
1.動物の動きからロボットを俊敏に動かすコツを学ぶまとめ
・歩いている動物の動画から制御ポリシーをトレーニングする強化学習フレームワークが発表
・サンプル効率の高い潜在空間適応手法を使用して現実世界への転移を効率的に行っている
・人間による世話を最小限にし、ロボットが自力で歩行を学習できるトレーニングシステムも開発
2.強化学習で動物の動きを学ぶ
以下、ai.googleblog.comより「Exploring Nature-Inspired Robot Agility」の意訳です。元記事の投稿は2020年4月3日、Xue Bin (Jason) PengさんとSehoon Haさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Daniel Tuttle on Unsplash
犬がボールを追いかける際も、馬が障害物を飛び越える際も、動物は驚くほど様々な素早い動きを簡単に実行する事ができます。
これらの俊敏な動きを再現できるロボットを開発できれば、現実世界で高度な作業を行えるようになり、ロボットはより広く使われるようになるでしょう。
しかし、脚を持つロボットがこれらの俊敏な行動を実行できるようにするためには、制御システムを設計する必要があり、これは、非常に困難な作業になる可能性があります。強化学習(RL:Reinforcement Learning)は、ロボットのスキル開発を自動化するためによく使用されるアプローチです。しかし、まだ多くの技術的なハードルが残っており、実際には、依然としてかなりの手作業が必要になります。
効果的なスキルの習得に繋がる報酬関数を設計する事は、それ自体、専門家の多大な洞察が必要になる場合があり、多くの場合、必要なスキル毎に長時間の報酬関数調整プロセスが必要になります。
更に脚付きロボットにRLを適用するためには、効率的なアルゴリズムだけでなく、ロボットが安全な状態を維持し、トレーニングエリアから離れて落下してしまった後でも人の手を借りる事なく起き上がる事を可能にするメカニズムも必要です。
本投稿では、これらの課題に対処することを目的とした最近の2つのプロジェクトについて説明します。
最初に、ロボットが実際の動物の動き、例えば、速歩や跳ねるといった流暢な素早い動きを模倣して、どのように俊敏な動きを学習できるかについて説明します。
次に、人間による世話を最小限にし、ロボットが自力で歩行を学習できるようにする「実世界での移動スキルの自動トレーニングシステム」について説明します。
動物を模倣して素早い歩行をロボットが学習
論文「Learning Agile Robotic Locomotion Skills by Imitating Animals」では、歩いている動物(この場合は犬)の動画を参照し、制御ポリシーをトレーニングする強化学習フレームワークを提示します。これにより、RLを使用してロボットが現実世界の動きを模倣できるようになります。
システムに異なった動きを提供することにより、四足歩行ロボットを訓練して、高速歩行からダイナミックに飛び跳ねて方向転換する事まで、様々な素早い動作を実行できます。
ポリシーは、主にシミュレーションで訓練され、潜在空間適応技術(latent space adaptation technique)を使用して実世界に転送されます。これにより、現実世界のロボットを使ったデータは数分のみでも、ポリシーを効率的に適応させることができます。
動きの模倣
最初に、様々な歩行をしている実際の犬の動きの動画を収集します。次に、RLを使用して、犬の動きを模倣する制御ポリシーをトレーニングします。ポリシーは物理シミュレーションでトレーニングされ、各タイムステップで参照する動きのポーズを追跡します。次に、報酬関数で様々な参照モーションを使用することで、様々な歩行を模倣するようにシミュレーションロボットをトレーニングできます。

強化学習は、シミュレーションでロボットを訓練して犬の動作を模倣するために使用されます。全てのシミュレーションはPyBulletを使用して実行されています。
ただし、シミュレータは一般に実世界の大まかな近似しか提供しないため、シミュレーションでトレーニングされたポリシーは、実際のロボットに転移するとパフォーマンスが低下することがよくあります。そのため、サンプル効率の高い潜在空間適応手法(latent space adaptation technique)を使用して、シミュレーションで訓練されたポリシーを現実世界に転移します。
まず、動きの変化に強いアクションを学習するポリシーを強化するため、ロボットの質量や摩擦などの物理量を変化させて、シミュレーション環境内での動きの変化をランダム化します。
シミュレーションを使った学習中にこれらのパラメーターの値に直接アクセスできるため、学習済みエンコーダーを使用して、それらを低次元特徴表現にマップすることもできます。このエンコーディングは、トレーニング中にポリシーへの追加入力として渡されます。
現実世界のロボットの物理パラメータは事前にはわからないので、ポリシーを実物のロボットに展開するときは、エンコーダーを削除して、潜在空間で一連のパラメーターを直接検索します。これにより、ロボットが現実の世界で必要なスキルを正常に実行できるようになります。
この手法では、8分未満の実際のデータを使用するだけで、ポリシーを現実世界に適合させることができます。

適応(adaptation)実行前後の実際のロボットでのポリシーの性能比較
適応前ではロボットは失敗する傾向があります。しかし、適応後はポリシーはより一貫して望ましい形でスキルを実行することができます。
結果
このアプローチを使用して、ロボットは犬の様々な歩行スキルを模倣することを学びます。これには、歩調の変更や速歩などの様々な歩きぶりや、俊敏な回転運動が含まれます。

犬の様々な歩行スキルを模倣するロボット
実際の犬の動きを模倣するだけでなく、動的な空中ターンなど、アーティストがアニメーション化した動きを模倣することもできます。


アーティストがアニメーション化した動きを模倣することで学んだスキル。サイドステップ、ターン、ホップターン
詳細については、次のビデオをご覧ください。
人間の世話を最小限にして実世界で歩くことを学ぶ
上記のアプローチで、シミュレーションでポリシーをトレーニングし、それらを現実の世界に適応させることができます。ただし、複雑で多様な物理現象を伴う場合は、現実世界の実体験から直接学ぶことも必要です。
実際のロボットで学習することにより、QT-Optなどのロボットアーム操作タスクでは最先端のパフォーマンスを実現する事ができましたが、脚のあるロボットの歩行タスクで同じ方法を適用することは困難です。
例えば、転んでしまったり、トレーニングエリアから離れてしまった場合はトレーニングエリアに戻すために人の介入が必要になる場合があります。

歩行ロボットの自動学習システムは、安全性と自動化の課題を解決する必要があります。
論文「Learning to Walk in the Real World with Minimal Human Effort」では、ソフトウェアとハードウェアのコンポーネントを備えた自動学習システムを開発しました。
このシステムはマルチタスク学習、安全制約のある学習(safety-constrained learner)、注意深く設計されたいくつかのハードウェアおよびソフトウェアコンポーネントを使用します。
マルチタスク学習は、ロボットをトレーニングエリアの中心に向かって移動させる学習スケジュールを生成することにより、ロボットがトレーニングエリアを離れることを防ぎます。また、二重勾配降下法を使って安全制約を設計することにより、落下回数を減らします。
各試行において、スケジューラは、歩行方向がトレーニングエリアの中心に向いているタスクを選択します。例えば、前方歩行と後方歩行の2つのタスクがあるとすると、ロボットがワークスペースの後ろにいる場合はスケジューラは前方タスクを選択し、後方タスクの場合はその逆になります。
エピソードの途中で、学習者は2つの勾配降下ステップを実行して、タスクの目標と安全制約の両方を1つの目標として扱うのではなく、繰り返し最適化します。
ロボットが落ちた場合は、自動起床制御を呼び出して、次のエピソードに進みます。
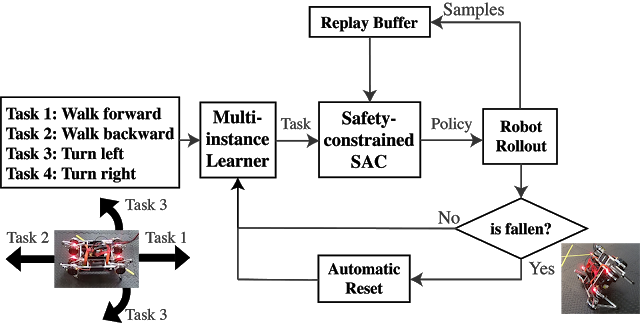
マルチタスク学習、安全制約付きSACアルゴリズム、自動リセットコントローラーにより、自動化と安全の課題を解決します。
結果
このフレームワークは、ポリシーを最初からトレーニングし、人間の介入なしに様々な方向に歩きます。

人間による補助なしで平地でトレーニングをしている場面
トレーニングが完了すると、リモートコントローラーでロボットを操縦することができます。コントローラーを使用してロボットに所定の位置で回転するようにどのように命令しているかに注目してください。このアクションは、ロボットの平面脚構造のために手動で設計するのは困難ですが、自動化されたマルチインスタンス学習を使用して自動的に見出されました。

4方向に歩くように移動ポリシーをトレーニングします。これにより、ゲームコントローラを使用してロボットをインタラクティブに制御できます。
また、このシステムにより、形状記憶マットレスや隙間のある玄関マットなど、より困難な表面をロボットを操舵できるようになります。

困難な地形での歩行の学習
詳細については、次のビデオをご覧ください。
結論
これらの2つの論文では、四足歩行ロボットによって多様な歩行行動を再現する方法を紹介しました。
ビデオからスキルを習得するようにこの一連の研究を拡張することもエキサイティングな方向性となり、ロボットが学習に利用できるデータ量を大幅に増やすことができます。また、自動化されたトレーニングシステムをより複雑な現実の環境やタスクに適用することにも関心があります。
謝辞
共著者であるErwin Coumans, Tingnan Zhang, Tsang-Wei Lee, Jie Tan, Sergey Levine, Peng Xu そして Zhenyu Tanに感謝します。また、Julian Ibarz, Byron David, Thinh Nguyen, Gus Kouretas, Krista Reymann およびBonny Hoに、この研究へのサポートと貢献に感謝します。
3.動物の動きからロボットを俊敏に動かすコツを学ぶ関連リンク
1)ai.googleblog.com
Exploring Nature-Inspired Robot Agility
2)arxiv.org
Learning to Walk in the Real World with Minimal Human Effort
3)xbpeng.github.io
Learning Agile Robotic Locomotion Skills by Imitating Animals
4)pybullet.org
Bullet Real-Time Physics Simulation


コメント