
1.無限に続く行動履歴を学習可能な強化学習のオフポリシー評価(1/2)まとめ
・強化学習は広く使われているが過去の履歴データ、つまりオフポリシーで性能評価をする事は難しい
・履歴データを収集したエージェントと性能評価されるエージェントが異なるため行動の分布が異なるため
・重点サンプリングを利用して別の分布で生成されたサンプルから特定の分布の特性を推定する事で対処
2.Infinite-Horizon Reinforcement Learningとは?
以下、ai.googleblog.comより「Off-Policy Estimation for Infinite-Horizon Reinforcement Learning」の意訳です。元記事は2020年4月17日、Ali MousaviさんとLihong Liさんによる投稿です。
前回のオフライン強化学習のお話に続いて、今度はオフライン(つまり環境と対話せず)でオフポリシー(つまり、他のエージェントが蓄積した行動履歴)を元に、しかも無限に長く蓄積されている行動履歴を強化学習に学習させて、且つその性能を推定する事が出来るのか?というお話です。
Horizonは水平線とか地平線と訳される事が多いと思うのですが、そのイメージからInfinite Horizonなアイキャッチ画像のクレジットはフィリピンはボラカイ島のシャングリ・ラ ボラカイ リゾート&スパ、Photo by Sam Shin on Unsplashで、オフラインゴールデンウイーク気分をお届けします。
従来の強化学習(RL:Reinforcement Learning)設定では、エージェントは環境とオンラインで対話します。つまり、環境とのヤリトリからデータを収集し、次に、エージェントの動作を管理するポリシーにデータを通知してエージェントの動作を改善します。
対照的に、オフラインRLとは、過去の履歴データを使用して、環境内での行動に適したポリシーを学習したり、新しいポリシーのパフォーマンスを評価する事を意味します。
RLは、ロボット工学や推薦システムなどの現実世界の重要な問題にますます適用されているため、オフライン設定で新しいポリシーを評価する事は、より重要になります。
例えば、推薦システムであれば「過去の行動ポリシーに基づくアクションから生成された履歴データ(つまり顧客の購買履歴など)」が与えられ、「ターゲットとなるポリシーの予想報酬(つまり想定顧客による予想売上など)」を推定する事などが考えられます。
ただし、こういった重要性の高さにもかかわらず、履歴ポリシーに基づいてターゲットポリシーの全体的な有効性を評価する事は、忠実度の高いシミュレーターを構築する事の難しさや、データ分布の不一致のため、少々難しい場合があります。
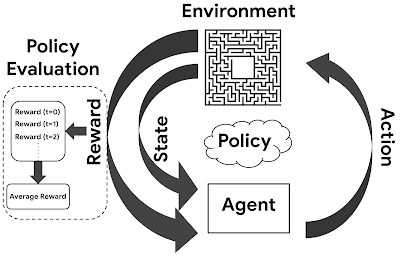
強化学習におけるエージェントと環境の相互作用の図
各ステップで、エージェントはポリシーに基づいてアクションを実行し、アクションの結果として報酬を受け取り、ポリシーを更新して新しい状態に移行します。
簡単な例として、ゲームPong(訳注:ピンポンを模した昔のビデオゲーム)を考えてみましょう。
以前の戦略(行動ポリシー:behavior policies)が収集した履歴データのみを使って、実際にゲームをプレイする事なしに新しい戦略(ターゲットポリシー:target policy)が勝つ可能性を高める事ができるかどうかを予測したい場合があります。
もし、行動ポリシー、つまり以前の戦略のパフォーマンスが高いか否かのみに興味がある場合、履歴データの全ての報酬を平均してみる事をお勧めします。
ただし、履歴データはターゲットポリシー(新しい戦略)ではなく、行動ポリシー(以前の戦略)によって決定されたアクションに基づいています。そのため、これはオフポリシーなデータであり、この単純な報酬の平均では、ターゲットポリシーが長期的にどのような報酬を得られるか適切に推定する事は出来ません。
適切な修正を行って、2つの異なるポリシー(つまり、データ分布の違い)によるバイアスを取り除く必要があります。
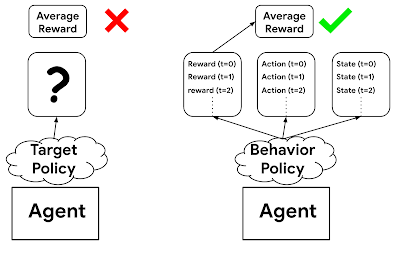
オフポリシーで評価する場合は、行動ポリシーとは異なり、ターゲットポリシーからフィードバックされるデータはありません。従って、行動ポリシーからの情報を使用せずに、ターゲットポリシーの期待報酬を計算することはできません。
ICLR 2020で承認された論文「Black-Box Off-Policy Estimation for Infinite-Horizon Reinforcement Learning」では、オフラインデータから特定のポリシーを評価する新しいアプローチを提案します。
このアプローチは、ターゲットポリシーの期待報酬をオフポリシーデータの報酬の加重平均として推定するアイディアに基づいています。
オフポリシーのデータから意味を持つ重みを学習する方法は今まで知られていないため、新しい学習方法を提案します。従来のほとんどの研究とは異なり、この手法は、非常に長期間、または無限に続く履歴データを使用する場合に特に適しています。
最後に、多くの古典的な制御タスク用ベンチマークを使用して、このアプローチの有効性を経験的に実証します。
背景
一般に、オフポリシーでの評価問題を解決する1つのアプローチは、エージェントと環境の相互作用を模倣するシミュレーターを構築し、シミュレーションを使ってターゲットポリシーを評価することです。
このアイデアは自然なものですが、多くの領域、特に人間とのやり取りを伴うものに対しては、忠実度の高いシミュレータを構築する事が非常に困難な場合があります。
別のアプローチは、ターゲットポリシーの平均報酬を推定するために、オフポリシーデータの報酬の加重平均を使用することです。このアプローチは、シミュレーターを使用するよりも堅牢です。何故なら、環境をシミュレーターとしてモデリングする際のように、過去履歴にない行動をエージェントがした際にどのように環境が反応すべきか仮定をする必要がないためです。
実際、このアプローチを使用したこれまでのほとんどの取り組みは、タイムステップの数(つまり、データの履歴の軌跡)が制限されている短い期間の問題であれば成功しています。
ただし、期間が長くなると、ほとんどの従来手法では、予測の分散が指数関数的に増加してしまう事が良くあります。
長期間問題を解決するための新しい解決策が必要であり、極端なケースである無限期間を扱う問題では更に必要性が高まります。
無限期間に対応する強化学習アプローチ
私たちのオフポリシー評価(OPE:Off-Policy Estimation)の方法は、重点サンプリング(Importance sampling) と呼ばれるよく知られた統計的手法を利用しており、これを使用すると、別の分布によって生成されたサンプルから特定の分布の特性(たとえば、平均)を推定できます。
具体的には、行動ポリシーによるデータからの報酬の加重平均を使用して、ターゲットポリシーの長期的な平均報酬を推定します。このアプローチの難しい部分は、オフポリシーデータの分布とターゲットポリシーのデータ分布の間のバイアスを取り除くための重みを選択する方法です。ターゲットポリシーの平均報酬の推定を最大精度にしつつこれを達成しなければなりません。
重要なポイントは、もし、重みが正で合計が1になるようになるように正規化できた場合、そこからエージェントの可能な状態とアクションのセットに対する確率分布を定義できる事です。
一方、個々のポリシーは、エージェントが特定の状態になる頻度または特定のアクションを実行する頻度の分布を定義します。言い換えれば、状態とアクションの一意の分布を定義します。合理的な仮定の下では、この分布は時間とともに変化しないため、定常分布(stationary distribution)と呼ばれます。
私達は重点サンプリングを使用するため、当然ながら、ターゲットポリシーの定常分布が推定器の重みによって求められた分布と一致するように、推定器の重みを最適化したいと考えます。
ただし、対象のポリシーによって生成されたデータがないため、ターゲットポリシーの定常分布がわからないという問題が残っています。
3.無限に続く行動履歴を学習可能な強化学習のオフポリシー評価(1/2)関連リンク
1)ai.googleblog.com
Off-Policy Estimation for Infinite-Horizon Reinforcement Learning
2)openreview.net
BLACK-BOX OFF-POLICY ESTIMATION FOR INFINITE-HORIZON REINFORCEMENT LEARNING(PDF)


コメント