
1.2022年のGoogleのAI研究の成果と今後の展望~責任あるAI編~(1/2)まとめ
・学習させた状況下ではうまく機能するが新しい状況下では堅牢、あるいは公平でない仕様不足問題を研究した
・年齢や性別などな属性から因果関係を学んで抜け道を学習してしまう事が原因であり軽減策を研究した
・意図しない偏見を検出するために顕著性を使用する方法や肌色の表現についても研究成果を発表している
2.Google AIの2022年の振り返り~責任あるAI編~
以下、ai.googleblog.comより「Google Research, 2022 & beyond: Responsible AI」の意訳です。元記事の投稿は2023年1月24日、Marian Croakさんの投稿です。
アイキャッチ画像はstable diffusionのカスタムモデルによる生成。責任ある=CEO的な自信に満ち溢れる表情で燃え盛る炎のような情熱をイラスト化した所までは悪くなかったと思うのです。しかし、左側にアウトペインティングしたら、テトが枯れ木の上に乗ってしまったので、山火事を起こして途方に暮れているようにも見えてきてしまったナウシカ。やはり、AIでイラストを構想通りに仕上げるのは中々難しいです。
(本記事は、Googleの様々な研究分野を取り上げるシリーズの第2部です。このシリーズの他の記事は第一部「2022年のGoogleのAI研究の成果と今後の展望~言語・視覚・生成モデル編~」からご覧いただけます)
昨年は、人工知能(AI:Artificial Intelligence)、特に大規模言語モデル(LLM:Large Language Models)とテキストから画像を生成するモデルにおいて、驚異的な進展を示しました。
このような技術の進歩には、開発・導入の方法について熟慮し、意識しながら行うことが必要です。このブログでは、私たちが過去1年間に研究全体で取り組んできた責任あるAI(Responsible AI)へのアプローチ方法と、2023年に私たちが目指す方向性について紹介します。私たちのAI原則(AI Principles)に則り、責任ある倫理的な方法でAI製品を構築するというコミットメントの一環として、基礎研究、社会技術研究、応用研究、製品ソリューションの4つの主要テーマを取り上げます。
– テーマ1:責任あるAI研究の推進
– テーマ2:製品における責任あるAI研究
– テーマ3:ツールおよび技法
– テーマ4:AIの社会的便益の実証
テーマ1:責任あるAI研究の推進
機械学習研究
機械学習(ML:Machine Learning)システムを実世界で利用する場合、期待した動作をしないことがあり、その結果、実現される利益が減少することがあります。私たちの研究は、予期しない振る舞いが発生する可能性がある状況を特定し、望ましくない結果を軽減できるようにするものです。
私達は、いくつかのタイプのMLアプリケーションにおいて、モデルがしばしば仕様不足(underspecified)になる事を示しました。
つまり、学習させた状況下ではうまく機能しますが、新しい状況下では堅牢でない、あるいは公平でない可能性があるということです。
これが起こる理由は、モデルが「偽の相関関係(spurious correlation)」、つまり一般化できない特定の副作用に依存しているからです。このことは、MLシステム開発者にとってリスクであり、新しいモデル評価手法が求められています。
私達は、ML研究者が現在使用している評価手法を調査し、MLの一般的な落とし穴に対処する研究において改善された評価指標を導入しました。私達は、MLシステムの堅牢性の欠如や、年齢や性別などの敏感な属性への依存につながる因果関係の「抜け道(shortcuts)」を軽減する技術を特定し、実証しました。
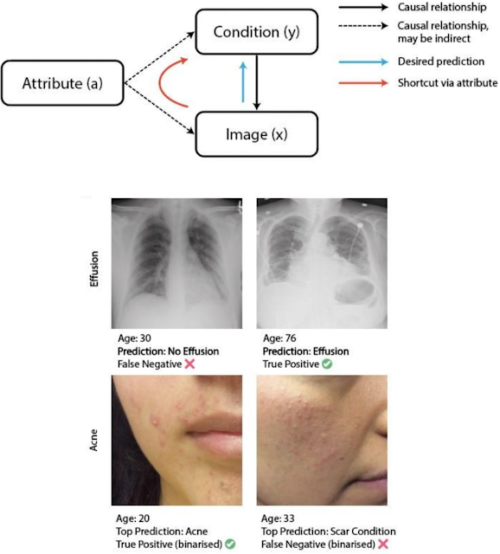
抜け道学習(Shortcut learning)
年齢を元に医療診断をしてしまっています。
堅牢性の問題の原因と緩和策をより良く理解するために、私達は特定の領域におけるモデル設計をより深く掘り下げることにしました。コンピュータビジョンでは、新しいvision transformerモデルの堅牢性を研究し、その堅牢性を向上させるための新しい負のデータ増強技術を開発しました。自然言語タスクについても同様に、データ分布の違いによって異なるグループ間の汎化がどのように向上するか、また、アンサンブルや事前学習済みのモデルがどのように役立つかを調査しました。
また、より包括的なモデルを構築するための技術開発も、私たちのML研究の主要な部分です。例えば、私たちは、予測結果の共同所有や、デリケートなトピックを公開するかどうかの選択を可能にする参加型システムを使って、いつ、なぜ私たちの評価が不十分なのかを理解するために、外部のコミュニティに目を向けています。
社会技術研究
AIの開発・評価に多様な文化的背景や声を取り入れるため、私たちはコミュニティベースの研究活動を強化し、AIが代表的な事例を知らない、あるいは不公平な結果を経験する可能性がある特定のコミュニティに焦点を当てました。
特に、自然言語や性差を含む健康などの文脈における不当なジェンダーバイアスの評価について検討しました。この研究は、私たちのテクノロジーが、性的なアウトサイダー(queer)や第三の性(nonbinary gender)のアイデンティティを持つ人々の害を評価し軽減できるよう、不当なジェンダーバイアスのより正確な評価を進めています。
公平性の向上と並行して、私たちは文化的に包括的なAIを開発するための大規模な取り組みにおいても重要なマイルストーンを達成しました。私たちは、AIにおける異文化への配慮の重要性を提唱しています。
特に、AIに対するユーザーの態度や説明責任のメカニズムにおける文化的差異についてです。また、南北格差問題(global south)に焦点を当て、文化的状況に応じた評価を可能にするデータと技術を構築しました。
また、様々な文脈における機械翻訳のユーザー体験を説明し、その改善のための人間中心的な機会を提案しました。
人間中心の研究
Google では、人間中心の研究と設計の推進に力を入れています。最近、私たちは、LLMを使用して、新しいAIベースの連携方法をプロトタイプ化する方法を示しました。
また、研究コミュニティに重要なアイデアやガイダンスを紹介する5つの新しいインタラクティブな探索可能なビジュアライゼーションを発表しました。
また、MLモデルで意図しない偏見を検出するために顕著性(saliency)を使用する方法や、生のデータがデバイスから送信されることなく複数のユーザーからのデータでモデルを共同で訓練するために連合学習(federated learning)を使用する方法など、研究コミュニティへの重要なアイデアやガイダンスを紹介する5つの新しい連携方法と探索可能な可視化資料を公開しました。

解釈可能性(interpretability)の研究では、言語モデルの振る舞いを学習データ自体にまで遡って追跡する方法、モデルが注目する点の違いを比較する新しい方法、出現した振る舞いを説明する方法、モデルによって学習された人間が理解しやすい概念を特定する方法などを提案しました。
また、推薦システムにおいて、自然言語による説明を用いて、人間が理解しやすく、推薦内容を制御しやすい新しい手法を提案しました。
創造性とAI研究
私たちは、急速に変化するAIテクノロジーと創造性の関係について、クリエイティブチームとの対話を開始しました。クリエイティブな執筆の分野では、Google の PAIR チームと Magenta チームがクリエイティブな執筆のための斬新なプロトタイプを開発し、作家のワークショップを進行して、クリエイティブな執筆を支援する AIの可能性と限界について探りました。
多様なクリエイティブな著者によるストーリーは、ワークショップの洞察とともに、作品集として出版されました。ファッションの分野では、ファッションデザインと文化的表現の関係を探り、音楽の分野では、音楽用AIツールのリスクと可能性の検討を開始しました。
テーマ2:製品における責任あるAI研究
自分の周りの世界に自分が映っていることを確認できることは重要ですが、画像ベースのテクノロジーはしばしば公平な表現に欠け、有色人種は見過ごされ、不正確な表現をされていると感じることがあります。
Google では、Google 製品全体で多様な肌色(skin tones)の表現を改善する取り組みに加え、世界中のさまざまな肌色をより包括的に表現するために設計された新しい肌色尺度を導入しました。
ハーバード大学教授で社会学者のDr. Ellis Monkと提携し、モンクスキントーン(MST:Monk Skin Tone)尺度を発表しました。この尺度は、研究コミュニティや業界の専門家が研究や製品開発に利用できる10段階評価尺度です。さらに、この尺度は、Google製品の機能に組み込まれ、画像検索やGoogleフォトのフィルターにおける多様性と肌色の表現を向上させるための長い取り組みを続けています。

モンクスキントーンの10階調
これは、責任あるAI研究が社内の製品と密接に連携して研究に情報を提供し、新しい技術を開発している多くの例の一つです。別の例では、自然言語による反事実データ拡張(counterfactual data augmentation、実際には起こっていなくとも特定の条件下で起こり得る事を念頭に行うデータ拡張)に関する過去の研究を活用してセーフサーチを改善し、特に民族、性的指向、ジェンダーに関連する検索で、予期せぬ衝撃的な検索結果を30%削減しました。
ビデオコンテンツのモデレーションを改善するため、人間の評価者がポリシー違反の可能性が高い長いビデオの特定箇所に注意を集中できるよう、新しいアプローチを開発しました。また、推薦システムにおいて、ユーザーや用途の多様性を考慮し、より正確な平等性の評価方法を開発するための研究を続けています。
大規模モデルの分野では、GLaM、PaLM、Imagen、Partiなどのモデルについて、モデルカードやデータカード(詳細は後述)、Responsible AIベンチマーク、社会的インパクト分析などを作成し、開発プロセスの一部としてResponsible AIのベストプラクティスを取り入れました。
また、Responsible AIベンチマークでは、指示の微調整(instruction fine-tuning)により多くの改善が見られることを示しました。
生成モデルは人間が注釈付けしたデータで学習・評価されることが多いため、評価者の不一致や評価者の多様性など、人間を中心とした考察に重点を置きました。また、他のシステムにおける信頼性を向上させるために大規模モデルを用いた新しい能力についても発表しました。例えば、言語モデルによって、より複雑な反事実データを生成し、反事実データの公正さを探る方法を検討しました。2023年も引き続きこれらの分野に注力し、下流のアプリケーションへの影響も理解していきます。
3.2022年のGoogleのAI研究の成果と今後の展望~責任あるAI編~(1/2)関連リンク
1)ai.googleblog.com
Google Research, 2022 & beyond: Responsible AI
2)pair.withgoogle.com
Measuring Fairness

