
1.Hum to Search:鼻歌検索の背後に存在する技術(1/2)まとめ
・鼻歌とスタジオで録音された歌曲は使用している楽器等がかなり異なるため鼻歌検索は困難
・従来手法は全ての歌曲について鼻歌版を作成し、鼻歌版に対して鼻歌で検索をしていた
・Hum to Searchは機械学習を使い実際の歌曲を直接検索対象にする事ができる
2.Hum to Searchとは?
以下、ai.googleblog.comより「The Machine Learning Behind Hum to Search」の意訳です。元記事の投稿は2020年11月12日、Christian Frankさんによる投稿です。
Hum、すなわちハミングとは米国では口を開けずに行う発声を指すらしいので、口に対する制限は特にない鼻歌とは厳密には違うようです。そのため、本件はハミング検索の方が望ましい表記なのかもしれませんが、いずれにしても、うろ覚えの曲をサビの部分だけ「ふふぅ~ん♪」と発声して音楽を検索するシステムについてのお話です。
ちなみに使い方はAndroidやGoogle Homeをお使いでしたらGoogle アシスタントに「オッケー、グーグル、この曲は何?」と話かけてからの鼻歌で検索できるらしいのですが、以前のSound Search(カフェなどで現在流れている音楽が何かを検索する技術)も同じ起動方法だったので、どちらが使われているのか明示的に確認する方法はわかりませんでした。
パソコンであればChromeで、検索語入力フォーム右側のマイクマークから行けるみたいです。iphone版もGoogle Search Widgetを入れれば使えるらしいのですが、10月15日時点では英語のみと明示してあったので、もしかしたらHum to Searchを使っているつもりでSound Searchのみが使われていて「全然鼻歌検索できないじゃーん」となる可能性もあるようです。
アイキャッチ画像のクレジットはPhoto by bruce mars on Unsplash
頭の中で特定の曲が気になって永遠に繰り返される状況は、しばしば「イヤーワーム(earworms)」と呼ばれ、よく知られており、時には刺激的な現象です。一度そのイヤーワーム状態になると、取り除くのは難しい場合があります。研究によると、元の曲を聴くか歌うかする事で、イヤーワームを追い払える事がわかっています。しかし、曲の名前を完全に思い出せず、メロディーをハミングすることしかできない場合はどうでしょう?
ハミングされたメロディーを元の多重音源でスタジオレコーディングされた楽曲に一致させる既存の方法は、いくつかの課題に直面しています。歌詞、バックボーカル、楽器を使用しているため、ミュージカルやスタジオで録音されたオーディオは、ハミングされた曲とはかなり異なる場合があります。
誰かが曲を解釈して口ずさむと、誤ってまたは意図的に、ピッチ、調、テンポ、またはリズムがわずかに、または大幅に変化することがよくあります。
そのため、ハミングを使って楽曲検索を行う既存のアプローチの多くは、曲を直接識別するのではなく、ハミングされた曲を「メロディーのみの曲」または「ハミングされたバージョンの曲」のデータベースと照合します。しかしながら、このタイプのアプローチは、多くの場合、手動更新を必要とする限られたデータベースに依存しています。
10月にリリースされたHum to Searchは、機械学習を使って全てが実行されるGoogle検索内の新しいシステムであり、ハミングのみを使用して楽曲を見つけることができます。既存の手法とは対照的に、このアプローチでは、中間特徴表現を生成せずに、曲のスペクトログラムからメロディーのembeddingを作成します。
これにより、モデルは、楽曲の各パートのハミング版またはMIDI版の作成や、メロディを抽出するための他の複雑な手動ロジックを必要とせずに、ハミングされたメロディを元の多重音源(polyphonic)録音に直接一致させることができます。
このアプローチにより、Hum to Searchのデータベースが大幅に簡素化され、発表されたばかりの曲であっても、世界中の楽曲を登録したデータベースを常に更新できます。
背景
多くの既存の音楽認識システムは、適切な一致部分を見つけるために、オーディオサンプルを処理する前にスペクトログラムに変換します。しかし、ハミングされたメロディーを認識する際の1つの課題は、以下に示されているように、ハミングされた曲には比較的少ない情報しか含まれていない事が多い事です。
「さらば恋人よ(訳注:イタリアの歌曲で原題はBella ciao)」のハミング版と対応するスタジオレコーディング版の同一箇所の違いは、以下のようにスペクトログラムを使用して視覚化できます。
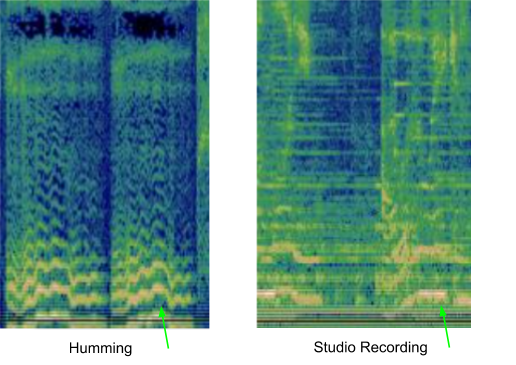
ハミング版(左)とそれに対応するスタジオレコーディング版(右)の視覚化
モデルは左側の画像を与えられて、5,000万を超える類似した画像の集まり(スタジオ録音した他の曲の個々のパートに対応)から、右側の画像に対応するオーディオを見つける必要があります。
これを実現するには、モデルは優勢なメロディーに焦点を合わせ、バックグラウンドのボーカル、楽器、声の音色、およびバックグラウンドノイズや部屋の残響に起因する違いを無視することを学ぶ必要があります。
これらの2つのスペクトログラムを一致させるために使用される可能性のある優勢なメロディーを目で見つけるために、人間ならば上の画像の下部近くの緑矢印部分に類似点を探すかもしれません。
以前の取り組みは、再生されている録音された音楽が何かを認識する取り組みでした。特にカフェやクラブなどの環境で再生されている音楽の特定を可能にするために機械学習がどのように使用できるかを示しました。
2017年にPixelスマートフォン用アプリとしてリリースされたNow Playingは、サーバー接続を必要とせずにオンデバイスでディープニューラルネットワークを使用して曲を認識します。Sound Searchはこの技術を更に開発して、サーバーベースの認識サービスを提供し、1億曲以上の楽曲からより高速で正確な検索を実現しました。
今回の課題は、これらのリリースから学んだことを活用して、同様に大規模な曲のライブラリからハミングまたは歌声によって音楽を認識することでした。
機械学習のセットアップ
Hum to Searchを開発する最初のステップは、Now PlayingおよびSound Searchで使用された音楽認識モデルを変更して、ハミングされた録音でも機能するようにすることでした。
原則として、多くの検索システム(画像認識など)は同様の方法で機能します。まず、ニューラルネットワークは、入力のペア(ここでは「録音されたオーディオ」と「ハミングまたは歌声」のペア)でトレーニングされ、各入力のembeddingsを生成します。これは、後でハミングされたメロディーとマッチングさせるために使用されます。
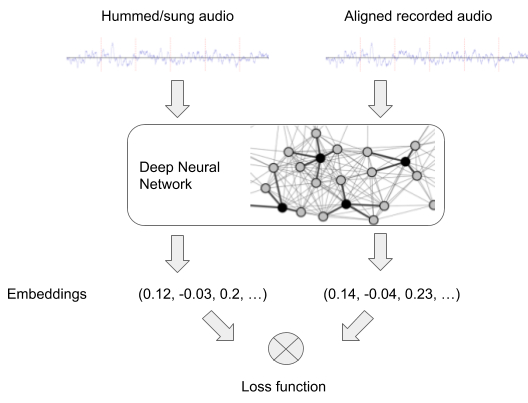
ニューラルネットワークのトレーニング
ハミング認識を可能にするために、ネットワークは、同じメロディーを含むオーディオのペアが、似たembeddingsを生成できるようになる必要があります。オーディオ内の楽器の伴奏や歌声が異なっていてもメロディーが同じであれば、embeddings同士が近くならねばなりません。
また、異なるメロディーを含むオーディオのペアは、異なったmbeddingsにする必要があります。ネットワークはこの条件を満たすembeddingsを生成出来るようになるまでオーディオのペアを使って訓練されます。
トレーニング済みモデルは、入力されたハミングのembeddingを作成できるようになり、これは検索対象曲のembeddingと似ています。embeddingさえ生成できれば、正しい曲を見つける事は、人気のある音楽から計算したembeddingを格納したデータベースから似たembeddingを検索するだけです。
3.Hum to Search:鼻歌検索の背後に存在する技術(1/2)関連リンク
1)ai.googleblog.com
The Machine Learning Behind Hum to Search

