
1.Google Research:2020年の振り返りと2021年以降に向けて(4/5)まとめ
・アルゴリズム基礎は主に本業の広告オークション関係で注目すべき結果が多かった
・機械知覚は音声と映像を組み合わせて学習する等のマルチモーダルな手法が躍進
・ロボット工学も強化学習などを利用して自律的に学習させる手法が進化しつづけている
2.アルゴリズム理論、機械知覚、ロボティクス、量子コンピュータ
以下、ai.googleblog.comより「Google Research: Looking Back at 2020, and Forward to 2021」の意訳です。元記事の投稿は2021年1月12日、Jeff Deanによる投稿です。
アイキャッチ画像のクレジットはPhoto by Roberto Nickson on Unsplash
(13)アルゴリズムの基礎と理論
2020年は、アルゴリズムの基礎と理論における私達の研究にとって生産的な年であり、いくつかの影響力のある研究出版物と注目すべき結果がありました。最適化の面では、edge-weighted online bipartite matchingに関する論文で、オンライン競合アルゴリズム(competitive algorithm)の新しい手法を開発しています。これは、効率的なオンライン広告割り当てにエッジ加重バリアントを適用する事で、30年前の未解決の問題を解決します。
オンライン割り当てにおけるこの研究に加えて、多様性を追加したさまざまなモデルに一般化するデュアルミラー降下技術を開発しました。そして、公平性の制約、およびオンラインスケジューリング、オンライン学習、オンライン線形最適化におけるMLアドバイスを含む、オンライン最適化のトピックに関する一連の論文を公開しました。
別の研究結果は、密グラフでの古典的な二部マッチングに50年ぶりの改善をもたらしました。 最後に、別の論文が、凸体をオンラインで追跡することに関する長年の未解決の問題を解決しています。まさかの聖書から得たアルゴリズムを使用します。
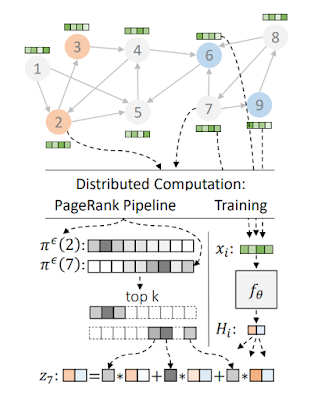
また、規模拡大可能なグラフマイニングとグラフベースの学習の作業を継続し、NeurIPS’20でGraph Mining&Learning at Scale Workshopを開催しました。これは、グラフクラスタリング、グラフembedding、因果推論、グラフニューラルネットワークなどの規模拡大可能なグラフアルゴリズムの作業をカバーしていました。
ワークショップの一環として、BigTableに似た分散ハッシュテーブルでMapReduceのような標準の同期計算フレームワークを拡張することにより、理論と実践の両方で、いくつかの基本的なグラフの問題をより速く解決する方法を示しました。
私たちの広範な実証研究は、階層的クラスタリングと連結成分の大規模な並列アルゴリズムで分散ハッシュテーブルを使用することに触発されたAMPCモデルの実際的な関連性を検証しました。そして、私たちの理論的結果は、一定の分散ラウンドでこれらの問題の多くを解決する方法を示しており、以前の結果を大幅に改善しています。
また、PageRankとランダムウォークの計算で指数関数的な高速化を実現しました。 グラフベースの学習側では、機械学習で使用するグラフを設計するためのフレームワークであるGraleを紹介しました。 さらに、よりスケーラブルなグラフニューラルネットワークモデルに関する作業を紹介しました。ここでは、PageRankを使用してGNNの推論を大幅に加速できることを示しています。
コンピュータサイエンスと経済学が交差する領域である市場アルゴリズムでは、広告オークションのインセンティブ特性の測定、両面市場、広告選択における注文統計の最適化など、改善されたオンライン市場の設計に関する研究を続けました。
繰り返えしオークションの分野では、現在の市場および/または将来の市場の予測または推定エラーの欠如に対して動的メカニズムを堅牢にするフレームワークを開発しました。これは、しっかりとした後悔の少ない動的メカニズムにつながります。その後、幾何学的基準を用いて漸近的に最適な目的を達成することが可能な場合を特徴付けました。
また、実際に使用されている様々な予算管理戦略の平衡結果を比較し、収益と買い手の効用のトレードオフに与える影響を示し、それらのインセンティブ特性を明らかにしました。
さらに、最適なオークションパラメータの学習に関する研究を継続し、収益損失を伴うバッチ学習の複雑さを解決しました。また、文脈に応じたオークション価格設定のための最適後悔の設計と組合せ最適化の研究を行い、オークションのための新しい能動学習フレームワークを開発し、ポストプライスオークションの近似を改良しました。
最後に、広告オークションにおけるインセンティブの重要性に触発され、広告主がオークションにおけるインセンティブの影響を研究するのに役立つことを期待して、メカニズムがどれだけインセンティブの互換性から逸脱しているかを定量化するためのデータ駆動型の指標を紹介しました。
(14)機械の知覚
私たちを取り巻く世界の知覚は、日常生活の向上に役立つ可能性を秘めた研究分野であり続けています。これらには視覚や聴覚をモデル化し、行動に繋げ、複数種のコミュニケーション手段を入力として理解する事が含まれます。
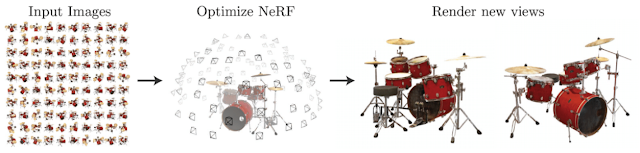
2020年には,ディープラーニングが,3Dコンピュータビジョンとコンピュータグラフィックスをより身近なものにする新しいアプローチを後押ししました。CvxNet、3D形状のための深層暗黙関数や、ニューラルボクセルレンダリング、そしてCoReNetは、この方向性を示す小数の具体例です。
さらに、風景をニューラルラジアンスフィールドとして表現する私たちの研究(別名:NeRF、dellaert.github.ioを参照)は、Google Researchの学術的なコラボレーションが、ニューラルボリュームレンダリングの分野における急速な進歩をいかに促進するかを示す好例です。
カリフォルニア大学バークレー校とのコラボレーションである「Learning to Factorize and Relight a City」では、屋外風景を時間的に変化する照明と永続的な風景要素に解きほぐすための学習ベースのフレームワークを提案しました。これにより、ストリートビューパノラマの照明効果や風景の形状を変更したり、1日の変遷をタイムラプスビデオにすることさえできます。

人型形状と関節のあるポーズモデルの生成に関する私たちの仕事は、完全に訓練可能なモジュール式の深層学習フレームワーク内に、統計的で関節のある3D人間の形のモデリングパイプラインを導入します。このようなモデルにより、1枚の写真から人間の3Dポーズと形状を再構築して、シーンをよりよく理解することができます。
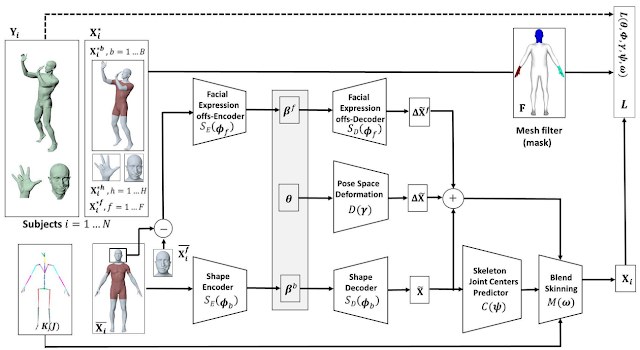
論文「GHUM & GHUML: Generative 3D Human Shape and Articulated Pose Models」で発表されたエンドツーエンドの統計的3D関節式人間形状モデル構築の概要
ニューラルネットワークを使用したメディア圧縮(訳注:通常の圧縮は文書等も圧縮対象だが、メディア圧縮は特に画像や音声等のサイズが大きくなりがちなメディアを対象とした圧縮技術の事)分野での進展は、学習による画像圧縮(learned image compression)だけでなく、ビデオ圧縮、ボリューム圧縮への深いアプローチ、歪みにとらわれない画像透かしなど、2020年も力強い進歩を続けました。

歪みにとらわれない深い画像透かしでエンコードされた画像とカバー画像のサンプル
最初の行:透かしが埋め込まれていないカバー画像
2行目:HiDDeN結合歪みモデルで透かしが埋め込まれた画像
3行目:私達のモデルで透かしが埋め込まれた画像
4行目:HiDDeN結合モデルの透かし画像とカバー画像の差異の正規化
5行目:私達のモデルの差異の正規化
知覚研究におけるその他の重要なテーマは次のとおりです。
・データをより有効活用
(例:ノイズ入りラベルから学習した生徒(noisy students)を使った自己学習、シミュレートされたデータからの学習、ノイズ入りラベルを使った学習、対照学習)
・異なるコミュニケーション手段間の推論(Reasoning across modalities)
(例:クロスモーダルな教師、視聴覚情報をヒントに声だけ音量を上げる、実地言語(language grounding)、局所化された物語(視覚と言語を繋げるマルチモーダルな注釈)を特徴とする Open Images V6のアップデート)
・特にエッジデバイスでの効率的な認識のためのアプローチの開発(例:高速疎畳み込み、モデル圧縮のための構造化マルチハッシュ)
・物体と風景の特徴表現および推論する機能の向上(例:3D物体の検出と3D形状の予測、単一のRGB画像からの3D風景の再構築、物体検出のための時間的推移の活用、透明な物体を正確に認識できる学習法、ステレオ画像からのポーズ推定)
・人間の創造性を可能にするAI(例:ウェブページからの動画を自動作成、重要な部分を認識して動画を自動でリフレーミング、GANを使用した幻想的な生き物の作成、撮影後にポートレート写真の照明を変更)
ソリューションとデータセットをオープンソースとして公開して広範な研究コミュニティと連携することは、知覚研究を促進するためのもう1つの重要な側面です。
2020年に、MediaPipeで複数の新しい知覚推論機能とソリューションをオープンソース化しました。これはオンデバイスで、顔や手やポーズの予測、リアルタイムに体のポーズの追跡、リアルタイムで眼球の虹彩の追跡と深度の推定、リアルタイムの3Dオブジェクト検出などを可能にします。

MLベースのソリューションを通じて、モバイルデバイスでのユーザ体験を改善し、有用性を促進するために、引き続き前進しました。洗練された自然言語処理をデバイス上で実行し、より自然な会話機能を可能にする私達の能力は、向上し続けています。
2020年に、Call Screen(訳注:未登録電話番号からの着信を最初にAIが受け答えしてくれるアプリ)を拡張し、Hold for Me(訳注:フリーダイヤルにかけて待たされた時にAIに任せる事が出来て繋がったらお知らせしてくれるアプリ)を起動して、ユーザーが日常的なタスクを実行する時間を節約できるようにしました。
また、生産性を高めるために、Recorderアプリを使って録音した音声データの内容をどこに何が録音されているかわかるようにする事や、言葉を使ってスマートフォン操作を案内する機能も開発しました。
GoogleのDuplexテクノロジーを使用して、企業に電話をかけたり、一時的な閉鎖などを確認したりしています。これにより、世界中で300万件のビジネス情報を更新できるようになりました。これらの情報は、GoogleマップとGoogle検索で200億回以上確認されています。また、テキスト読み上げテクノロジーを使用して、Googleアシスタントが42の言語をサポートし、音声で読み上げる事でウェブページに簡単にアクセスできるようにしました。
また、イメージングアプリケーションに有意義な改善を続けました。革新的なコントロールと、Googleフォトでそれらを再照明、編集、強化、再現する新しい方法により、Pixelで貴重な瞬間を簡単に撮影できるようになりました。
Pixel搭載カメラには、Pixel 4と4aから、Live HDR +を追加しました。これにより機械学習を使用して、ビューファインダーでHDR +バースト写真の鮮やかさとバランスの取れた露出と外観をリアルタイムに確認できるようになります。また、風景内のシャドウとハイライトの明るさを個別に調整できるデュアル露出コントロールを実装しました。
最近では、Pixel CameraアプリとGoogleフォトアプリのキャプチャ後の新しい機能であるPortraitLightを導入しました。これは、シミュレートされた指向性光源をポートレート写真に追加します。この機能も、機械学習を利用しており、非常にクールな331のLEDで構成される Light Stage computational illumination systemで一度に1つずつのライトを使って70人の異なる人々を対象に撮影したデータを使ってトレーニングしています。
昨年、Googleの研究者は、Google製品を使用した多くの新しい(そしてタイムリーな手法に貢献する事に興奮していました。以下にいくつかの例があります
・Google Lens等のアップデートにより、拡張現実を介して宿題を手伝ったり、3Dで概念を探索したりするのを簡単にしました。
・GoogleMeetのブラウザ内の背景のぼかしや置換による仮想会議の改善

・自宅で製品を仮想的に試すための新しい方法を強化します。

・動画の重要な瞬間を認識する事で、最も関連性の高いコンテンツにすばやくアクセスできるようにします。
・ハミングすることによってあなたが思い出せないその曲を見つける事を手伝います。
・YouTubeが人間によるレビューのために潜在的に有害なコンテンツを特定する事を支援しました。
・YouTubeクリエイターの声を自動的に高め、バックグラウンドノイズを減らすことで、より良い動画を作成できるようにしました。
(15)ロボット工学
ロボット工学の研究の分野では、投稿で前述したRL手法の多くを使用して、ますます少ないデータで、ますます複雑で安全かつ堅牢なロボットの動作を学習する能力が大幅に向上しました。
Transporter Networksは、ロボットタスクを空間変位として表現する方法を学習するための新しいアプローチです。環境内の絶対位置ではなく、物体とロボットアームの先端(end-effector)間の関係を表すことで、作業空間内での堅牢な変換を非常に効率的に学習できます。
![]()
Grounding Language in Playでは、自然言語の指示に従うようにロボットを教える方法を示しました(多数の言語で!)。
これには、自然言語を使った指示とロボットの動作をペアにしたデータを収集するための規模拡大可能なアプローチが必要でした。重要な洞察の1つは、ロボット操作者にロボットで遊ぶように依頼し、その後、どのような指示がロボットに同じ動作を実行させるかをラベル付けすることで、これを達成できたということです。

また、ロボットを完全に使わずに(人間にカメラ付きの把持棒を持たせる事により)、更に規模拡大したデータ収集を実現し、ロボットタスク間で視覚的特徴表現を効率的に転移する方法についても検討しました。
自然界からインスピレーションを得る事、進化的メタ学習戦略、人間のデモンストレーションおよび深層強化学習を使用してデータ効率の高いコントローラーをトレーニング、など様々なアプローチを使用して、ロボット移動を非常に機敏に動かす戦略を学習する方法を調査しました。

今年、安全性の重要性が更に強調されました。
現実の世界で安全な配達用ドローンをどのように配備できるのでしょうか?
ロボットが常にミスから回復できるようにするためには、どのようにして世界を探索すれば良いのでしょうか?学習した行動の安定性を何を用いて証明しますか?これらは重要な研究分野であり、今後ますます注目が集まると予想されます。
(16)量子コンピューティング
私達の量子AIチームは、量子コンピューティングの実用的な使用法を確立するための作業を続けました。 化学と物理学に関連するシステムをシミュレートするために、Sycamoreプロセッサで実験アルゴリズムを実行しました。
これらのシミュレーションは、古典的なコンピューターでは実行不可能な量の計算規模に近づいており、量子効果を重要なシステムをシミュレートする効率的な手段にして量子コンピューターを実現するというファインマンの当初のアイデアをうまく利用しています。
例えば、正確なプロセッサキャリブレーションを実行したり、量子機械学習の利点を示したり、量子強化最適化をテストしたりするために、新しい量子アルゴリズムを公開しました。 また、量子アルゴリズムの表現を容易にするためのプログラミングモデルにも取り組みました。GoogleCloudで最大40量子ビットの量子アルゴリズムを開発およびテストするための効率的なシミュレーションツールであるqsimをリリースしました。
私達は、普遍的なエラー修正を実装した量子コンピューターの構築に向けたロードマップに従っています。次のマイルストーンは、量子誤り訂正が実際に機能することの実証です。これを実現するために、量子ビット、カプラー、I/Oデバイスなどの個々のコンポーネントに欠陥がある場合でも、量子ビットの大きなグリッドが小さなグリッドよりも指数関数的に長く論理情報を保持できることを示します。また、プロセッサ製造の速度と品質を大幅に向上させる独自のクリーンルームができたことにも特に興奮しています。
3.Google Research:2020年の振り返りと2021年以降に向けて(4/5)関連リンク
1)ai.googleblog.com
Google Research: Looking Back at 2020, and Forward to 2021
2)research.google
Publication database
