
1.2022年のGoogleのAI研究の成果と今後の展望~ディープラーニング用モデルの効率を向上させるアルゴリズム編~(1/3)まとめ
・AIや機械学習が製品やビジネスシーンに導入される機会が増えるにつれ、モデルの効率とコストは些細な考慮事項から主要な制約事項へと変化してきた
・Googleは機械学習の効率化を、効率的なアーキテクチャ設計、学習の効率化、データ利用の効率化、推論の効率化の4つの観点から研究を進めている
・外部知識を利用するモデルや計算コストの増大を抑えながらモデル容量を増大させるMoE、Attentionの計算コストを抑えるTransformersの改良を行った
2.効率的なアーキテクチャ
以下、ai.googleblog.comより「Google Research, 2022 & beyond: Algorithms for efficient deep learning」の意訳です。元記事は2023年2月7日、Sanjiv Kumarさんによる投稿です。
Jeff Deanの初回投稿時の計画ではアルゴリズム編は1部だったはずですが「ディープラーニング用モデルの効率を向上させるアルゴリズム編」と「その他の先進的なアルゴリズム編」の2部構成に分割されて、その前編です。はい、そうです、皆さん、直近の大規模言語モデルや画像生成モデルの話題でお腹いっぱいかもしれませんが、まだ去年の復習終わってませんからね~。
アイキャッチ画像は、Waifu Diffusion 1.5 Betaのカスタムモデルによる生成で、MoE(Mixture-of-Experts)より連想したいわゆる「萌え」の定義をwikipediaで調べ、猫の耳やメイドの衣装などの物理的なパーツが構成要素との説を元にナウシカ先生に頼み込んで着てもらったイラスト。
(本記事は、Googleの様々な研究分野を取り上げるシリーズの第4部です。このシリーズの他の記事は第1部「2022年のGoogleのAI研究の成果と今後の展望~言語・視覚・生成モデル編~」からご覧いただけます)
10年前のディープラーニングの爆発的な普及は、新しいアルゴリズムとアーキテクチャの融合、データの著しい増加、より巨大な計算機が利用可能になった事でもたらされた部分があります。
この10年間で、AIとMLモデルはより大きく、より洗練されたものになりました。より深く、より複雑で、より多くのパラメータを持ち、より多くのデータで学習され、機械学習の歴史上最も革新的な結果をもたらしました。
これらのモデルが本番環境やビジネス・アプリケーションに導入される機会が増えるにつれ、モデルの効率とコストは、些細な考慮事項から主要な制約事項へと変化してきました。
これに対し、GoogleはMLの効率化に多大な投資を続けており
(a)効率的なアーキテクチャ
(b)学習効率
(c)データ効率
(d)推論効率
における最大の課題に挑んでいます。効率性以外にも、これらのモデルには、事実性、安全性、プライバシー、鮮度に関する多くの課題がありますが、それらは「その他の先進的なアルゴリズム編」で扱います。以下では、上記の課題に対処するための新しいアルゴリズムの開発におけるGoogle Researchの一連の研究を紹介します。
効率的なアーキテクチャ
根本的な疑問は「より効率的にモデルをパラメータ化する良い方法はないのだろうか?」ということです。2022年、私たちは、外部から得た知識(context)を活用するモデルの拡張、Mixture-of-Experts、大規模MLモデルの中核をなすtransformersの効率化など、新しい技術に注目しました。
外部知識を利用するモデル
より高い品質と効率を追求するために、ニューラルモデルは大規模データベースや学習可能なメモリから得た文脈情報で補強することができます。取得した文脈情報を活用することで、ニューラルネットワークはその内部パラメータに含まれる膨大な量の世界の知識を記憶する必要がなくなり、パラメータの効率、解釈性、事実性の向上につながります。
論文「Decoupled Context Processing for Context Augmented Language Modeling」では、エンコーダとデコーダを分離したアーキテクチャに基づき、言語モデルに外部から文脈を取り込むためのシンプルなアーキテクチャを検討しました。
これにより、自動回帰言語モデリング(auto-regressive language modeling)や質問領域に制限を設けない質問回答(open domain question answering)タスクで競争力のある結果を得ながら、大幅な計算量削減を実現しました。
しかし、事前に学習された大規模言語モデル(LLM:Large Language Model)は、大規模な学習セットに対する自己教師を通して、かなりの量の情報を吸収しています。しかし、このようなモデルの「世界に関する知識(world knowledge)」が提示された外部からの文脈とどのように相互作用するかは、正確には不明です。私達は「知識を意識した微調整(KAFT:Knowledge Aware Fine-Tuning)」により、標準的な教師付きデータセットに反事実的(counterfactual)、及び無関係な文脈を取り込むことで、LLMの制御性と堅牢性の両方を強化しました。
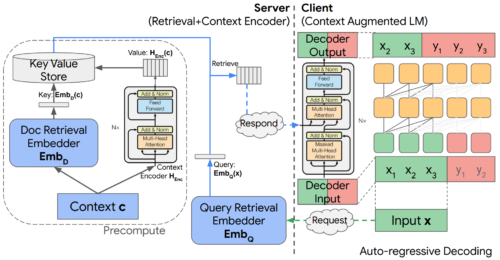
文脈を取り込むためのエンコーダ・デコーダcross-attentionメカニズムにより、文脈のエンコードと言語モデルの推論を切り離し、効率的な文脈補強型モデル(context-augmented models)を実現することができます。
モジュール型ディープネットワークの探求における疑問の一つは、概念データベースとヤリトリをする計算モジュールをどのようにして設計できるか?ということです。
私達は、外部のLSH(Locality Sensitive Hashing)テーブルに格納されたスケッチ(Tensor sketch)と、そのスケッチを処理するモジュールへのポインタという形で「イベントを記憶」する理論的なアーキテクチャを提案しました。
文脈補強型モデルにおけるもう一つの課題は、大規模なデータベースからアクセラレータ上で情報を高速に検索することです。
私たちは、TPUの性能モデルに合わせ、期待される再現性(recall)を解析的に保証し、ピーク性能を達成するTPUベースの類似性検索アルゴリズム(similarity search algorithm)を開発しました。
探索アルゴリズムは通常、多数のハイパーパラメータと設計上の選択を伴うため、新しいタスク用にチューニングすることが困難です。
私達は、ハイパーパラメータのチューニングを自動化するための新しい制約付き最適化アルゴリズムを提案しました。提案したアルゴリズムは、入力として希望するコストまたは再現率を固定し、経験的に速度-再現率のパレートフロンティア(Pareto frontier)に非常に近いチューニングを生成し、標準的なベンチマークでトップクラスの性能を実現するものです。
専門家混合(MoE:Mixture-of-experts)モデル
専門家混合(MoE)モデルは、計算コストを過度に増大させることなく、ニューラルネットワークモデルの容量を増大させる効果的な手段であることが証明されています。
MoEの基本的な考え方は、多数の専門家サブネットワークからネットワークを構築し、各入力を適切な専門家のサブセットによって処理することです。
そのため、標準的なニューラルネットワークと比較して、MoEはモデル全体のごく一部を呼び出すだけで、GLaMなどの言語モデルアプリケーションで示されているように、高い効率を実現することができます。

GLaMのアーキテクチャは、各入力トークンを64の専門家ネットワークの中から選択された2つのネットワークに動的にルーティングし、予測を行うものです。
与えられた入力に対してどの専門家をアクティブにするかはルーティング関数によって決定されますが、各専門家の過少利用・過剰利用の両方を防ぐように設計する事は困難です。私達は、各入力トークンを上位k人の専門家に割り当てるのではなく、各専門家を上位kトークンに割り当てる新しいルーティング機構「Expert Choice Routing」を最近提案しました。
これにより、専門家の負荷分散が自動的に行われる一方で、1つの入力トークンを複数の専門家が処理することも自然に可能になります。
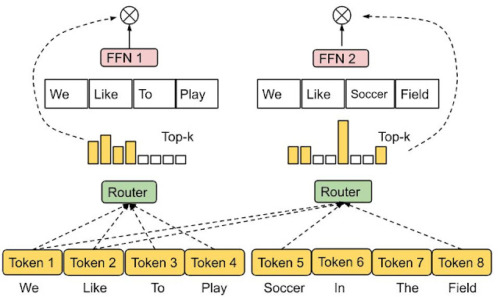
専門家選択ルーティング(Expert Choice Routing)
あらかじめ決められたバッファ容量を持つ専門家に上位kトークンが割り当てられるため、均等な負荷分散が保証されます。各トークンは可変数の専門家によって処理されることができます。
効率的なTransformers
Transformersは、視覚から自然言語理解までの様々な難問において顕著な成功を収めてきた、汎用的なsequence-to-sequenceモデルです。
このようなモデルの中心的な構成要素はAttention層であり、「クエリー」と「キー」の類似性を識別し、これらを用いて「値」の適切な重み付き組み合わせを構築するものです。Attention機構は効果的ではありますが、シーケンス長に対する規模拡大性能が悪い(つまり2次関数的に負荷が増大)です。
Transformersの規模が大きくなるにつれて、学習済モデル内に自然発生的な構造やパターンがあるかどうかを研究することは、Transformersの仕組みを読み解く際に興味深いことです。
この解明に向けて、私達は中間MLP(Multi Layer Perceptron)レイヤーにおける学習済みembeddingsを研究し、それらが非常にスパース(sparse)、つまり疎らであることを明らかにしました。
例えば、T5-Largeモデルではゼロでない成分が1%未満です。さらに、スパース性は、モデルの性能に影響を与えることなく、FLOPsを削減できる可能性を示唆しています。
私達は最近、Treeformerを提案しました。これは決定木に依存する、標準的なAttention計算の代替手法です。直感的には、これはクエリに関連するキーの小さな部分集合を素早く特定し、この集合に対してのみアテンション演算を実行します。
経験的に、TreeformerはAttention層のFLOPsを30倍削減することができます。また、Attentionと貪欲アルゴリズム(greedy algorithm)を組み合わせた微分可能な特徴選択法である逐次注意(Sequential Attention)も紹介しました。この手法は、線形モデルに対して強い証明可能な保証を持ち、大規模なembeddingモデルにもシームレスに規模拡大できます。
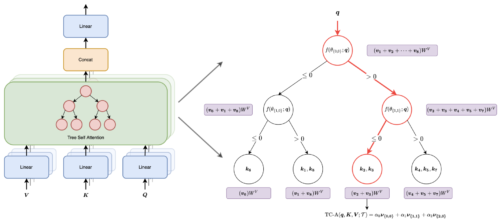
Treeformerでは、Attentionの計算が最近傍探索問題としてモデル化されています。階層的な決定木を用いて、各クエリに対してどのキーに注意を払うべきかを見つけ、古典的なAttentionの二次関数的コストを大幅に削減することができます。
Transformersを効率化するもう一つの方法は、Attention層でのソフトマックス計算を高速化することです。
ソフトマックスカーネルの低ランク近似に関する以前の研究を基に、私達は新しいランダム特徴のクラスを提案しました。
これは、ソフトマックスカーネルの最初の「正で境界のある」ランダム特徴量の近似を提供し、シーケンス長に対して計算上線形です。
また、因果関係や相対位置符号化などの様々なAttentionマスキング機構をスケーラブルに(すなわち、入力配列長に対して二次関数以下に)取り込むためのアプローチを初めて提案しました。
1.2022年のGoogleのAI研究の成果と今後の展望~ディープラーニング用モデルの効率を向上させるアルゴリズム編~(1/3)関連リンク
1)ai.googleblog.com
Google Research, 2022 & beyond: Algorithms for efficient deep learning
2)arxiv.org
Decoupled Context Processing for Context Augmented Language Modeling
Large Language Models with Controllable Working Memory
Provable Hierarchical Lifelong Learning with a Sketch-based Modular Architecture
Automating Nearest Neighbor Search Configuration with Constrained Optimization
Treeformer: Dense Gradient Trees for Efficient Attention Computation
Sequential Attention for Feature Selection

