
1.SimCLR:対照学習により自己教師学習の性能を向上
・同じ画像同士の特徴量を最大化しつつ違う画像同士の特徴量を最小化する事を対照学習という
・SimCLRは自己教師および半教師でありながら対照学習により教師あり学習に迫るスコアを達成
・対照学習ではデータ水増しを行うがランダムな切り抜きとランダムな色ズレの組み合わせが有効
2.SimCLRとは?
以下、ai.googleblog.comより「Advancing Self-Supervised and Semi-Supervised Learning with SimCLR」の意訳です。元記事の投稿は2020年4月8日、Ting ChenさんとGeoffrey Hintonさん(ホントか!?)による投稿です。
写真のCrop(切り抜き)が重要と言う事で、Crop(作物)の写真をCrop(切り抜き)しているように見えるアイキャッチ画像のクレジットはPhoto by Mickael Tournier on Unsplash
2020年8月追記)後続研究として「対照学習で最良のビューを選択するための原則(1/2)」が発表されています。
2020年10月追記)比較対象として「Image GPT:自然言語処理用の人工知能で画像を生成(1/3)」も読んでおくと良いと思います。
2021年6月追記)後続研究として「SupCon:対照学習を教師有り学習に拡張」が発表されています。
近年、BERTやT5などの自然言語処理モデルにより、最初に大きなラベルなしデータセットを使って事前トレーニングし、次に小さなラベル付きデータセットで微調整することにより、良好な結果を達成できることが示されました。
同様に、Exemplar-CNN、Instance Discrimination、CPC、AMDIM、CMC、MoCoなどで実証されているように、ラベルのない大きな画像データセットで事前トレーニングを行うと、コンピュータービジョンタスクのパフォーマンスが向上する可能性があります。
これらの手法は、自己教師学習の範疇に入ります。
つまり、ラベルなしデータセットから代替ラベルを作成することにより、教師なし学習問題を教師あり学習問題に変換する一連の手法と考える事ができます。
ただし、従来の画像データを用いた自己教師学習手法は複雑であり、アーキテクチャやトレーニング手順に大幅な変更を加える必要があり、広く採用されることはありませんでした。
論文「A Simple Framework for Contrastive Learning of Visual Representations」では、画像を扱う自己教師付き特徴表現学習を「簡素化」するだけでなく、改善する方法についても概説しています。
SimCLRと呼ばれる私達が提案するフレームワークは、自己教師および半教師であり最先端の学習テクニックを大幅に進歩させ、限られた量のラベル付きデータで画像分類の最先端のスコアを達成します(ImageNetの1%のラベル付きデータを使用して85.8%のtop-5 accuracyを達成)
私達のアプローチの「簡素化」とは、既存の教師あり学習のパイプラインに簡単に組み込みできる事を意味します。以下では、まずSimCLRフレームワークを紹介し、次にSimCLRの開発中に発見した3つのことについて説明します。
SimCLRフレームワーク
SimCLRは、最初にラベルのないデータセットの画像から「一般的な特徴表現(generic representations of images)」を学習し、次に少量のラベル付き画像で微調整して、特定の分類タスクで優れたパフォーマンスを実現できます。
一般的な特徴表現は、「同じ画像に異なる変換をした画像同士を一致させる特徴量」を最大化しつつ、「違う画像に異なる変換をした画像同士を一致させる特徴量」を最小化すると言う対照的な目標を学習させる事によって達成されます。これは、対照学習(contrastive learning)と呼ばれる手法です。
この対照的な目標を使用してニューラルネットワークのパラメーターを更新すると、同じ画像の特徴表現が互いに「引き付け」られ、違う画像の特徴表現が互いに「反発」します。
これを行うために、まず、SimCLRは元のデータセットからサンプルをランダムに抽出し、単純な変換(ランダムに切り抜く、ランダムに色ズレさせる、ガウシアンぼかし効果を加える)を組み合わせて各サンプルを2回変換し、同じ画像からの2つの異なるビューを作成します。
個々の画像にこれらの単純な変換を行う理論的根拠は、
(1)同じ画像があれば変換後であっても「一貫している特徴表現」を得たいということです。
(2)事前トレーニングデータにはラベルがないため、どの画像にどの物体が含まれているかを事前に知ることはできません。
(3)これらの単純な変換は、ニューラルネットが適切な特徴表現を学習するのに十分であることがわかりました。しかし、より高度なデータ水増しポリシーを組み込むこともできます。
SimCLRは、ResNetアーキテクチャに基づく畳み込みニューラルネットワークの一種を使用して画像特徴表現を計算します。その後、SimCLRはfully-connected network(つまり、MLP、Multi Layer Perceptron)を使用して画像特徴表現の非線形投影を計算します。これにより、変換前後で不変な特徴が増幅され、ネットワークが同じ画像の異なる変換を識別する能力が最大化されます。
対照的な目標を達成するように損失関数を最小化するために、確率的勾配降下法を使用してCNNとMLPの両方を更新します。ラベルなしの画像で事前トレーニングを行った後、CNNの出力を画像の特徴表現として直接使用したり、ラベル付きの画像で微調整して、下流タスクのパフォーマンスを向上させることができます。

SimCLRフレームワークの概要
CNNレイヤーとMLPレイヤーは同時にトレーニングされて、同じ画像であれば変換バージョンであっても類似した投影を生成します。仮に画像が同じクラスに分類される物体、例えば、犬と犬の写真であっても、異なる画像であるならば類似しません。
訓練されたモデルは、同じ画像の異なる変換を特定するだけでなく、類似する概念(例えば「椅子」 vs 「犬」)の特徴表現も学習します。これは、後で微調整によってラベルに関連付けることができます。
SimCLRのパフォーマンス
そのシンプルさにもかかわらず、SimCLRは、ImageNetでの自己教師および半教師学習における最先端のテクニックを大幅に進歩させます。
SimCLRの自己教師学習によってされた特徴表現の上でトレーニングされた線形分類子は、76.5%/93.2%のtop-1/top-5 accuracyを達成します。
次の図に示すように、これは従来のベストモデル(CPC v2)の71.5%/90.1%と比較して、ResNet-50、つまり、より小さい教師あり学習モデルのパフォーマンスに迫っています。
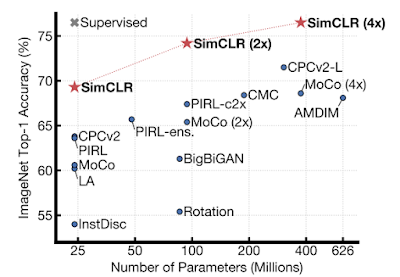
(ImageNetで事前トレーニングされた)様々な自己教師メソッドで学習された特徴表現でトレーニングされた線形分類子のImageNetのtop-1 accuracy。
左上の灰色の×印は教師あり学習によるResNet-50を表しています。
ラベル付きデータの1%分だけを使って微調整すると、SimCLRは63.0%/85.8%のtop-1/top-5の精度を達成します。これに対して、従来の最高モデル(CPC v2)は52.7%/77.9%です。おそらく驚くべきことに、全ラベル、つまり100%のラベルデーアで微調整した場合、事前トレーニング済みのSimCLRモデルは、比較対象としたゼロからトレーニングした教師付き学習モデルよりもはるかに優れたパフォーマンスを発揮できます。
例えば、SimCLRの事前トレーニング済みResNet-50(4x)を微調整すると、30回の学習で80.1%のtop-1 accuracyが達成されますが、ゼロからトレーニングすると90回の学習でも78.4%にしかなりません。
対照学習による特徴表現を理解する
以前の手法よりもSimCLRが改善できた理由は、単一の設計改良によるものではなく、幾つかの組み合わせによるものです。いくつかの重要な調査結果を以下に要約します。
発見1:
対応するビューを生成するために使用する画像変換の組み合わせは重要です。
SimCLRは、同じ画像の異なるビューが一致するような特徴表現を最大化する事を学習します。カラーヒストグラムの一致など、わずかな形の一致を捉えてしまう事を防ぐために適用する画像変換を慎重に構成することが重要です。これをよりよく理解するために、下の図に示すように、さまざまなタイプの変換を調査しました。
![]()
元の画像に適用されたランダム変換の例
最適な特徴表現を生成するためには、(私達の調査した限り)単一の変換では不十分ですが、「ランダムな切り抜き(random cropping)」と「ランダムな色ズレ(random color distortion)」という2つの変換が際立っていることがわかりました。
切り抜きも色ズレもそれだけでは高いパフォーマンスに繋がりませんが、これらの2つの変換を組み合わせることで最先端の結果が得られます。
ランダムな切り抜きとランダムな色ズレを組み合わせる事が重要である理由を理解するには、同じ画像の2つの切り抜き間で特徴表現の一致を最大化する作業を考えてみてください。この作業を行うためには、効果的な特徴表現学習を可能にする2種類の予測タスクが自然と必要になります。
(a)より大きな「グローバルビュー」から「ローカルビュー」を予測する。下図の切り抜きBから切り抜きA。
(b)近接するビューを予測する。例えば、切り抜きCと切り抜きDの間の部分。
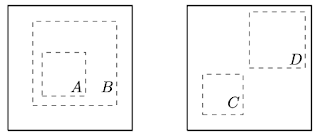
異なる切り抜き間で特徴表現の一致を最大化するためには、2つの予測タスクが発生します。
左:グローバルビューとローカルビュー
右:近接するビュー。
ただし、同じ画像の異なる切り抜きは、通常、色合いが非常に似ています。色をそのままにしておくと、モデルは色のヒストグラムを手がかりにするだけで切り抜き間で特徴表現の一致を最大化できてしまいます。
この場合、モデルは色のみに焦点を当て、他のより一般化可能な機能を無視する可能性があります。
各切り抜きの色を個別に歪めることにより、これらの浅い手がかりを削除することができ、モデルは、有用で一般化可能な特徴表現を学習することによってのみ特徴表現の一致の最大化を達成できます。
発見2:非線形な投影が重要です。
SimCLRでは、MLPベースの非線形投影を対照学習の損失関数が計算される前に適用されます。これは、各入力画像で不変の特徴を識別し、ネットワークが同じ画像の異なる変換を識別する能力を最大化するために役立ちます。
私達の実験では、このような非線形投影を使用すると特徴表現の品質が向上し、SimCLRで学習された特徴表現でトレーニングされた線形分類器のパフォーマンスが10%以上向上することがわかりました。
興味深いことに、「MLP投影モジュールの入力として使用される特徴表現」と「投影から出力される特徴表現」を、線形分類器で比較測定すると、前者の特徴表現をつかった方がパフォーマンスが向上することがわかります。
対照学習の損失関数は投影後の特徴表現を使っているため、投影前の特徴表現の方が優れている事は多少意外です。
推測すると、私達の目的は、ネットワークの最終層で、下流のタスクに役立つ可能性のある色などの特徴に惑わされないようにする事です。追加の非線形投影により、特徴レイヤーは画像に関するより有用な情報のみを保持するようにできます。
発見3:スケールアップすると、パフォーマンスが大幅に向上します。
(1)同じバッチでより多くの例を処理する
(2)より大きなネットワークを使用する
(3)より長くトレーニングする
事が、大幅な改善につながることがわかりました。
これらはいくぶん当たり前の事のように思えるかもしれませんが、これらの改善効果は教師あり学習よりもSimCLRの方が大きくなるように見えます。
例えば、教師あり学習ResNetのパフォーマンスは(ImageNet)で90から300のトレーニング回数の間でピークに達しましたが、SimCLRは800回のトレーニングの後でも改善を続けることができます。
また、ネットワークの深さまたは幅を増やす場合にも当てはまります。SimCLRの性能向上は継続しますが、教師あり学習では飽和し始めます。トレーニングのスケールアップのリターンを最適化するために、実験ではCloud TPUを広範囲に使用しました。
訳注:少なくとも発見3は教師あり学習と自己教師学習の違いではなくDeep Double Descent現象ではないかなと思います。
コードと事前学習済みモデル
自己教師学習と半教師学習の研究を加速するために、SimCLRのコードと事前トレーニング済みモデルをより大きな学術コミュニティと共有できることを嬉しく思います。
これらは、GitHubリポジトリで公開されています。
謝辞
これは、Simon KornblithとMohammad Norouziとの共同研究です。SimCLRフレームワークを視覚化してくれたTom Smallに感謝します。トロントなどのGoogleリサーチチームからの全般的なサポートにも感謝しています。
3.SimCLR:対照学習により自己教師学習の性能を向上関連リンク
1)ai.googleblog.com
Advancing Self-Supervised and Semi-Supervised Learning with SimCLR
2)arxiv.org
A Simple Framework for Contrastive Learning of Visual Representations
3)github.com
google-research / simclr

