
1.Smart Scroll:録音データから探している音声を捜しやすくする(1/2)まとめ
・昨年、音声録音をより便利にする新しい録音アプリであるRecorderをリリース
・Recorderは最大18時間を転記できるため特定のセクションを見つけるのが難しくなる
・スマートスクロールは重要なセクションに自動的に印を付けて見出しを作る機能
2.Smart Scrollとは?
以下、ai.googleblog.comより「Navigating Recorder Transcripts Easily, with Smart Scrolling」の意訳です。元記事の投稿は2020年11月24日、Itay Inbarさんによる投稿です。
scrollは名詞では巻き物、古文書の意味ですが、動詞になると突然コンピュータ用語として画面移動の意味になるんですね、不思議です。アイキャッチ画像のクレジットPhoto by Taylor Wilcox on Unsplash
昨年、音声録音をよりスマートで便利にする新しい種類の録音アプリであるRecorderをリリースしました。Recorderはオンデバイスの機械学習(ML:Machine Learning)を活用して録音データを文字として書き起こし、記録されている音声に関するイベントを強調表示し、タイトルとして適切な案を提案する事ができます。
Recorderを使用すると、音声データの転記、編集、共有、検索が簡単になります。しかし、Recorderは非常に長い録音(最大18時間!)を転記できるため、ユーザーが特定のセクションを見つけるのが難しい場合があり、そのような長い転記をすばやく案内するための新しいソリューションが必要になります。
操作性を高めるために、Recorderの新しいMLベースの機能であるスマートスクロールを導入します。これは、転記データの重要なセクションを自動的に印を付け、各セクションから最も代表的なキーワードを選択して、章の見出しのように、それらのキーワードを垂直スクロールバーに表示します。
次に、ユーザーはキーワードをスクロールするか、キーワードをタップして、関心のあるセクションにすばやく移動できます。使用されるモデルは、スマートフォン上で実行できるほど軽量であるため、転記データをクラウドにアップロードする必要はなく、ユーザーのプライバシーが保護されます。
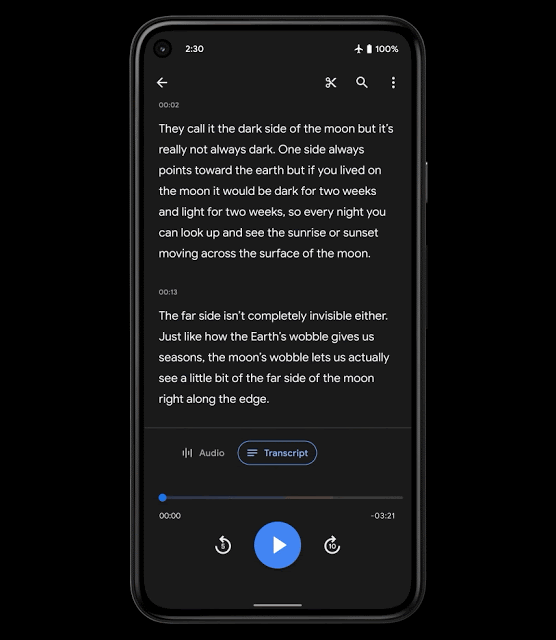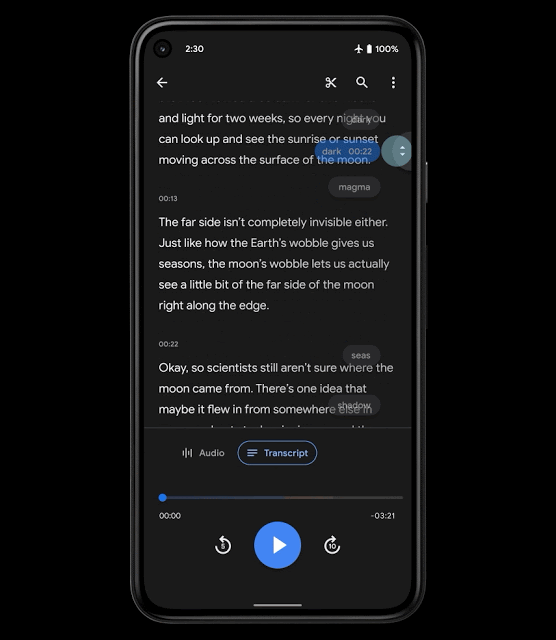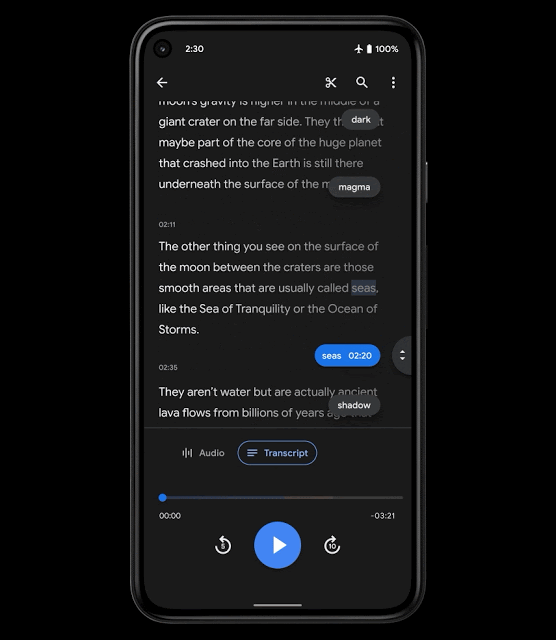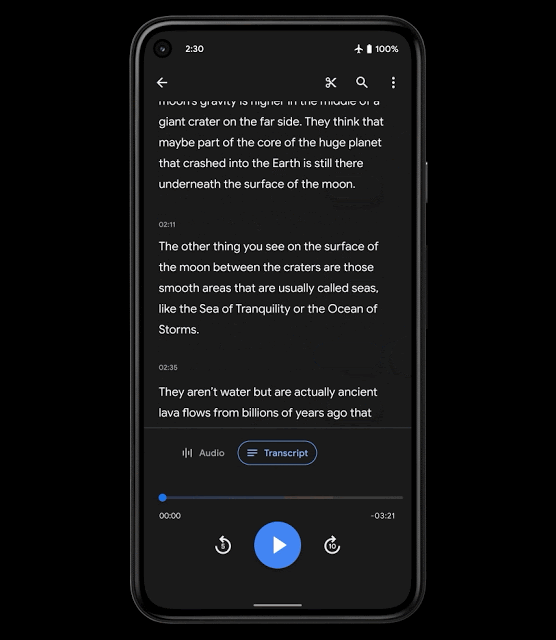
スマートスクロール機能のユーザ体験
動作原理
スマートスクロール機能は、2つの異なるタスクで構成されています。最初は各セクションから代表的なキーワードを抽出する事、2番目はテキスト内のどのセクションが最も有益でユニークであるかを選択する事です。
タスクごとに、2つの異なる自然言語処理(NLP:Natural Language Processing)アプローチを利用します。ウィキペディアのデータセットから供給されたデータで事前トレーニングされた蒸留済みBERT(distilled bidirectional transformer)モデルと、修正された抽出TF-IDF(Term Frequency–Inverse Document Frequency)モデルです。
キーワード抽出と重要なセクション識別タスクの両方に、集約した経験則(aggregation heuristics)とともに、BERTとTF-IDFベースのモデルを並行して使用し、それぞれのアプローチの利点を活用し、それぞれの欠点を軽減することができました。(これについては次のセクションで詳しく説明します)
双方向トランスフォーマーは、self-attentionメカニズムを採用して、入力テキストの文脈を認識する処理を非順次的に実現するニューラルネットワークアーキテクチャです。これにより、入力テキストの並列処理が可能になり、転記データ内の特定の位置の前後の文脈の手がかりを識別できます。
双方向トランスフォーマーベースのモデルアーキテクチャ
抽出TF-IDFアプローチは、「トレーニングされたデータセット内の逆頻度」と「比較する文章内の頻度」に基づいて用語を評価し、テキスト内の一意で代表的な用語を特定する事を可能にします。
両方のモデルは、独立した評価者によってラベル付けおよび評価された、公開されている会話型データセットでトレーニングされました。
会話型データセットは、会議、講義、インタビューに焦点を当てた、予想される製品のユースケースと同じドメインからのものでした。従って、同じ単語頻度分布が保証されます。(ジップの法則)。
代表的なキーワードの抽出
TF-IDFベースのモデルは、各単語にスコアを付けることによって有益なキーワードを検出します。
これは、このキーワードがテキスト内でどの程度代表的であるかに対応します。
このモデルは、標準のTF-IDFモデルと同様に、会話型データセット全体と比較したテキスト内の特定の単語の出現回数の比率を利用することによってこれを行います。ただし、用語の特異性も考慮に入れています。すなわち、それがどれほど広範または具体的であるかです。
更に、モデルは、事前にトレーニングされた関数曲線を使用して、これらの特徴をスコアに集約します。並行して、キーワードを抽出するタスクで微調整された双方向トランスフォーマーモデルは、テキストの文脈を意識し理解し、正確な文脈認識キーワードを抽出できるようにします。
TF-IDFアプローチは、テキスト内の一般的でないキーワード(偏りが大きい)を見つけやすい伝統的なやり方です。その一方、双方向トランスフォーマーモデルの欠点は、取り得るキーワード(分散が大きい)も含めて抽出できる事です。ただし、これら2つのモデルを一緒に使用すると、互いに補完し合い、偏りと分散のバランスの取れたトレードオフが形成されます。
両方のモデルからキーワードスコアが取得されたら、NLPにおける経験則(加重平均など)を利用し、セクション間の重複を削除し、ストップワードと動詞を削除することで、それらを正規化して結合します。 このプロセスの出力は、各セクションの推奨キーワードの順序付きリストです。
3.Smart Scroll:録音データから探している音声を捜しやすくする(1/2)関連リンク
1)ai.googleblog.com
Navigating Recorder Transcripts Easily, with Smart Scrolling

