
1.2022年のGoogleのAI研究の成果と今後の展望~MLとコンピュータシステム編~(1/3)まとめ
・複雑なモデルの提供とトレーニングをサポートすることを可能にするML用システムの昨年の進歩の概要の説明
・大規模モデルを効率的に規模拡大し、プログラムするために分散システムやストレージの改良を行った
・プログラミング言語とコンパイラの研究を進めてJAXモデルをスマホやWebに展開できるようにした
2.ML向け分散システムとプログラミング言語
以下、ai.googleblog.comより「Google Research, 2022 & beyond: Responsible AI」の意訳です。元記事の投稿は2023年2月2日、Mangpo PhothilimthanaさんとAdam Paszkeさんによる投稿です。
ソフトウェアの深い所のお話なので馴染みのない単語も沢山でてきますが、Pathwaysがデータセンターをまたいで仮想化が出来ているという話を読んで、やっぱり設計思想に最初から規模拡大が念頭におかれているからこんな事が出来るのだろうな、と思います。
2021年の記事ですが、OpenAIのハード環境の記事「Kubernetesのノード数を7500に拡張」を置いておくとこちらも、もの凄い規模ですけれども「数で殴る」という意味ではまだ頭で理解できるのです。しかし、Googleは「もっともっと沢山の数で殴りたいので筋トレをしてるんですよ、ハッハッハー」的な記事で、何かもう、お腹いっぱいになってきてしまいます。
アイキャッチ画像はstable diffusionのカスタムモデルによる生成でコンピューターを操作しているナウシカとテト
(本記事は、Googleの様々な研究分野を取り上げるシリーズの第3部です。このシリーズの他の記事は第一部「2022年のGoogleのAI研究の成果と今後の展望~言語・視覚・生成モデル編~」からご覧いただけます)
優れた機械学習(ML:Machine Learning)研究には、優れたシステムが必要です。
現在使用されているアルゴリズムとハードウェアがますます洗練され、それらが実行される規模が大きくなるにつれて、日々のタスクを実行するために必要なソフトウェアの複雑さも増すばかりです。この投稿では、エンドユーザーの実装の複雑さを緩和しながら、複雑なモデルの提供とトレーニングをサポートすることを可能にするML用システムにおいて、この1年間にGoogle全体で行われた数々の進歩の概要を説明します。また、本投稿では、次世代システムの改善と設計を支援するために、ML自体を活用する私たちの研究にも焦点を当てています。
ML向け分散システム
今年、私たちはMLや科学技術計算における大規模計算をよりよくサポートするために、システムの改良に大きな前進を遂げました。Google TPUハードウェアは、構想当初から規模拡大を念頭に置いて設計されており、毎年、その限界をさらに押し広げるよう努力しています。
今年は、大規模モデルのための最先端の処理技術を設計し、テンソルプログラムの自動分割を改善し、ライブラリのAPIを作り直し、これらの開発のすべてが幅広いユーザーにとって利用しやすいものになるようにしました。
今年の最大の効率化のひとつは、ニューラルネットワークの心臓部である大規模な行列乗算演算を評価するCollectiveEinsum戦略です。
デバイス内のローカルな計算から通信を分離する、これまで一般的だったSPMDパーティショニング戦略とは異なり、このアプローチでは、高速なTPU ICIリンクを使用してそれらを重複させ、最大で1.38倍の性能向上を実現しました。このアルゴリズムは、Transformer推論の効率的なスケーリングに関する私達の研究の重要な要素でもあり、応答遅延とハードウェア利用率の間でトレードオフする多様な戦略を提示し、処理能力を最適化した構成で76%という最先端のモデルFLOPs利用率(MFU)を達成しました。

CollectiveEinsum戦略で提案された、2-way intra-layerモデル並列を用いたAllGather-Einsumの概略
上:非重複実行の図
下:CollectiveEinsum手法の図
また、TensorFlowのDTensor拡張とJAXの配列型の再設計により、SPMD型の分割を優先概念として統合しました。どちらのライブラリでも、プログラマが完全だと思うテンソルを、宣言的なレイアウト注釈を付けるだけで透過的に多くのデバイスにシャーディングすることができます。実際、どちらのアプローチもシングルデバイスの計算のために書かれた既存のコードと互換性があり、通常はコードを修正することなくマルチデバイスのプログラムに拡張することができます!
SPMDパーティショニングをMLフレームワークの中心部に統合することは、配列プログラムがより多くのデバイスにマッピングされる方法を推測し最適化できることが、パフォーマンスにとって重要であることを意味します。
これは、過去にこの分野の重要なマイルストーンであるGSPMDを開発する動機となりました。しかし、GSPMDは経験則に依存する部分が多く、依然として人間による非自明な判断が必要な場合があり、その結果、最適な性能が得られないことが多くあります。
分割推論を完全に自動化するために、私たちは外部の研究者と共同で、演算子レベル(モデル)の並列と大規模サブコンピュータ間のパイプライン並列の両方の戦略を探索する完全自動システム「Alpa」を開発しました。このシステムは、Transformersのような一般的なモデルにおいて、手作業で調整された性能にうまく適合していますが、畳み込みネットワークやMoE(mixture-of-experts)モデルなど、既存の自動化手法ではしばしば苦労する他のモデルのスケールアップにも成功しています。
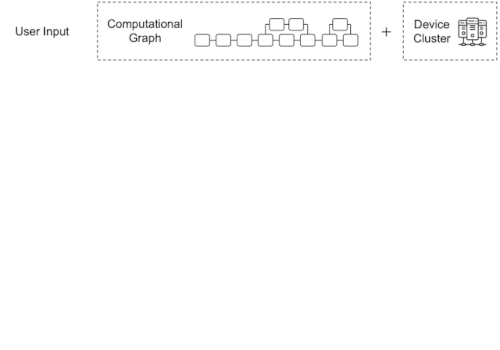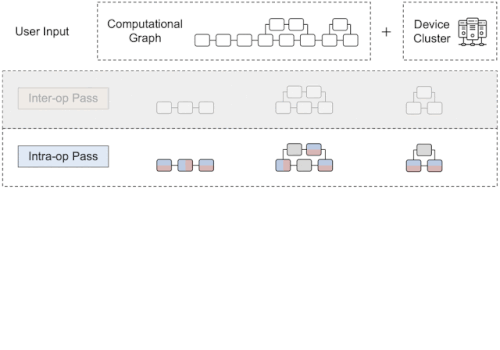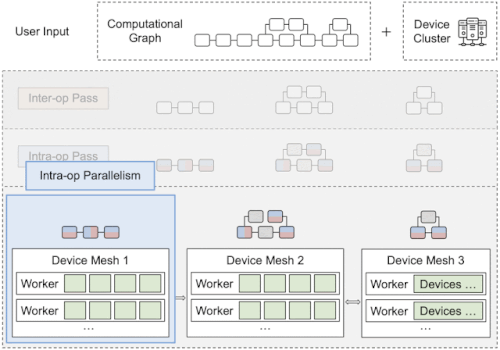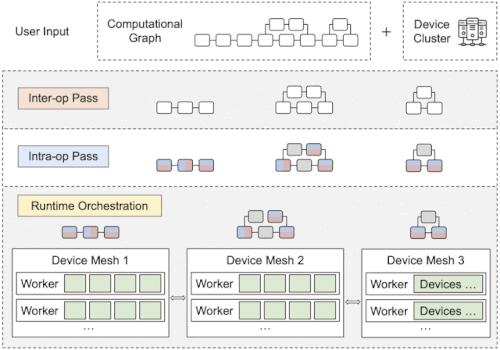
Alpaの概要
インターオペレータは、サブグラフをサブメッシュに割り当てる最適な方法を特定します。イントラオペレータパスでは、各パイプラインステージの最適なイントラオペレータ並列化計画を見つけます。最後に、ランタイム・オーケストレーションは、計算と通信を順序付ける静的計画を生成します。
これと同様に、最近発表されたPathwaysシステムでは、通常のTPUランタイムの上に仮想化のレイヤーを追加しています。
アクセラレータは、ユーザーに直接割り当てられるのではなく、長寿命のプロセスによって管理されます。
1人のエンドユーザーが、任意の数のPathways制御のデバイスに接続し、あたかもすべてのデバイスが自分のプロセスに直接接続されているかのようにプログラムを書くことができます。(実際には、複数のデータセンターにまたがっている可能性もあります)。
Pathwaysにより、(1)ジョブ起動時間の短縮、(2)障害耐性、(3)単一インスタンスを複数人で利用するマルチテナンシー(multitenancy)が可能となり、複数のジョブを同時に実行してハードウェアをより効率的に利用することができるようになりました。
Pathwaysが複数のTPUポッドにまたがって計算を行うことを容易にすることは、将来のスケーリングのボトルネックを回避するために非常に重要です。
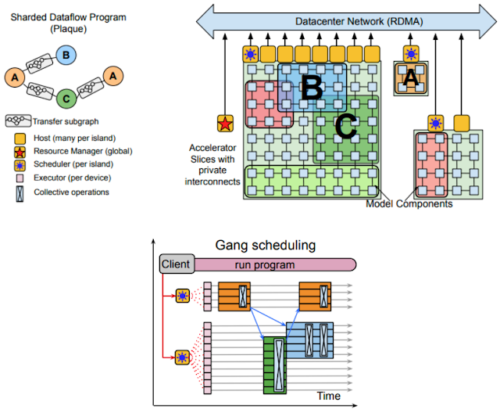
Pathwaysの概要
左上:Directed Acyclic Graphで表現された分散計算
右上:リソースマネージャは、コンパイルされた関数(例:A、B、C)毎にアクセラレータメッシュの仮想スライスを割り当てます。
下図:中央のスケジューラで計算を関連するプロセスを異なるプロセッサでスケジューリング(gang-schedule)し、各シャード実行器がディスパッチします。(詳細は論文参照)。
もう一つの注目すべきリリースは、多次元配列ストレージのための新しいライブラリであるTensorStoreです。
TensorStoreは、マルチコントローラランタイムで大規模言語モデル(LLM:Large Language Models)を学習する際に特に有用です。マルチコントローラランタイムでは、各プロセスはすべてのパラメータのサブセットのみを管理し、そのすべてを一貫したチェックポイントに照合しなければなりません。
TensorStoreは、多くのストレージバックエンド(Google Cloud Storage、各種ファイルシステム、HTTPサーバなど)に効率的かつ同時に多次元配列をシリアライズするデータベース級の保証(ACID)を提供し、PaLMやヒト大脳皮質およびミバエ脳の再構成などの計算負荷の高いワークロードに使用されて成功を収めてきました。
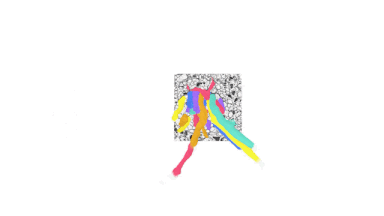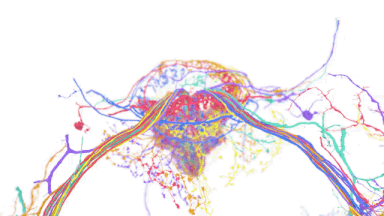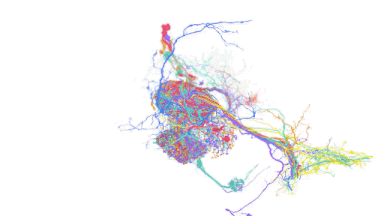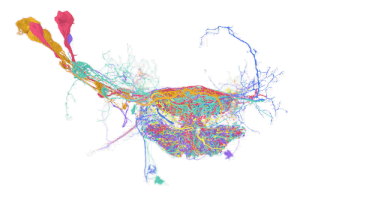
ハエの脳を再構成図
TensorStoreを利用しているため、基礎データに簡単にアクセスし、操作することができます。
機械学習用プログラミング言語
機械学習(ML:Machine Learning)に取り組む上で、技術基盤の堅牢性と正確性は非常に重要です。そのため、私たちはプログラミング言語とコンパイラの構築に関する最先端の研究に裏打ちされた、健全な技術的・理論的基盤の上に構築することを約束し続けます。
オープンソースのマルチレベル中間特徴表現コンパイラ(MLIR:Multi-Level Intermediate Representation)基盤への投資を続け、より制御可能でコンパイル可能なモジュール式のコンパイラスタックを構築しています。
また、疎な線形代数(sparse linear algebra)のコード生成に大きな進展があり、ほぼ同一のMLIRプログラムから密と疎の両方のコードを生成することが可能になりました。さらに、中間表現実行環境コンパイラ(IREE:Intermediate Representation Execution Environment)の開発を進め、データセンターに設置された強力なコンピュータとスマートフォンなどのモバイルデバイスの両方で使用できるように準備を進めています。
より理論的な面では、私たちが使用しているコード生成技術を形式化し、検証する方法を探りました。また、MLライブラリの中核をなす自動微分(AD:Automatic Differentiation)システムの実装と定式化に用いる新しいアプローチを発表しました。リバースモードADアルゴリズムを3つの独立したプログラム変換に分解し、JAXの実装の特徴を生かしながら、よりシンプルで検証しやすいものにしました。
抽象解釈(Abstract interpretation、プログラムを部分的に実行して近似的に評価する事)やプログラム合成などのプログラミング言語技術を活用し、ニューラル・アーキテクチャ・サーチ(NAS)の実行に必要なリソース数の削減に成功しました。この取り組み、αNASは、精度を落とすことなく、より効率的なモデルの発見に繋がりました。
昨年は、RaxやT5Xをはじめとする多くの新しいオープンソースライブラリをJAXエコシステムで公開しました。jax2tfに関する継続的な取り組みにより、JAXモデルはTensorFlow Liteを使ってモバイルデバイスに、TensorFlow.jsを使ってWebに展開することができるようになったのです。
3.2022年のGoogleのAI研究の成果と今後の展望~MLとコンピュータシステム編~(1/3)関連リンク
1)ai.googleblog.com
Google Research, 2022 & beyond: ML & computer systems
2)github.com
google-research / circuit_training

