
1.Google Research:2022年以降にAIはどのように進化していくか?(1/6)まとめ
・ここ数年でモデルのパラメータ数は数十億規模から数千億または数兆にスケールアップした
・様々なタスクに対して最適化された部分のみを活性化する効率的なモデルが開発された
・様々な入力情報をもとに何百万ものタスクを解決できる高性能汎用モデルの開発を目指す
2.より高機能で汎用的なMLモデル
以下、ai.googleblog.comより「Google Research: Themes from 2021 and Beyond」の意訳です。元記事は2022年1月11日、Jeff Deanさんによる投稿です。
Looking back and beyond !って事でこれを読まなければ、お正月を無事に終えた気分にならない恒例のGoogle Researchを率いるJeff Deanによる去年の振り返りと今年の展望シリーズです。
タイトルが微妙に変わっており、実は2021年の展望記事より少しだけ文字数が減ってます。しかし、2021年の実績を網羅するのではなく、2022年以降の方向性を業界を俯瞰して見る書き方になっており、機械学習/人工知能がどのようになっていくのかを予測する際の助けになると思います。
アイキャッチ画像のクレジットはPhoto by Michael Held on Unsplash
この数十年、私は機械学習(ML:Machine Learning)とコンピュータサイエンスの分野で、多くの変化を目の当たりにしてきました。初期のアプローチはしばしば失敗に終わりましたが、やがて現在のアプローチが生まれ、大きな成功を収めています。このような長い弧を描くような進歩のパターンに従って、私たちは今後数年間で、最終的にこれまで以上に大きなインパクトをもって何十億もの人々の生活に貢献する、数多くのエキサイティングな進歩を目の当たりにすることになると思います。
この記事では、MLがそのようなインパクトを与える可能性がある5つの分野を紹介します。それぞれについて、関連する研究(主に2021年の研究)と、今後数年間に見られるであろう方向性と進歩について述べます。
トレンド1:より高機能で汎用的なMLモデル
トレンド2:MLの継続的な効率化
トレンド3:MLは個人にとって、社会的にとって有益になりつつある
トレンド4:科学、健康、サステナビリティにおけるMLの利点の拡大
トレンド5:MLに対する理解が深まり、広がっている
トレンド1:より高機能で汎用的なMLモデルの出現
研究者達は、これまで以上に大きく、より有能な機械学習モデルをトレーニングしています。たとえば、ここ数年で、言語領域のモデルは、数百億のデータトークンでトレーニングされた数十億のパラメータ(たとえば、110億パラメータのT5モデル)から、数千億または数兆のデータトークン(たとえば、OpenAIの1750億パラメーターGPT-3モデルやDeepMindの2800億パラメーターGopherモデルなどの密モデル、およびGoogleの6000億パラメーターGShardモデルや1.2兆パラメーターGLaMなどの疎モデル)でトレーニングされたものに成長しました。
これらのデータセットとモデルサイズの増大は、標準的な自然言語処理(NLP:Natural Language Processing)ベンチマークタスクの全面的な改善によって示されるように、多種多様な言語タスクの精度を大幅に向上させました。(言語モデルおよび機械翻訳モデルの「パラメータ数と性能向上の関係」に関する研究によって予測されたとおりです)
これらの高度なモデルの多くは、書き言葉という単一かつ重要なコミュニケーション手段に着目しており、言語理解ベンチマークやYes-Noで答えられないようなオープンエンドな会話能力において、複数の専門分野で複数のタスクにおいても最先端の結果を示しています。
また、比較的少ない学習データ、場合によっては新しいタスクの学習データがほとんどなくても、新しい言語タスクに汎化できるエキサイティングな能力も示しています。
例えば、長文質問回答の改善、自然言語処理におけるゼロラベル学習、そして私たちのLaMDAモデルは、複数回の対話に渡って重要な文脈を維持し、オープンエンドな会話を行う洗練された能力を示しています。

Transformerモデルは、画像、映像、音声モデルにも大きな影響を与えており、視覚分野のTransformerモデルの規模拡大則に関する研究によって予測されたように、これらもモデルとデータセットの規模を拡大する事による大きな恩恵を受けています。
画像認識や映像分類のためのTransformerは、多くのベンチマークで最先端の結果を得ています。また、画像データと動画データの両方を使ってモデルを協調して学習させると、画像データのみで学習させた場合と比較して動画タスクの性能が向上することが実証されています。
また、画像や動画用transformersのための疎な、軸方向注意機構(axial attention mechanisms)を開発し、これにより、計算がより効率的になりました。
視覚用transformersのために画像トークン化のより良い方法を発見しました。また、畳み込みニューラルネットワークと比較してtransformersがどのように動作するかを調べることで、視覚用transformersに対する理解を深めています。
transformersモデルと畳み込み演算を組み合わせることで、視覚認識だけでなく音声認識タスクにおいても大きな効果が得られることが分かっています。
また、生成モデルの出力も大幅に向上しています。これは画像を生成するモデルにおいて最も顕著であり、ここ数年で大きな進歩を遂げています。
例えば、「アイリッシュセッター」や「路面電車」など、カテゴリーを大枠で指定するだけでリアルな画像を生成したり、低解像度の画像を引き延ばして自然な高解像度の画像を生成したり(コンピューター処理による画質向上)、任意の長さの自然な自然風景を生成することが可能であることが、最近のモデルで実証されています。
また、画像を離散的なトークンの列に変換し、自己回帰生成モデルを用いて忠実に合成することも可能です。

与えられたカテゴリから新規画像を生成し、それを種として高解像度画像を生成するカスケード拡散モデルの例:最初のモデルは低解像度画像を生成し、残りのモデルは段階的に高解像度画像にアップサンプリングを実行します。
超解像拡散モデルSR3は、低解像度画像を入力とし、純粋なノイズから対応する高解像度画像を構築します。
このような強力な能力は大きな責任を伴うため、私たちは、この種のモデルの潜在的な用途を、GoogleのAI原則に照らして慎重に吟味しています。
高度なシングルモダリティモデル(一種類の入力しか扱えないモデル)に加え、大規模なマルチモダリティモデル(複数種類の入力が扱えるモデル)も登場し始めています。
これらのモデルは、複数の異なる入力様式(言語、画像、音声、動画など)を受け入れ、場合によっては異なる出力様式を生成することができるため、現在最も先進的なモデルの一つです。
例えば、説明的な文章や段落から画像を生成したり、画像の視覚的内容を人間が理解可能な自然言語で記述したりすることができます。
これらの研究結果は大変刺激的です。現実世界と同様に、マルチモーダルなデータの方が学習しやすいものがあるからです。(例えば、何かについて書かれた文章を読むだけより、読んで実際のデモを見る方が学びやすいです)
そのため、このように、画像とテキストのペアを作成することは、多言語検索タスクに役立ち、また、テキストと画像の入力のペアリング方法をより良く理解することは、画像に説明文をつけるタスクの結果を改善します。
同様に、視覚データとテキストデータを使って行う共同学習は、視覚分類タスクの精度と堅牢性の向上に役立ち、画像、動画、音声タスクの共同学習は、すべてのモダリティの汎化性能を向上させます。
また、自然言語が画像操作の入力として利用できることも示唆されています。これはロボットに世界との関わり方を伝えたり、他のソフトウェアシステムを制御したり、ユーザーインターフェースの開発方法に変化をもたらす可能性を秘めています。
これらのモデルが扱うモダリティは、発話、音、画像、動画、言語、さらには構造化データ、ナレッジグラフ、時系列データにも及ぶ可能性があります。

新規タスクへの汎化が可能な視覚ベースのロボット操作システムの例
左図:ロボットが自然言語で記述された「陶器のボウルにブドウを入れる」タスクを、モデルがその特定のタスクについて訓練された事がなくても実行できている
右図:左と同じですが、「ボトルをトレイに置く」という新しいタスクが記述されてそれを実行しています。
これらのモデルは、多くの場合、自己教師あり学習アプローチを使用して学習します。つまり、モデルはラベル付けされていない、まとまりのない「生の」データを観測して学習します。
例えば、GPT-3やGLaMで用いられる言語モデル、自己教師付き音声モデルBigSSL、視覚対照学習モデルSimCLR、マルチモーダルな対照モデルであるVATTなどです。
自己教師付き学習により、大規模音声認識モデルは、ラベル付き学習データのわずか3%を使用するだけで、以前の音声検索自動音声認識(ASR:Automatic Speech Recognition)ベンチマーク精度に匹敵する精度を実現しました。
これらの傾向は、特定のタスクのためにMLを有効にするのに必要な労力を大幅に削減できること、そして、異なる亜集団、地域、言語、あるいは他の重要な特徴表現次元をよりよく反映した、より代表的なデータでモデルを訓練することが容易になる事(決して簡単な事ではありません)ことから、刺激的なものです。
これらの傾向はすべて、複数のモダリティのデータを扱い、何千、何百万ものタスクを解決できる、非常に高性能な汎用モデルを訓練する方向性を示しています。
あるタスクに対して最適化されたモデル部分のみが活性化されるようにスパース性を組み込むことで、これらのマルチモーダルモデルを非常に効率的にすることができます。
今後数年間、私たちは「パスウェイ(Pathways)」と呼ばれる次世代アーキテクチャと包括的な取り組みにおいて、この方向性を追求していきます。これまで比較的独立して追求されてきた多くのアイデアを組み合わせることで、この分野で大きな進歩が期待されます。
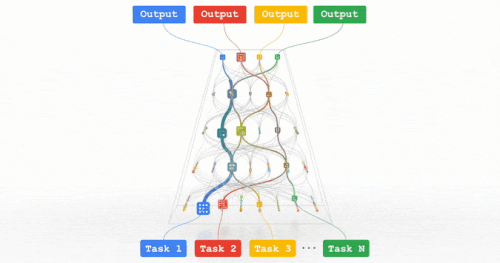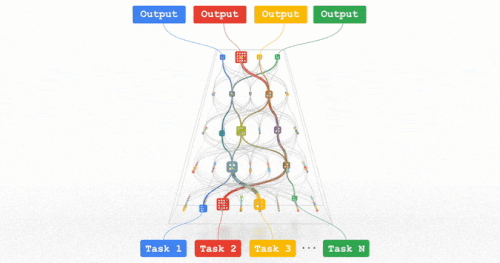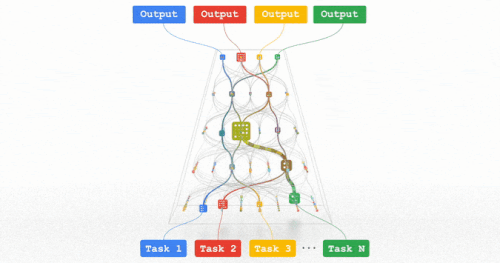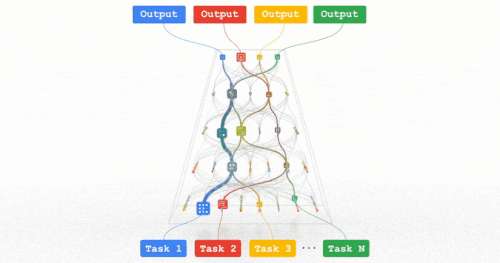
パスウェイ:何百万ものタスクに対応できる、私たちが目指している一つに統合されたモデルのイメージ
3.Google Research:2022年以降にAIはどのように進化していくか?(1/6)関連リンク
1)ai.googleblog.com
Google Research: Themes from 2021 and Beyond

