
1.SEED RLによる大規模強化学習(1/3)まとめ
・強化学習手法は単純なゲームでも学習するために更に多くのトレーニングが必要になってきている
・SEED RLは、数千のマシン上で規模を拡大して実行できる新しい強化学習エージェント
・推論の集中化し、高速通信レイヤーを導入し、大規模なアクセラレータ(GPUまたはTPU)を利用する事で、新しいアーキテクチャーによって実現
2.SEED RLとは?
以下、ai.googleblog.comより「Massively Scaling Reinforcement Learning with SEED RL」の意訳です。元記事の投稿は2020年3月23日、Lasse Espeholtさんによる投稿です。何となく強化学習のアクターっぽい雰囲気が感じられるアイキャッチ画像のクレジットはPhoto by Kyle Head on Unsplash
強化学習(RL)は、碁やDota2などのゲームプレイにおける最近の成功が証明するように、過去数年間で印象的な進歩を遂げています。
人工知能モデル、言い換えればエージェントは、ゲームなどの環境を探索しながら、指定された目標に合わせて最適化しながら学習します。
ただし、現在のRL手法では、単純なゲームでも正常に学習するために、更に多くのトレーニングが必要になってきています。
これにより、何度も反復するような研究や、製品のアイデアを試す事が計算上高価で時間のかかる事になってしまっていいます。
論文「SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference」では、数千のマシン上で規模を拡大して実行できるRLエージェントを提示しています。これにより、毎秒数百万フレームでトレーニングを実行でき、計算効率が大幅に向上します。
これは、モデルの推論を集中化し、高速通信レイヤーを導入する事で実現可能になった大規模にアクセラレータ(GPUまたはTPU)を利用する事がかので、新しいアーキテクチャーによって実現されています。
Google Research Football、Arcade Learning Environment、DeepMind Labなどの人気のあるRLベンチマークをSEED RLを使って実行したパフォーマンスを示し、より大きなモデルを使用することでデータ効率が向上することも示しています。コードは、GPUを使用してGoogle Cloudで実行するための例とともに、Githubでオープンソースとして公開されています。
現在の分散アーキテクチャ
IMPALAなどの前世代の分散型強化学習エージェントは、数値計算に特化したアクセラレータを使用して、教師あり学習や教師なし学習が長年にわたって恩恵を受けてきた速度と効率を利用しました。
RLエージェントのアーキテクチャは通常、アクター(actor:役者)とラーンナー(learner:学習者)に分かれています。アクターは通常、CPUで実行され、環境内で処理を逐次実行する事と、モデルで推論を実行する事を繰り返し、次のアクションを予測します。多くの場合、アクターは推論モデルのパラメーターを更新し、十分な量の観測を収集した後、観測とアクションの軌跡をラーンナーに送信し、ラーンナーがモデルを最適化します。
このアーキテクチャでは、ラーンナーは、数百台のマシン上の分散推論からの入力を使用して、GPUでモデルをトレーニングします。
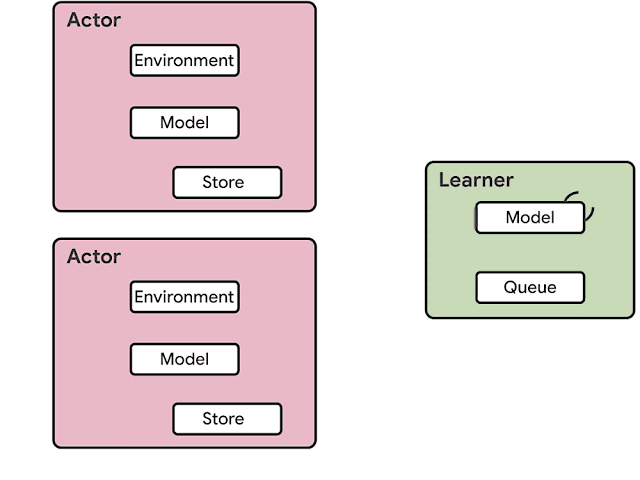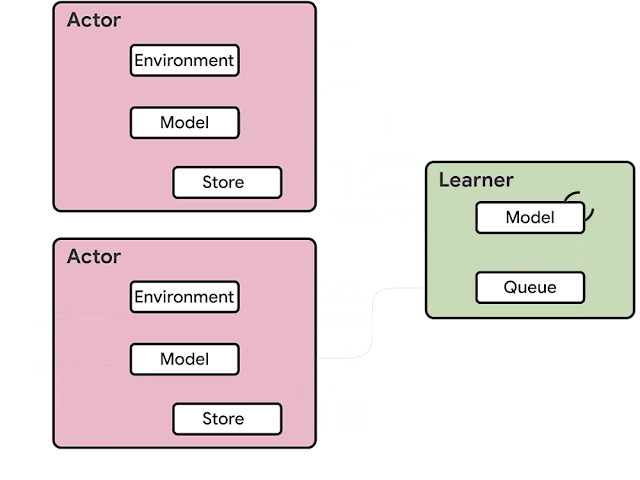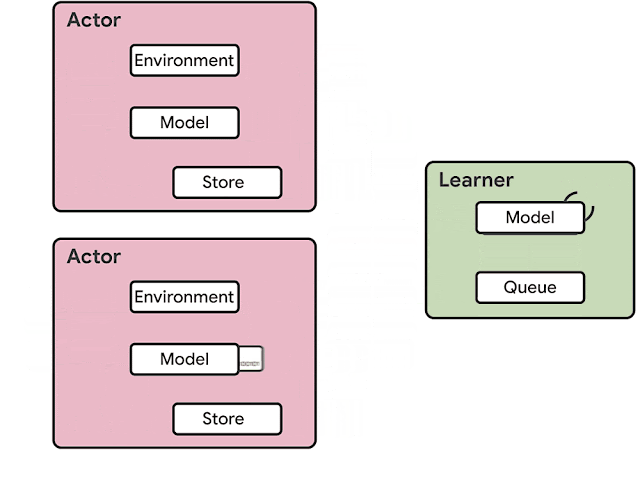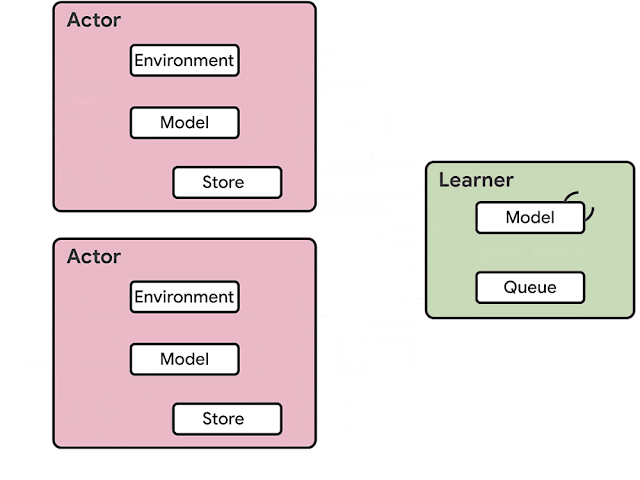
前世代のRLエージェントであるIMPALAのアーキテクチャの例。 推論はアクターで行われ、通常は非効率的なCPUを使用します。更新されたモデルパラメータは、ラーンナーからアクターに頻繁に送信されるため、必要なネットワークの帯域も増加します。
3.SEED RLによる大規模強化学習(1/3)関連リンク
1)ai.googleblog.com
Massively Scaling Reinforcement Learning with SEED RL
2)arxiv.org
SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
3)github.com
google-research/seed_rl
4)openreview.net
Recurrent Experience Replay in Distributed Reinforcement Learning
