
1.2022年のGoogleのAI研究の成果と今後の展望~言語・視覚・生成モデル編~(3/5)まとめ
・次世代のAIは特定のデータ形式しか扱えない従来のAIと異なり複数のデータ形式を扱えう事が可能
・マルチモーダルモデルと呼ばれるこれらのAIは音声、動画、画像、複数言語等を同時に扱える能力を持つ
・2022年にGoogleで開発されたマルチモーダル型のAIの事例を紹介。既に製品化されているケースもある
2.Google AIの2022年の振り返り~マルチモーダル編~
以下、ai.googleblog.comより「Google Research, 2022 & Beyond: Language, Vision and Generative Models」の意訳です。元記事の投稿は2023年1月18日、Google AIのトップのJeff DeanがGoogle Research communityを代表しての執筆です。
アイキャッチ画像はstable diffusionのカスタムモデルによる生成
マルチモーダル(Multimodal Models)
これまでの機械学習(ML:Machine Learning)の研究は、言語を扱う言語モデル、画像を扱う画像分類モデル、音声を扱う音声認識モデルなど、一種類のデータ形式(modality)を扱うモデルに焦点が当てられてきました。
この分野では多くの素晴らしい進歩がありましたが、将来は、モデルの入力としても出力としても、同時に多くの異なるデータ形式を柔軟に扱えるマルチモーダルモデルが期待されます。私たちはこの1年、様々な形でこの方向性を推し進めてきました。

次世代のマルチモーダルモデルは、特定のタスクや領域に特化した個別のモデルに依存するのではなく、与えられた問題に必要な経路のみを活性化するモデルであり、異なるデータ形式を同時に扱うことができます。
マルチモーダルモデルを構築する際、異なるデータ形式間の特徴や学習を可能にするために解決しなければならない2つの重要な問題があります。
(1)学習した特徴表現を統合する前に、どの程度個々のデータ形式に特化した処理を行うべきでしょうか?
(2)特徴表現を混合する際に最も効果的な手法は何でしょうか?
「Multi-modal Bottleneck Transformers」とそれに付随する「Attention Bottlenecks for Multimodal Fusion」に関する論文では、これらのトレードオフを調査しました。
その結果、データ形式固有の処理を数層行った後にデータ形式をまとめてから、ボトルネックレイヤーを介してさまざまなデータ形式からの特徴表現を混合する事が他の手法よりも効果的である事を発見しました。(下図のボトルネック中期融合(Bottleneck Mid Fusion)で示されているように)
この手法は、元データから得られる複数のデータ形式を使用して分類を行うことを学習させる事で、様々なビデオ分類タスクの精度を大幅に向上させます。

マルチモーダル Transformer エンコーダーのAttention構成の例
音声(赤丸)と動画(青丸)からなる行は、エンコーダー レイヤーを表します。マルチモーダル Transformer エンコーダー特徴融合(完全融合)の典型的なアプローチでは、レイヤー内の隠れユニット全体でpairwise self attentionを使用します(左)。
ボトルネック融合(中央)は、Attentionボトルネックと呼ばれるタイトな潜在ユニットを介してレイヤー内のAttentionの流れを制限します。
ボトルネック中期融合(右)は、ボトルネック融合を後方のレイヤーにのみ適用して、最適なパフォーマンスを実現します。
データ形式を組み合わせると、単一データ形式のタスクでも精度が向上することがよくあります。 これは、画像特徴表現と単語embedding表現を組み合わせて画像分類の精度を向上させる DeViSE に関する研究を含め、私達が長年にわたって調査してきた領域であり、初見の物体カテゴリであっても、分類の精度を向上します。
この汎用的なアイデアを少し変えた最新の事例は、既存の事前トレーニング済みの画像モデルに言語の理解を追加する方法であるLocked-image Tuning(LiT)に見られます。
このアプローチでは、テキスト エンコーダーを対照的な手法でトレーニングして、事前トレーニング済みの強力な画像エンコーダーからの画像特徴表現と一致させます。この単純な方法は、データと計算が効率的であり、既存の対照的な学習アプローチと比較して、ゼロ ショット画像分類のパフォーマンスが大幅に向上します。
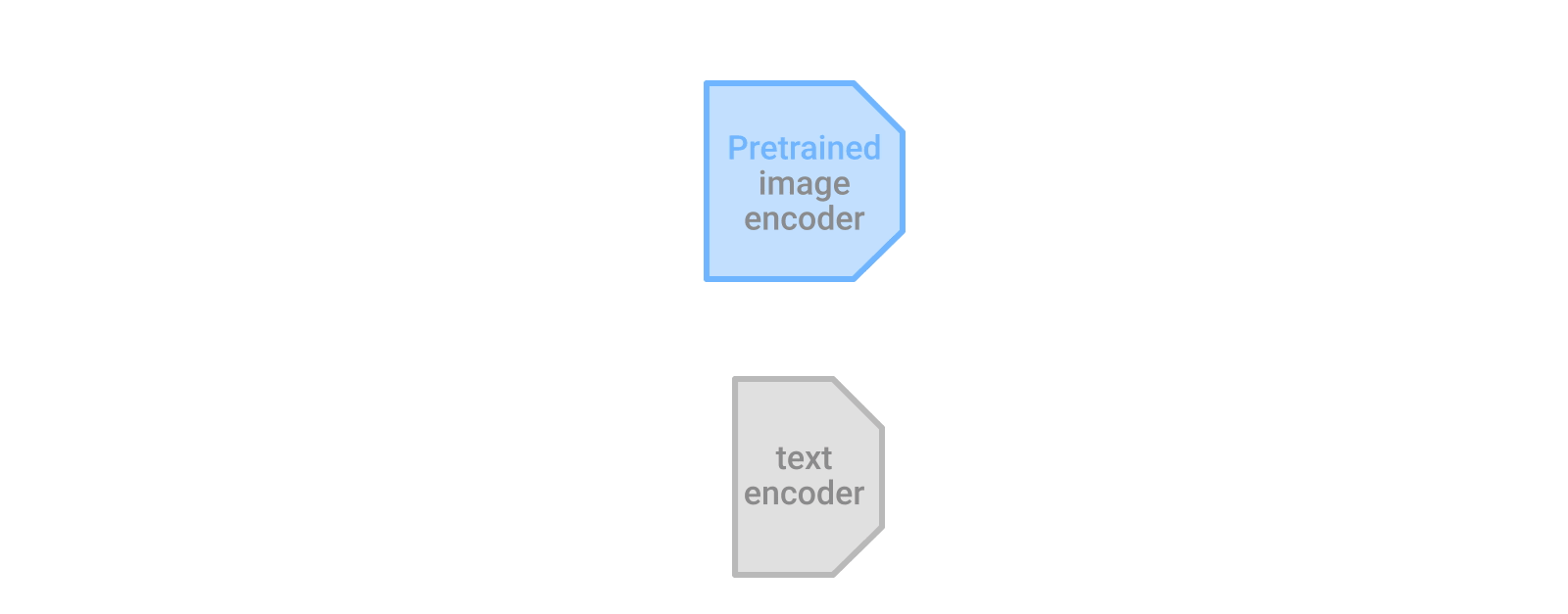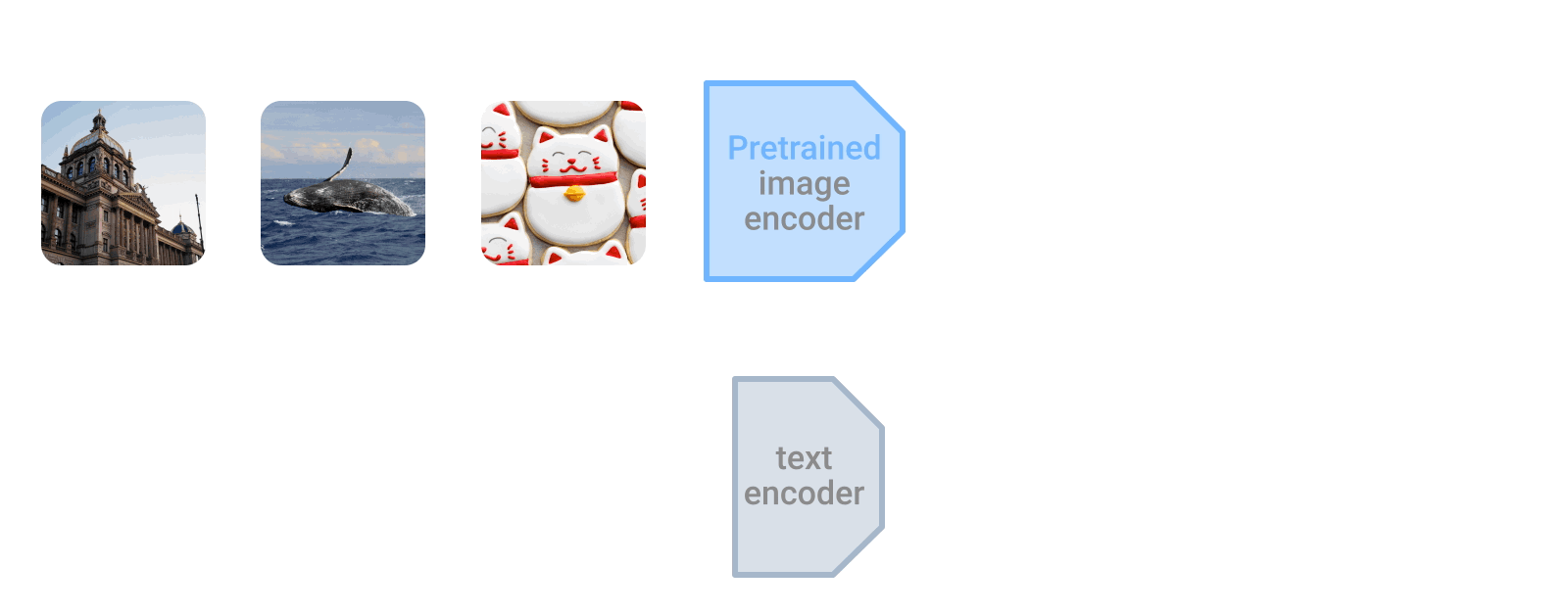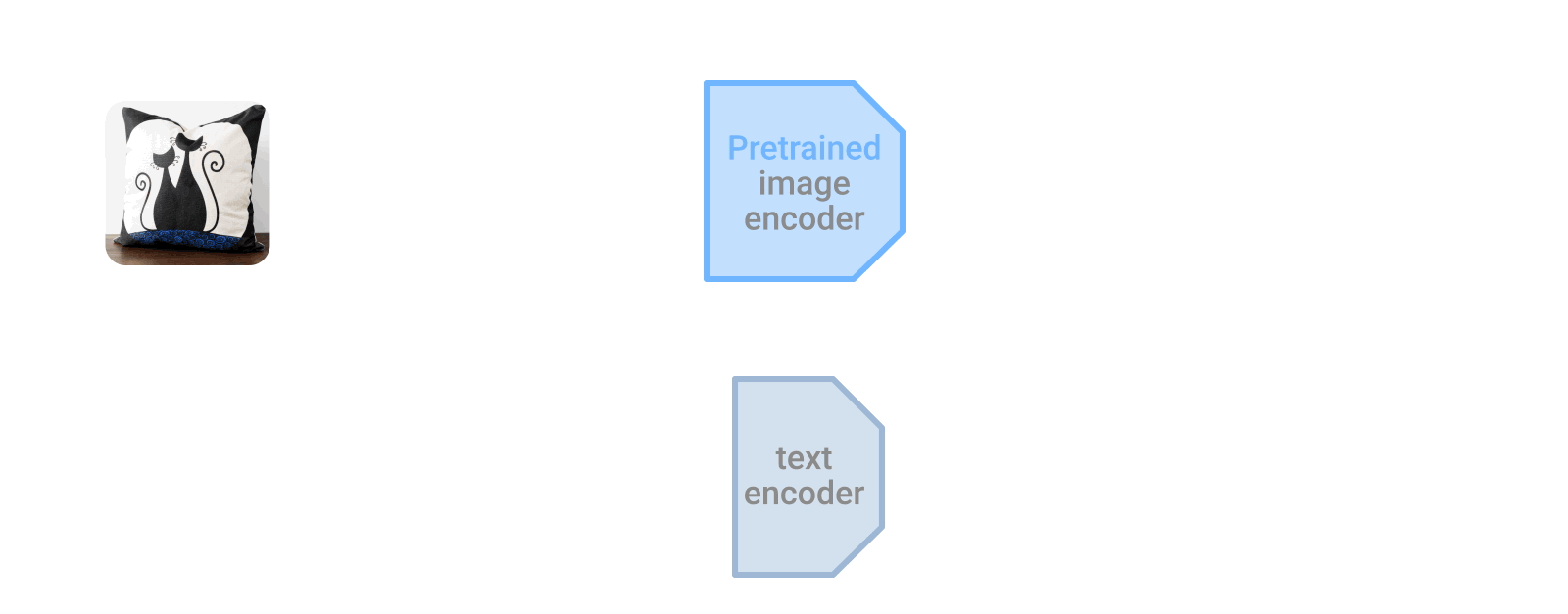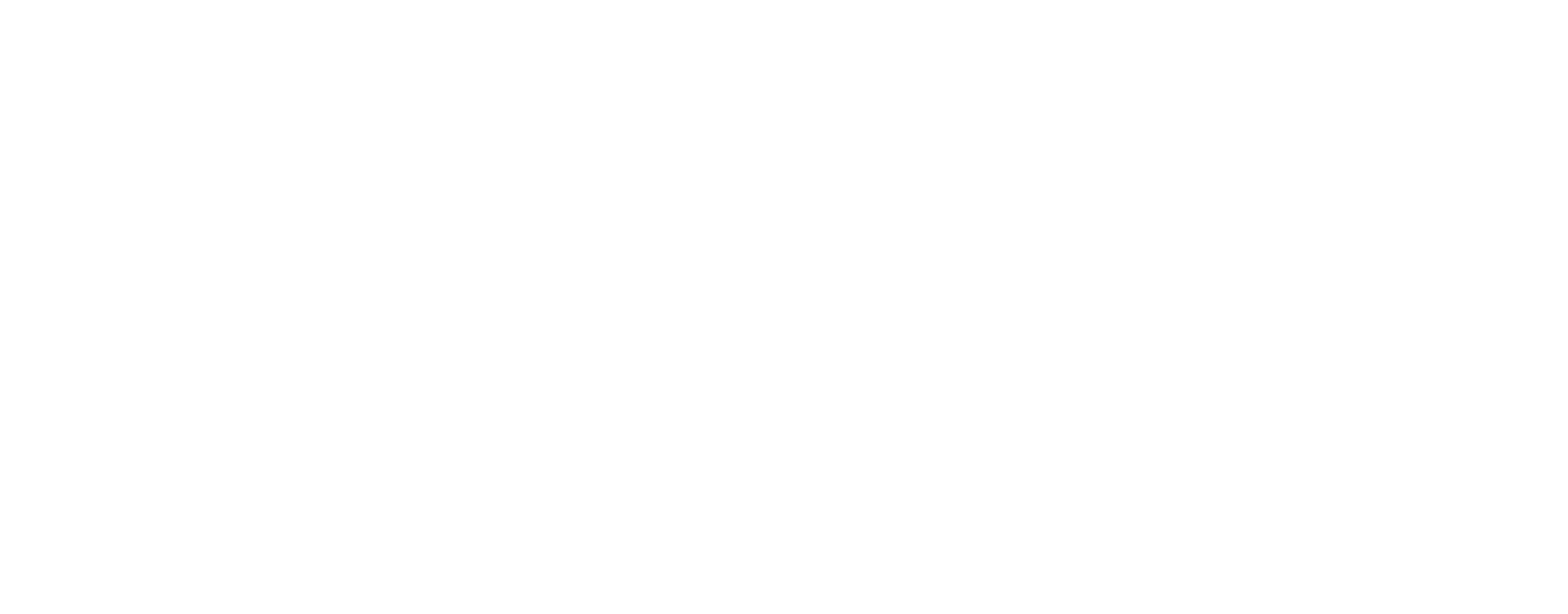
LiTによるチューニングは、事前にトレーニングされた画像エンコーダーと一致するようにテキスト エンコーダーを対照的にトレーニングします。 テキスト エンコーダーは、画像エンコーダーからの表現に合わせて特徴表現を計算することを学習します。
単一データ形式におけるマルチモーダル モデルのもう一つの使い道は、画像やビデオなどの関連するデータ形式を共同トレーニングするときに観察されます。
多くの場合、ビデオ データのみを使ったトレーニングと比較して、ビデオ内のアクション分類タスクの精度を向上させることができます。(特に、1つのデータ形式のトレーニング データが限られている場合)
言語を他のデータ形式と組み合わせることは、ユーザーがコンピューターと対話する方法を改善する際に考えられる自然なステップです。私たちは今年、この方向性をさまざまな方法で探求してきました。最も興味深いものの 1 つは、言語と視覚入力(静止画像またはビデオ)を組み合わせることです。
「PaLI: Scaling Language-Image Learning」では、100を超える言語で多くのタスクを実行するようにトレーニングされた統合言語-画像モデル(unified language-image model)を紹介しました。
これらのタスクは、視覚、言語、マルチモーダルな画像-言語アプリケーション、視覚入力に対して文章で回答する事、画像に説明文を付与、物体検出、画像分類、光学式文字認識、テキスト推論などに及びます。
Vision Transformer(ViT)をテキストベースのTransformerエンコーダーと組み合わせてから、Transformerベースのデコーダーを組み合わせてテキストの回答を生成させます。システム全体を直接、多くの異なるタスクで同時にトレーニングすることで、システムは多くの異なるベンチマークで最先端のスコアを達成します。
たとえば、PaLI は CrossModal-3600ベンチマークで最先端の結果を達成しています。このベンチマークは、多言語、マルチモーダル機能の多様なテストであり、35の言語で平均CIDErスコアが 53.4です(従来の最高スコアである 28.9 から大幅な改善です)。
下図が示すように、複数のデータ形式と多くの言語を同時に理解し、画像説明文付与や質問回答などの多くのタスクを処理できる単一のモデルを持つことで、他の種類の感覚的な入力について自然な会話を行うことができるコンピューター システムにつながります。
さまざまな言語で質問をして、ニーズに対する回答を得る事ができます。
「この画像のテーブルの上にあるものをタイ語で言えますか?」、「枝に何匹のパラキート(parakeet、中型インコを意味する古い綴り)がいますか?」、「この画像についてスワヒリ語で説明してください」、「この画像内にあるヒンディー語の文章は何ですか?」
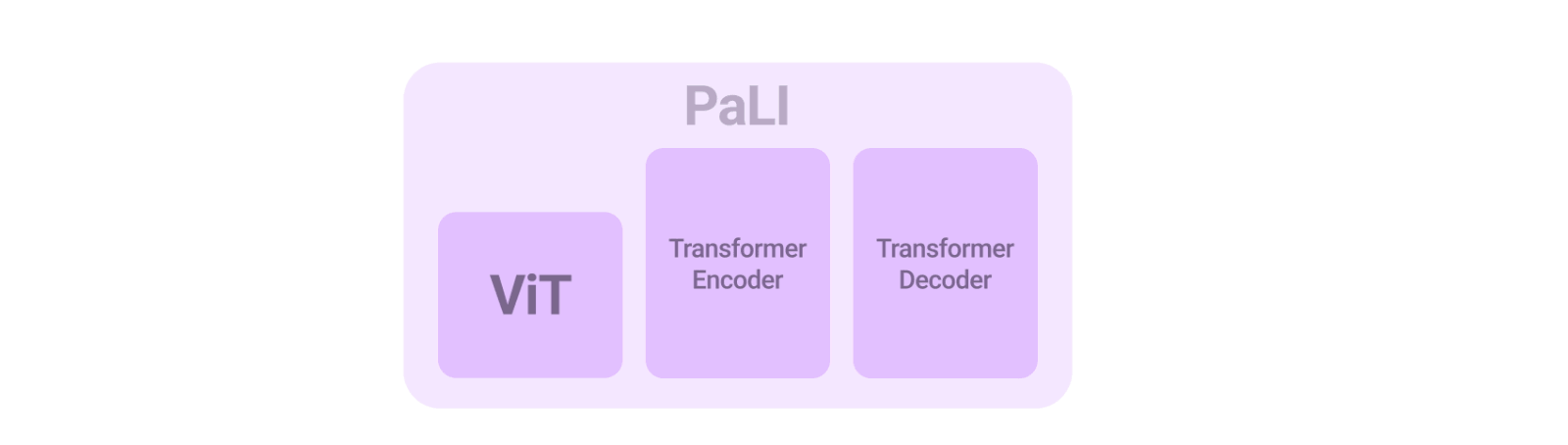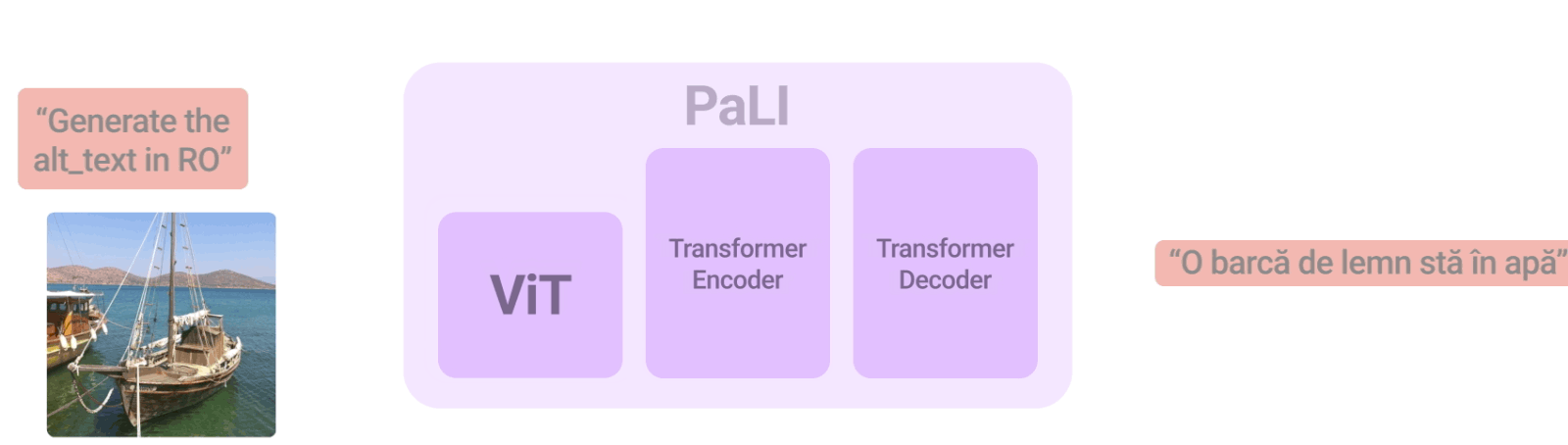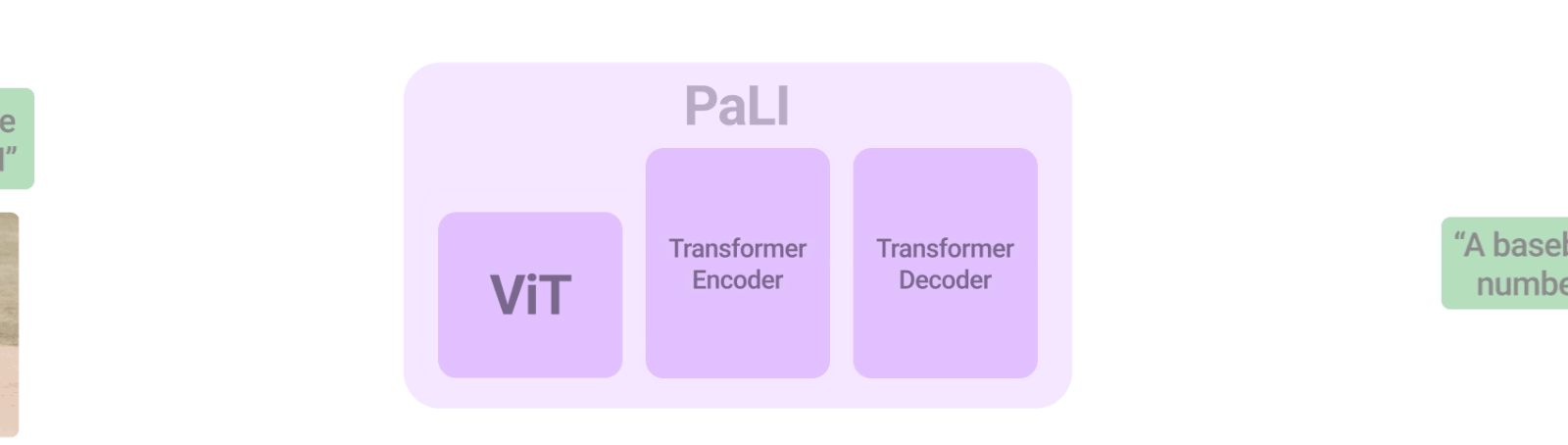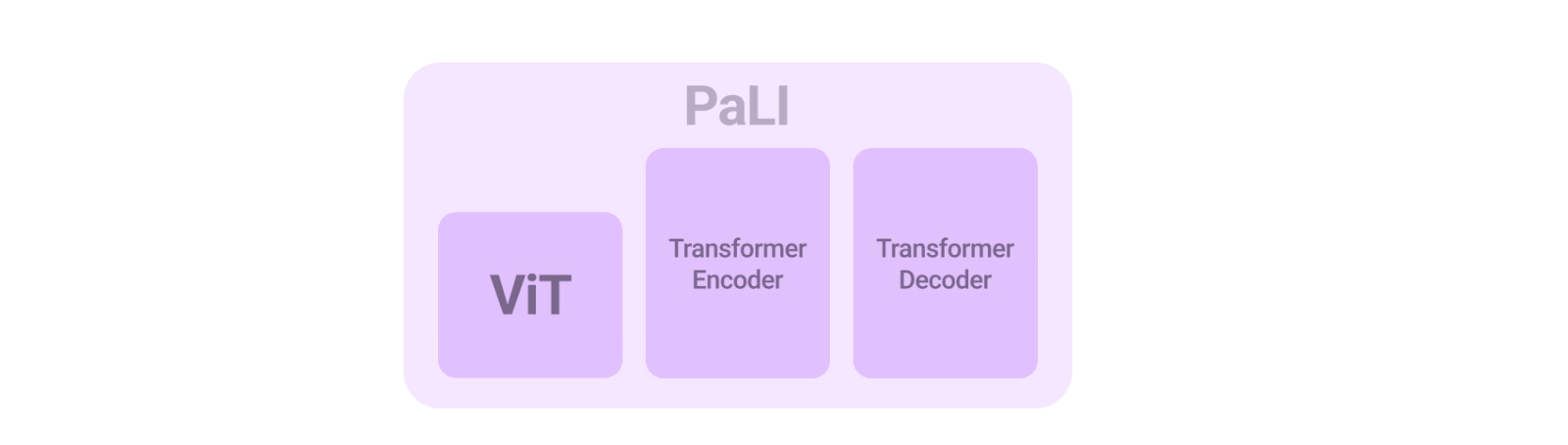
PaLIモデルは、言語-画像、言語のみ、画像のみの領域で、同じAPIを用いて幅広いタスク(例:視覚的質問回答、画像説明文付与、風景-文章理解など)に対応する事ができます。このモデルは100以上の言語をサポートするように学習され、複数の言語-画像タスクに対して多言語で実行できるようにチューニングされています。
同様に、FindItの研究は、画像に関する視覚的な自然言語の質問に、統一された汎用的でマルチタスクな視覚に基づくモデルによって答えることを可能にします。
FindItは異なるデータ形式に基づく質問と検出の問い合わせに柔軟に答えることができます。

FindItは、言及された表現を理解するタスク(1列目)、文章を使った位置特定タスク(2列目)、物体検出タスク(3列目)を統一的に扱えるモデルです。FindItは、例えば「机を探せ」(4列目)のように、学習時に見たことのなかった物体の種類や枠組みに対してテストを行っても、正確に応答することができます。比較のため、MattNetの結果を示します。
ビデオを使った質問応答の分野、例えば、パン作りのビデオが与えられたとき「ボウルに注がれた2番目の材料は何ですか?」といった質問に答えられるようになるためには、テキスト入力(質問)とビデオ入力(関連ビデオ)の両方を理解し、テキストによる答えを生成する能力が必要です。
「Efficient Video-Text Learning with Iterative Co-tokenization」では、同じビデオ入力を元に複数のビデオ入力(例えば、高解像度版のビデオ、低フレームレートで低解像度のビデオ、高フレームレートのビデオ)を、デコーダがテキスト入力と効率的に融合してテキストベースの答えを生成します。
ビデオ-文章反復的共同トークン化モデル(video-text iterative co-tokenization)は、入力を直接処理する代わりに、融合されたビデオ-言語入力で有用なトークンを絞って学習します。この処理は繰り返し行われ、現在の特徴トークン化が次の繰り返しにおけるトークンの選択に影響を与えるので、選択を洗練させることができます。

ビデオ質問回答タスクの質問の例「ボウルに注がれた2つ目の食材は何ですか?」
映像入力と文章入力の両方を深く理解することが必要となります。動画は50 Saladsデータセットからの一例で、クリエイティブ・コモンズ・ライセンスの下で使用されています。
高品質な映像コンテンツを作成するプロセスには、映像の撮影から映像・音声の編集まで、いくつかの段階が含まれることがよくあります。
場合によっては、スタジオで会話を再録音し(会話置き換え(dialog replacement)、ポストシンク(post-sync)、ダビング(dubbing)と呼ばれます)、ノイズの多い場所や最適でない条件で録音されたかもしれないオリジナルの音声を高品質に置き換えることがあります。
しかし、台詞の置き換えは、新たに録音した音声と映像の同期を取る必要があり、口の動きのタイミングを合わせるために何度も編集を行う必要があるため、困難で手間のかかる作業となる場合があります。
「VDTTS: Visually-Driven Text-To-Speech」では、このタスクをより簡単に達成するためのマルチモーダルモデルを研究しています。VDTTSは、テキストと映像があれば、タイミングや感情などの韻律を回復しつつ、映像にマッチしたテキストを音声出力することができます。このシステムは、映像との同期、音声品質、音声の高低を測定する様々な指標において、大幅な改善を示しています。興味深いことに、このモデルは、これを促進するための明示的な制約やモデル学習における損失なしに、ビデオと同期した音声を生成することができます。
| Original | VDTTS | VDTTS video-only | TTS |
Original:オリジナルのビデオクリップ
VDTTS:ビデオフレームとテキストを入力に使った際に予測された音声
VDTTS video-only:ビデオフレームのみを使った際に予測された音声
TTS: テキストのみを入力とて使った際に予測された音声
元の台本のセリフ「absolutely love dancing I have no dance experience whatsoever but as that」
「Look and Talk: Natural Conversations with Google Assistant」では、端末上のマルチモーダルモデルが、Google Assistantとの対話をより自然にするために、ビデオと音声の両方の入力をどのように使用できるかを示しています。
このモデルは、視線方向、近接性、顔照合、音声照合、意図分類など、多くの視覚と聴覚の手がかりを使用して、近くの人が実際にGoogle Assistantデバイスに話しかけようとしているのか、デバイスに何らかの動作をさせる意図もなくたまたまデバイスの近くで話しているのかをより正確に判断するよう学習しています。音声や視覚の特徴だけでは、この判断はかなり難しいでしょう。
マルチモーダルモデルは、自然言語や画像といった人間向けのデータ形式を組み合わせるだけにとどまらず、実際の自律走行車やロボット工学のアプリケーションでも重要性が高まっています。
この文脈では、このようなモデルは、自律走行車に搭載された光学距離検知システム(LiDAR)から得た3次元点群データのような、人間の感覚とは異なるセンサーの生の出力を取り込み、これを車両カメラのような他のセンサーからのデータと組み合わせて、周囲の環境をより良く理解し、より良い判断を下すことができます。
「4D-Net for Learning Multi-Modal Alignment for 3D and Image Inputs in Time」では、LiDARから得た3次元点群データとカメラからのRGBデータをリアルタイムに融合し、自己Attention機構により、異なるレイヤーでの特徴の混合と重み付けを制御しています。
異なるデータ形式を組み合わせ、時間軸に沿った特徴を用いることで、どちらかのデータ形式を単独で用いるよりも、3次元物体認識の精度を大幅に向上させることができます。LiDARとカメラの融合に関する最近の研究では、学習可能な位置合わせと逆補強によるより良い幾何学処理を導入し、3次元物体認識の精度をさらに向上させました。
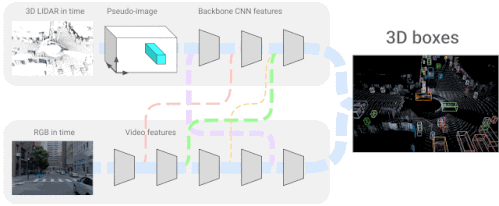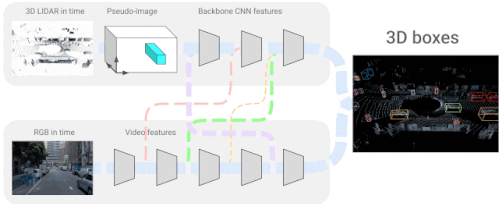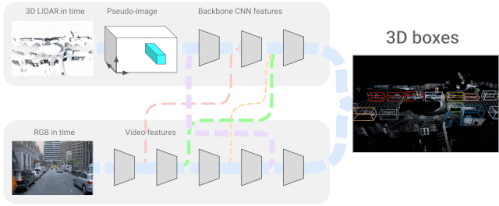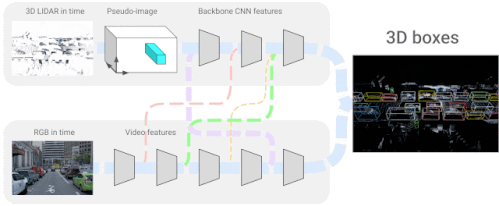
4D-Netは、三次元LiDARの点群と、ビデオから時間的にストリーミングされたRGB画像を効果的に組み合わせ、異なるセンサー間の接続とその特徴表現を学習します。
多くの異なるデータ形式を流動的かつ文脈的に理解し、その文脈の中で多くの異なる種類の出力(例えば言語、画像、音声)を生成できる単一のモデルを持つことは、より有用で汎用的なMLの枠組みを形成することになります。
私達は、この枠組みにより、多くの Google 製品で新しいエキサイティングなアプリケーションを実現可能になり、また、健康、科学、創造性、ロボット工学などの分野も発展させることができる事に興奮しています!
3.2022年のGoogleのAI研究の成果と今後の展望~言語・視覚・生成モデル編~(3/5)関連リンク
1)ai.googleblog.com
Google Research, 2022 & Beyond: Language, Vision and Generative Models
2)arxiv.org
Large Language Models Encode Clinical Knowledge
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Pixel Recurrent Neural Networks
Neural Discrete Representation Learning
Image Transformer
Vector-quantized Image Modeling with Improved VQGAN
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
3)benanne.github.io
Guidance: a cheat code for diffusion models
4)research.google
Imagen : unprecedented photorealism × deep level of language understanding
Phenaki : Realistic video generation from open-domain textual descriptions
5)google-research.github.io
AudioLM : A Language Modeling Approach to Audio Generation
6)ai.google
2022 AI Principles Progress Update(PDF)

