
1.2022年のGoogleのAI研究の成果と今後の展望~言語・視覚・生成モデル編~(1/5)まとめ
・年初恒例のGoogle AI TopのJeff DeanによるGoogleの人工知能関連研究の2022年の振返と今年の展望
・今年はシリーズものとして全11カテゴリをわけて連続投稿するとの事で初回は言語モデルから
・意識を持っているかもしれないとニュースになったあのLaMDAも実用化に向けて前進しているとの事
2.Google AIの2022年の振り返り~言語モデル編~
以下、ai.googleblog.comより「Google Research, 2022 & Beyond: Language, Vision and Generative Models」の意訳です。元記事の投稿は2023年1月18日、Google AIのトップのJeff DeanがGoogle Research communityを代表しての執筆です。
毎年、年初恒例のJeff DeanによるGoogleの人工知能関連研究の去年の振り返りと今年以降の展望の記事です。待ってました、やっときたか!という感じですが、毎年、超長文記事になる傾向がありますが、去年はあまりに分野が膨大で多岐に渡り、まとめるのが難しかったのか文章量も減ってたんですよね。
「今年はどうかな?」と早速、文章量をチェックしてみたところ、更に減っていたので「やっぱり、忙しいのかなぁ」と思ったら冒頭に「今年はシリーズものとして連続で投稿するから!」という事で全11カテゴリ、前年比3倍くらいの文章量になりそうですが、初回は言語モデルからです。どうやら今年はあのLaMDAが遂に姿を現してくれそうです。
アイキャッチ画像はやや時期が遅くなってしまいましたが、お正月に本投稿のためにstable diffusion 1.5から派生したマージモデルであるProtoGenを更に微調整して生成したイラスト。作成した当時は素晴らしい出来に思えたのですが、既に前世代の品質に見えてしまうのがイラスト生成AIの進化の速さです。
私は、人々が自分の周りの世界をよりよく理解するのに役立つコンピュータに、常に関心を持ってきました。この10年間、Googleで行われた研究の多くは、同じようなビジョンを追求するものでした。
私たちは、人と協力してさまざまなタスクを達成する、より高性能なマシンを作りたいと考えています。
あらゆる種類のタスクです。複雑で、情報を探す事を必要とするタスク。音楽を創る、新しい絵を描く、ビデオを作るなどのクリエイティブなタスク。数行のガイダンスから新しい文書や電子メールを作成したり、人と協力してソフトウェアを共同で作成したりするような分析・合成タスク。
私達は複雑な数学的、科学的問題を解決したいのです。
情報を伝達する信号を変換し、世界の情報をあらゆる言語に翻訳する。複雑な病気を診断したり、物理的な世界を理解する。仮想的なソフトウェアの世界と物理的なロボティクスの世界の両方で、複雑な多段階の動作を実現する。
私達は、これらの機能の一部の初期バージョンを研究成果物で実証しました。また、Google 社内の多くのチームと協力し、何十億ものユーザーの生活に密着した Google の製品にこれらの機能の一部を搭載しています。しかし、この旅の最もエキサイティングな側面は、まだ先にあります。
この投稿で、Google 全体の研究者が 2022 年に達成したエキサイティングな進展を紹介し、2023 年以降のビジョンを提示するシリーズを開始する予定です。
まず、言語、コンピュータービジョン、マルチモーダルモデル、生成型の機械学習モデルについて説明します。その後数週間にわたり、責任あるAI(responsible AI)からアルゴリズム、コンピュータシステム、科学、健康、ロボティクスに至る研究テーマにおける斬新な展開について議論していきます。さあ、はじめましょう!
| 言語モデル | コンピュータビジョン | マルチモーダル |
| 生成モデル | 責任あるAI | モデルの効率を向上させるアルゴリズム |
| 機械学習とコンピューターシステム | ロボット | 医療/健康 |
| 自然科学 | コミュニティとの関わり | その他の先進的なアルゴリズム |
このシリーズの他の記事は、公開次第順次リンクされます。
言語モデル(Language Models)
より大きく、より強力な言語モデルの開発は、過去10年間の機械学習(ML:machine Learning)研究の中で最もエキサイティングな分野の一つでした。
その過程であった重要な進歩は、sequence-to-sequenceの学習のような新しいアプローチや、ここ数年のこの分野での進歩のほとんどの基礎となる私たちのTransformerモデルの開発などでした。言語モデルは、一連の文章で前のトークンが与えられたときに次のトークンを予測するという、驚くほど単純な目的で学習されますが、大規模なモデルが十分に大きく多様なテキスト資料で学習すると、モデルは一貫性のある、文脈に沿った、自然に聞こえる応答を生成できるようになり、クリエイティブなコンテンツの生成、言語間の翻訳、コーディングタスクの支援、有益で情報提供する方法で質問に答えるなど幅広いタスクに使用することができます。私たちが現在取り組んでいるLaMDAでは、これらのモデルを安全で根拠ある高品質な対話にどのように利用し、文脈に応じた多回転の会話を可能にするかを研究しています。
自然な会話(Natural conversations)は、人々がコンピュータと対話する際の重要かつ新たな方法であることは明らかです。コンピュータ指示を伝えるために自分のスタイルを歪めるのではなく、自然な会話をすることで、さまざまなタスクを達成することができるようになるのです。私は、LaMDAの実用化に向けて前進していることに、とても興奮しています。
4月には、Pathwaysソフトウェア基盤を用いて構築し、複数のTPU v4 Podsで学習させた5400億パラメータの大規模言語モデル、PaLMに関する研究を紹介しました。PaLMは、次のトークンを予測するという目的のみで訓練されたにもかかわらず、大量の多言語データとソースコードで訓練された大規模言語モデルが、自然言語、翻訳、コーディングのさまざまなタスクで最先端技術を改善できることを実証しています。この研究は、モデルと学習データの規模を大きくすることで、能力を大幅に向上させることができることを示す新たな証拠となりました。
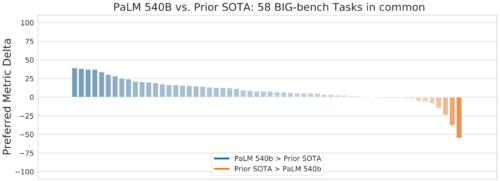
Big-bench suiteの58タスクにおけるPaLM 540Bパラメータモデルと従来の最先端モデル(SOTA)との性能比較(詳細は論文参照)
また、「ML-Enhanced Code Completion Improves Developer Productivity」で紹介したように、(自然言語のテキストデータではなく)ソースコードから学習した大規模言語モデル(LLM:large language models)を使って、社内開発者の支援に大きな成功を収めています。
IDEでこのモデルを使用している1万人のGoogleソフトウェア開発者の集団に対して、5億パラメータの言語モデルから得られるさまざまなコード補完候補を使用したところ、全コードの2.6%がモデルによって生成された候補から得られ、これらの開発者のコーディング反復時間が6%短縮されたことが確認されています。現在、このモデルの強化版を開発中であり、さらに多くの開発者にこのモデルを提供することを望んでいます。
人工知能の広範な主要課題の1つは、多段階推論を実行できるシステムを構築することです。複雑な問題をより小さなタスクに分解し、それらの解法を組み合わせてより大きな問題に対処することを学習します。
私たちが最近取り組んでいる「思考の連鎖プロンプト(Chain of Thought prompting)」は、モデルが新しい問題を解く際に「自分の仕事を見せる(show its work)」ように促すものです。(小学校4年生の算数の先生が、思いついた答えを書き留めるだけでなく、問題を解く手順を見せるように促す事と似ています)
思考の連鎖プロンプトは言語モデルが思考を論理的に連鎖させるに従って、より構造化し、整理し、正確な応答を生成できるよう支援します。小学4年生の算数を学んでいる生徒が自分の解法を見せるように、問題解決のアプローチをより解釈しやすくするだけでなく、複数の段階の推論を必要とする複雑な問題でも正しい答えが見つかる可能性が高くなるのです。
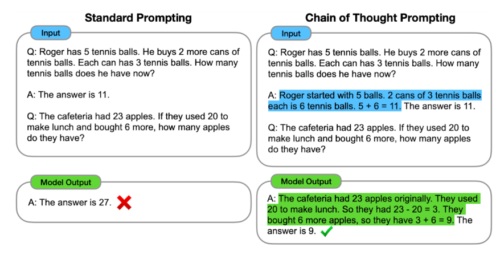
標準的なプロンプトを使用するモデルは、多段階推論問題であっても答えを直接提供します。これに対し、思考の連鎖プロンプトは、問題を中間的な推論ステップに分解することをモデルに教え、正しい最終的な答えに到達することをより良く可能にします。
多段階推論が最も明確に有益で測定可能な分野の一つは、モデルが複雑な数学的推論や科学的問題を解決する能力です。
MLモデルが多段階推論を用いて複雑な問題を解くことを学習できるかどうかは、重要な研究課題となっています。汎用言語モデルPaLMを用い、arXivの大規模な数学論文と科学研究論文の資料を使って微調整を行い、さらに思考の連鎖プロンプトと自己一貫性デコーディング(self-consistency decoding)を用いることで、Minervaの取り組みは、科学的・数学的ベンチマークスイートの広い範囲で、数学推論と科学問題に対する最先端技術から大幅に改善することを実証することができました。
| Model | MATH | MMLU-STEM | OCWCourses | GSM8k |
| Minerva | 0.503 | 0.75 | 0.308 | 0.785 |
| Published state of the art | 0.069 | 0.55 | – | 0.744 |
Minerva 5400億モデルはSTEM評価データセットにおいて、従来の最高のスコアを大幅に向上しました。
思考の連鎖プロンプトは、自然言語のプロンプトと事例をモデルによりよく表現し、新しいタスクに取り組む能力を向上させる方法の一つです。同様の学習型プロンプトチューニングは、大規模言語モデルを問題領域に特化したテキスト資料上で微調整するもので、大きな可能性を示しています。
論文「Large Language Models Encode Clinical Knowledge」では、学習型のプロンプトチューニングにより、比較的少ない事例数で汎用言語モデルを医療分野に適応できることを示し、その結果、米国医師免許試験問題(MedQA:Medical License Exam questions)で先行する機械学習モデルを17%以上上回る67.6%の精度を達成できることを実証しました。
臨床医の能力に比べるとまだ不十分ですが、理解度、知識の想起、医学的推論のすべてが、モデルの規模や指示のプロンプトの調整によって向上し、医療におけるLLMの有用性の可能性を示唆しています。今後も研究を続けることで、臨床応用に適した安全で有用な言語モデルを作成することができます。
また、多言語で学習した大規模な言語モデルは、文章を翻訳するように明示的に教えられていない場合でも、ある言語から別の言語への翻訳に役立てることができます。従来の機械翻訳システムは、通常、ある言語から別の言語への翻訳を学習するために、パラレルテキスト(翻訳済みテキスト)が必要でした。
しかし、パラレルテキストは比較的少数の言語ペア間にしか存在しないため、機械翻訳システムでは多くの言語がサポートされていないことが多いです。
「Unlocking Zero-Resource Machine Translation to Support New Languages in Google Translate」と付随する論文「Building Machine Translation Systems for the Next Thousand Languages」と「Towards the Next 1000 Languages in Multilingual Machine Translation」では、単言語データセット(翻訳文とセットになっていない)で学習した大規模な多言語言語モデルを使用して、3億人が話す24言語をGoogle翻訳に新たに追加する一連の技術について説明しています。
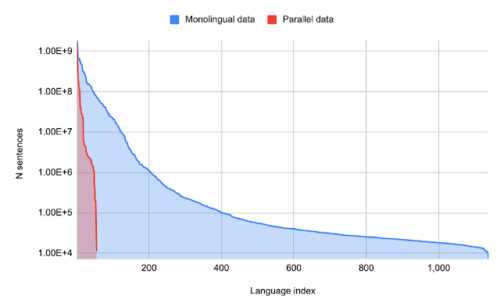
言語あたりの単言語データの量と言語あたりのパラレル(翻訳済)データの量。少数の言語は大量の並列データを持ちますが、単言語データしか持たない言語が大量に存在します。
もう一つの代表的なアプローチは学習可能なソフトプロンプトです。これは、プロンプトを表現するために新しい入力トークンを作成する代わりに、少数回のタスクから学習できる調整可能なパラメータをタスクごとに追加します。
このアプローチは一般に、ソフトプロンプトを学習したタスクで高い性能を発揮し、同時に事前に学習した大規模な言語モデルを数千の異なるタスクで共有することを可能にします。これは、より一般的な技術であるタスク適応(task adaptors)の具体例であり、タスク固有の適応とチューニングを可能にしながら、パラメータの大部分をタスク間で共有することを可能にしています。
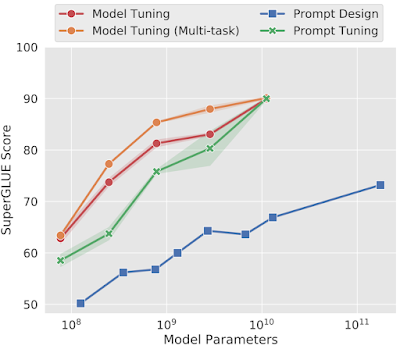
また、プロンプトチューニングは、調整可能なソフトプロンプトを使用して凍結したモデルを条件付けるものです。規模が大きくなると、25,000個少ないパラメータを使用しても、モデルを直接チューニングした性能に匹敵する性能を発揮します。
興味深いことに、言語モデルは規模が大きくなると、新しい機能の出現により、その有用性が著しく増大することがあります。
「Characterizing Emergent Phenomena in Large Language Models」では、ある規模に達するまでは、これらのモデルが特定の複雑なタスクをあまり効果的に実行できないという、時に驚くべき特性について検証しています。
しかしその後、臨界量を超える学習が行われると(タスクによって異なる)、突然、複雑なタスクを正確に実行する能力に大きな性能飛躍が見られるようになります(下図参照)。そこで、このモデルをさらに学習させると、どのような新しいタスクが実現可能になるのか、という疑問が生じます。
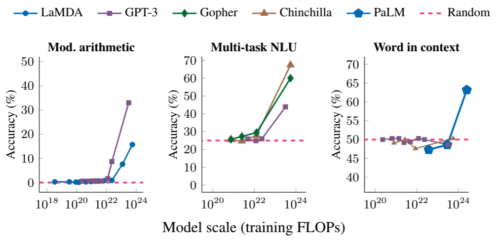
多段階計算(左)、大学レベルの試験での正答(中)、文脈から単語の意味を特定する(右)能力はすべて、十分に大きな規模のモデルに対してのみ出現する能力です。このモデルには、LaMDA、GPT-3、Gopher、Chinchilla、PaLMが含まれます。
さらに、十分な規模の言語モデルは、新しい情報やタスクに対して学習・適応する能力を備えており、より汎用的で強力なものとなっています。このような言語モデルの改良と高度化が進めば、私たちの生活のさまざまな場面で、ますます重要な役割を果たすことになるでしょう。
3.2022年のGoogleのAI研究の成果と今後の展望~言語・視覚・生成モデル編~(1/5)関連リンク
1)ai.googleblog.com
Google Research, 2022 & Beyond: Language, Vision and Generative Models
2)arxiv.org
Large Language Models Encode Clinical Knowledge
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Pixel Recurrent Neural Networks
Neural Discrete Representation Learning
Image Transformer
Vector-quantized Image Modeling with Improved VQGAN
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
3)benanne.github.io
Guidance: a cheat code for diffusion models
4)research.google
Imagen : unprecedented photorealism × deep level of language understanding
Phenaki : Realistic video generation from open-domain textual descriptions
5)google-research.github.io
AudioLM : A Language Modeling Approach to Audio Generation
6)ai.google
2022 AI Principles Progress Update(PDF)

