
1.YouTubeストーリーで人の声だけ音量を上げる(1/2)まとめ
・バックグラウンドノイズが大きいビデオでは被写体のスピーチが曖昧になり理解しにくい
・Looking to Listenは音声と口の動きなどの視覚信号を使い特定の人の音声を分離可能
・YouTubeストーリー(iOS)の新しい音声強調機能としてLooking to Listenが利用可能に
2.Looking to Listenの実践投入
以下、ai.googleblog.comより「Audiovisual Speech Enhancement in YouTube Stories」の意訳です。元記事の投稿は2020年10月1日、Inbar MosseriさんとMichael Rubinsteinさんによる投稿です。
元となった技術のLooking to Listenが発表されたのは2018年4月なので、BERTもそうですが、発表から2年ちょっと経つと現実社会で使われるようになってきますね。
アイキャッチ画像のクレジットはPhoto by Anastase Maragos on Unsplash
スマートフォンのカメラで撮影したビデオの品質を向上させるために多大な努力が払われていますが、ビデオのオーディオの品質は見過ごされがちです。
例えば、複数の人が話している、またはバックグラウンドノイズが大きいビデオでは被写体のスピーチは、曖昧になったり、歪んだり、理解しにくい場合があります。
これに対処するために、2年前にLooking to Listenを発表しました。これは、視覚と音声の両方の手がかりを使用して動画の被写体の音声を分離する機械学習(ML:Machine Learning)テクノロジーです。
オンラインビデオの大規模なコレクションでモデルをトレーニングすることにより、音声と、口の動きや顔の表情などの視覚信号との相関関係を捕捉し、ビデオ内の特定の人の音声を別の人の音声から分離したり、音声を背景音から分離するために使用できます。
このテクノロジーは、音声の分離と増強において最先端の結果(音声のみのモデルに比べて1.5dBの顕著な改善)を達成しただけではなく、特に、複数の人が話している場合は、音声のみの処理よりも結果を改善できました。これは、ビデオの視覚的な手がかりが、誰が何を言っているかを判断するのに役立つためです。
YouTubeストーリー(iOS)の新しい音声強調機能としてユーザーがLooking to Listenテクノロジーを利用できるようになりました。
これにより、クリエイターは自動的に声を強調し、バックグラウンドノイズを減らす事で、より良い自撮り動画を撮ることができます。
このテクノロジーをユーザーの手に渡すのは簡単なことではありませんでした。過去1年間、私たちはユーザーと緊密に協力して、ユーザーがこの機能をどのように使用したいか、どのようなシナリオで、どのように音声と背景音のバランスを動画に取り入れたいかを学びました。
「Looking to Listen」モデルを大幅に最適化して、モバイルデバイスで効率的に実行できるようにしました。これにより、論文が発表された当時のリアルタイム実行時間をデスクトップで1/10、スマートフォンで1/2に短縮されました。
また、このテクノロジーを広範なテストにかけ、さまざまな録音条件で、様々な外観や声の人々に対して一貫して機能することを確認しました。
研究から製品へ
モバイルデバイスで高速で堅牢な操作を可能にするためにLooking to Listenを最適化するには、多くの課題を克服する必要がありました。
まず、処理時間を最小限に抑え、ユーザーのプライバシーを保護するために、すべての処理をオンデバイス、つまりスマホアプリ内で実行する必要がありました。つまり、オーディオまたはビデオ情報は、処理を行うためにクラウドサーバに送信される事はありません。
更に、ビデオ録画自体が非常にスマートフォンのリソースを消費するのですが、このモデルは、そのリソースが消費された状態で、且つ他のYouTubeアプリが使用しているMLアルゴリズムとも共存出来るようにする必要がありました。
最後に、アルゴリズムは、バッテリー消費を最小限に抑えながら、デバイス上で迅速かつ効率的に実行する必要がありました。
「Looking to Listen」の一連の動作の中で、最初に行われる事は、話者の顔を含むサムネイル画像を動画から分離することです。
MediaPipe BlazeFaceのGPUアクセラレーションを使った推論を活用する事で、このステップをわずか数ミリ秒で実行できるようになりました。
次に、モデルの一部を「音声を強調する目的で視覚的特徴表現を出力するように学習した軽量のMobileNet(v2)」に切り替えました。ここでは、10ミリ秒毎にで抽出した顔のサムネイルを個別処理します。
視覚的特徴表現をフレームから抜き出してembedding化するために必要な処理時間は短いので、ビデオの録画中にこれを行うことができます。これにより、フレームをメモリに保持する必要がなくなり、全体的なメモリの合計使用量が削減できます。
その後、ビデオの録画が終了した後、音声と視覚的特徴表現がオーディオヴィジュアル分離モデルの入力となり、個々の音声が分離され、音声の大きさが増強されます。
「通常の」二次元畳み込みを、分離可能な畳み込み(周波数軸で一次元、続いて時間軸で一次元)に置き換えて、フィルターの数を減らす事により、オーディオビジュアルモデルのパラメータの総数を減らしました。
次に、TensorFlow Liteを使用してモデルを更に最適化しました。これは、モバイルデバイスでTensorFlowモデルを実行できるようにする一連のツールで、モデルサイズを小さくし、反応速度を素早くする事ができます。
最後に、Learn2Compressを使ってモデルを再実装し、組み込みの量子化トレーニングとQRNNサポートを利用しました。
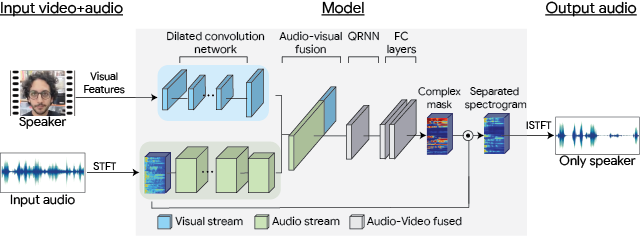
Looking to Listenを使ってオンデバイスで特定話者の声を強調するための処理の流れ
3.YouTubeストーリーで人の声だけ音量を上げる(1/2)関連リンク
1)ai.googleblog.com
Audiovisual Speech Enhancement in YouTube Stories
2)arxiv.org
Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
3)looking-to-listen.github.io
Looking to Listen at the Cocktail Party:A Speaker-Independent Audio-Visual Model for Speech Separation
4)support.google.com
YouTube Stories for creators
