
1.深層強化学習の力でロボットが俊敏で知的な移動を実現(1/3)まとめ
・強化学習のサンプル効率の悪さは依然として多くのアルゴリズムにとって主要なボトルネック
・脚式ロボットのためのデータ効率の良い強化学習として効率的な学習方法を発表
・必要なデータは学習プロセス全体でも5分未満なので現実世界のロボットで直接学習可能
2.脚式ロボットのためのデータ効率の良い強化学習
以下、ai.googleblog.comより「Agile and Intelligent Locomotion via Deep Reinforcement Learning」の意訳です。元記事の投稿は2020年5月6日、Yuxiang YangさんとDeepali Jainさんによる投稿です。
元記事タイトルにあるLocomotionってあまり馴染のない単語だと思うのですが、歩行ロボット関係の文献を見てると良く見る単語で「運動」とか「移動」の意味なんですね。でも実はSteam Locomotionで蒸気機関なんです。そう、実はSLって、Steam Locomotionの頭文字なんですね、Locomotionって馴染のない単語どころかかなり昔から馴染のある単語だった!って事で、勇壮な蒸気機関車のアイキャッチ画像のクレジットはPhoto by Sherry Chen on Unsplash
深層強化学習(deep RL)の最近の進歩により、脚式ロボットは自動化された環境との対話を通じて多くの俊敏な動作を学習できるようになりました。
ただし、サンプル効率の悪さは依然として多くのアルゴリズムにとって主要なボトルネックであり、研究者はオフポリシーデータの活用、動物の動きの模倣、またはメタ学習を使って、現実世界で訓練する必要性を減らす必要があります。
更に、ほとんどの既存の研究は、単純な低レベルスキル、つまり、前進、後退、方向転換などに焦点を合わせています。現実世界で自律的に動作するためには、ロボットはこれらのスキルを組み合わせてより高度な動きができるようになる必要があります。
本日、これらの問題に対処し、脚式ロボットの知覚-駆動ループ(perception-actuation loop)をまとめあげるために役立つ2つのプロジェクトを紹介します。
論文、「Data Efficient Reinforcement Learning for Legged Robots(脚式ロボットのためのデータ効率の良い強化学習)」では、低レベルのモーションコントロールポリシーを効率的に学習する方法を紹介します。本論文では、ロボットに力学モデルを適応させ、リアルタイムにアクションを計画することにより、ロボットは5分未満のデータを使用して複数の歩行スキルを学習します。
次に「Hierarchical Reinforcement Learning for Quadruped Locomotion(四足歩行のための階層的強化学習)」では、単純な動作を超えた自動経路ナビゲーションを探求します。本論文ではエンドツーエンドのトレーニング用に設計されたポリシーアーキテクチャにより、ロボットは、高レベルのプランニングポリシーと低レベルのモーションコントローラーを組み合わせて、曲がりくねった経路を自律的にナビゲートすることを学習します。
脚式ロボットのためのデータ効率の良い強化学習
強化学習の主要な問題は、サンプル効率が悪い事です。
Soft Actor-Critic(SAC)のような最先端のサンプル効率の良い学習アルゴリズムを使用しても、現実の世界では収集が難しい合理的な歩行ポリシーを学習するためには、1時間以上のデータが必要です。
私達は、現実の環境で学習する必要性を最小限に抑えて歩行スキルを学習させる取り組みを継続的に行ってきました。その成果として、もう一つモデルベースの手法を紹介します。この手法では、基本的な歩行スキルを学習可能でサンプル効率が高く、必要なトレーニングデータを大幅に削減する事ができます。
「環境の状態」から「ロボットの動作」を割り当てるポリシーを直接学習するのではなく、「現在の状態」と「ロボットの動作」から「将来の状態」を推定する動作モデルを学習します。
必要なデータは学習プロセス全体でも5分未満なので、現実世界のロボットを使って直接学習する事ができます。
まず、ロボットでランダムな動作を実行し、収集したデータにモデルを適合させます。モデルが適合した状態で、モデル予測コントロール(MPC:Model Predictive Control)プランナーを使用してロボットを制御します。
そして「MPCでより多くのデータを収集すること」と、「環境の変遷により適合するようにモデルを再トレーニングすること」を繰り返します。
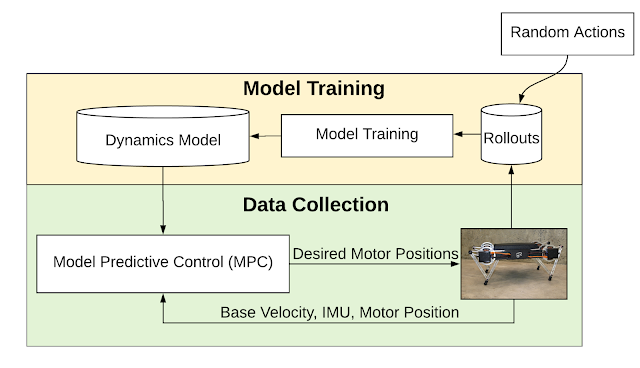
モデルベースの学習パイプラインの概要
システムは、変遷する環境へモデルを適合する事とモデル予測制御(MPC)を使用したデータ収集を交互に行います。
標準的なMPCでは、コントローラーは各タイムステップで一連のアクションを計画し、計画されたアクションの最初のアクションのみを実行します。
コントローラーにはロボットから定期的なフィードバックが行われるため、オンラインでリプランニングする事が可能になり、コントローラーはモデルの不正確さに対して堅牢になります。
しかし、オンラインで学習を行う事はアクションプランナーにとって課題も発生します。プランニングは制御ループの次のステップの前に完了する必要があるのです。これは、脚式ロボットの場合は通常10ミリ秒未満になります。
この厳しい時間制約を満たすために、非同期且つマルチスレッドでタスクを実行するマルチスレッド版MPCを開発し、アクションのプランニングと実行を別々のスレッドで実行するようにしました。実行スレッドは頻繁にアクションを実行するため、プランニングスレッドは邪魔にならないようにバックグラウンドで実行されるように最適化されます。
更に、アクションプランニングは複数のタイムステップをとる事ができるので、ロボットの状態はプランニングが終了する頃には変化している可能性があります。
このプランニングの遅延に関する問題に対処するために、これを補う新しい技術を考案します。これは、プランナーが計算を完了しそうになると、最初に将来の状態を予測します。次に、この将来の状態を元ネタとしてプランニングアルゴリズムに与えます。
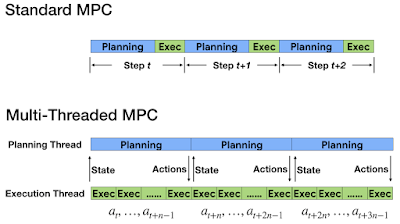
アクションのプランニングと実行を異なるスレッドで分離して実行します
3.深層強化学習の力でロボットが俊敏で知的な移動を実現(1/3)関連リンク
1)ai.googleblog.com
Agile and Intelligent Locomotion via Deep Reinforcement Learning
2)arxiv.org
Data Efficient Reinforcement Learning for Legged Robots
Hierarchical Reinforcement Learning for Quadruped Locomotion


コメント