える事が出来る強化学習(1/3)関連リンク
1)ai.googleblog.com
Introducing Dreamer: Scalable Reinforcement Learning Using World Models
2)github.com
google-research/dreamer

