
1.DADS:教師なしで有用なスキルを発見する強化学習(1/2)まとめ
・教師有り強化学習はシミュレーション環境を飛び出して現実世界の複雑な動作を学習できるようになった
・しかし、様々なタスク用に報酬関数を手動で設計する必要がありこれがボトルネックとなっている
・DADSは有用な行動、つまりスキルを見つけてそれを強化する事を教師無しで行う事で制限を回避
2.DADSとは?
以下、ai.googleblog.comより「DADS: Unsupervised Reinforcement Learning for Skill Discovery」の意訳です。元記事の投稿は2020年5月29日、Archit Sharmaさんによる投稿です。
強化学習では、ロボット/人工知能エージェントが「望ましい行動」をした時に報酬を与える事で、エージェントが「望ましい行動」を選択する性質を強化していきます。
報酬の内容や与える条件は、報酬関数で設定するのですが、報酬関数は「望ましい行動」に合わせて人間が手動で設計する必要があり、これが手間のかかる作業となります。
例えば、人工知能にビデオゲームをプレイさせるのでしたら、実行環境、すなわちゲームが提供するスコアを使って「スコアがアップする行動を取ったら報酬を与える」という形で報酬関数を設定できますが、「迷路を解く」事をお題にした場合に「望ましい行動」とは何でしょう?
位置的にゴールに近づいていたとしても袋小路にハマっているだけかもしれないので、やみくもにゴール方面に向かおうとする行動に報酬を与えるわけにもいかず、どんな行動に報酬を与えるべきなのかが曖昧です(曖昧な報酬問題)、ゴールに到達した時だけに報酬を与えるとしたら過程には一切「望ましい行動」がない事になってしまい、エージェントに「望ましい行動」に関するヒントを与える事ができません(疎な報酬問題)。
今回は、こういった難しい報酬関数の設計を人間が設計するのではなく、エージェントの行動の中から「望ましい動き=スキル」を教師なし学習で発見し、発見したスキルを組み合わせる事で有用な行動が実現が出来るのではないかという、教師なし学習による強化学習アプローチを探っていくお話です。
アイキャッチ画像はSkill trainingで画像を探していたら筋トレ画像が大量に出てきて、え~、筋トレもSkillになるの?とネイティブとの感覚の違いを痛感していた時に出てきてくれたベストマッチに思えたスキル画像で、クレジットはPhoto by Andrea Lightfoot on Unsplash
最近の研究では、教師有り強化学習(RL:Reinforcement Learning)がシミュレーション環境を想定したシナリオだけで動作するのではなく、様々な形状の物体を掴んだり、俊敏に歩行する事など、現実世界の複雑な動作を学習できる事が示されています。
ただし、複雑な動作を実行するようにエージェントを学習させる際の制限も明らかになりつつあります。それぞれのタスクに適切に設計した固有の報酬関数を用意する必要があるのです。
報酬関数を設計するためには、技術者による多大なエンジニアリング作業が必要になる可能性があり、これでは多数のタスクに対応する事できなくなります。
多くの現実世界のシナリオでは、報酬関数の設計は複雑になる可能性があります。例えば、追加の機器(ドアの向きを検出するセンサーなど)が必要になったり、その機器を用いて達成する「追加の目標」を手動でラベル付けする事が必要になります。
複雑な動作を実現する能力が、この報酬関数のエンジニアリング作業で制限されている事を考えると、エンジニアリング作業の自動化に繋がる教師なし強化学習はRLの興味深い方向性です。
教師有りのRLでは、外的な報酬関数(extrinsic reward function)がエージェントを望ましい行動に導き、環境内で望ましい変化をもたらすアクションを選択するように強化します。
教師無しのRLでは、内的な報酬関数(intrinsic reward function)が独自のトレーニング信号を生成し、タスクにとらわれない幅広い動作セットを取得します。
訳注:内的な報酬関数の例としては、人間における好奇心のように環境内で目新しい事を試す事を促す関数。これにより、迷路などで同じ道を何度も行き来するような行動が抑制されます。
内的な報酬関数は、エンジニアリングが必要な外的な報酬関数の問題を回避できますが、一般的であり、追加の設計なしに複数のエージェントおよび問題に広く適用できます。
近年、多くの研究が教師なし強化学習へのさまざまなアプローチに焦点を当てていますが、それは依然として非常に制約が厳しい問題です。
環境から報酬に関する案内がないと、役に立つ行動を学ぶのは難しいかもしれません。エージェントと環境の相互作用の中に、エージェントのより良い行動(スキル)を発見するために役立つ、意味を持つ性質は存在しないのでしょうか?
本投稿では、スキルを発見するための新しい教師なしRLメソッドを開発する2つの最近の論文を紹介します。
論文「Dynamics-Aware Unsupervised Discovery of Skills(DADS)」では、教師なし学習の最適化目標に「予測可能性(predictability)」の概念を導入します。
この研究では、「スキルが持つ基本的な性質」は「予測可能な環境の変化をもたらす事」であると私たちは考えています。
私達は、教師なしのスキル発見アルゴリズムでこのアイデアを調査し、シミュレーション環境内で様々なロボットを使う場面で適用可能である事を示しています。
これに続く研究「Emergent Real-World Robotic Skills via Unsupervised Off-Policy Reinforcement Learning」では、DADSのサンプル効率を改善して、教師なしでスキルを発見する事が現実世界で実行可能であることを示しています。

左側のロボットの動きはランダムで予測不可能ですが、右側の動きは、環境内で予測可能な変化を行う体系的な動きを示しています。私達の目標は、報酬関数を設計する事なしに、右側のような潜在的に有用な行動を学ぶことです。
DADSの概要
DADSでは「予測可能な(predictable)」スキルと「多様な(diverse)」スキルの発見を促進する固有の報酬関数を設計します。
以下の条件を満たすときに内的報酬関数は高い報酬を与えます。
(a)環境の変化がスキル毎に異なる(多様性の促進)
(b)特定のスキルによる環境の変化が予測可能(予測可能性の促進)
DADSは環境から報酬を取得しないので、スキルを多様化するように最適化すると、エージェントは潜在的に有用な行動をできるだけ多く身に付ける事ができます。
スキルが予測可能かどうかを判断するために、スキルダイナミクスネットワーク(skill-dynamics network)と呼ばれる別のニューラルネットワークをトレーニングして、現在の状態と実行中のスキルが与えられた場合の環境状態の変化を予測します。
スキルダイナミクスネットワークが環境の状態変化を予測できるほど、スキルは「予測可能」になります。
DADSによって定義される内的報酬は、従来の強化学習アルゴリズムを使用して最大化する事ができます。
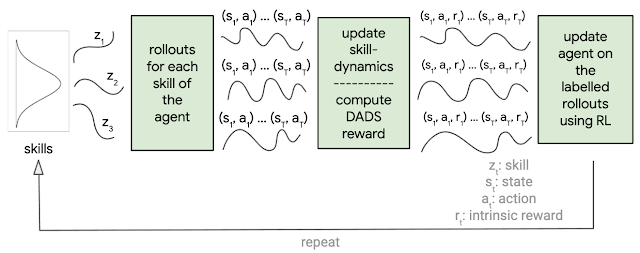
DADSの概要
3.DADS:教師なしで有用なスキルを発見する強化学習(1/2)関連リンク
1)ai.googleblog.com
DADS: Unsupervised Reinforcement Learning for Skill Discovery
2)arxiv.org
Dynamics-Aware Unsupervised Discovery of Skills
Emergent Real-World Robotic Skills via Unsupervised Off-Policy Reinforcement Learning
3)sites.google.com
Dynamics-Aware Discovery of Skills


コメント