
1.TokenLearner:柔軟にトークン化する事でVision Transformerの効率と精度を向上(1/2)まとめ
・Vision Transformerは画像をトークン単位で扱うので画像の大域的な特徴をつかむ事ができる
・課題はトークンの数が多くなると指数関数的に計算量が多くなり実行不可能になる事であった
・TokenLearnerはトークンを均一ではなく状況に応じて作成する事で全体的な性能を底上げ
2.TokenLearnerとは?
以下、ai.googleblog.comより「Improving Vision Transformer Efficiency and Accuracy by Learning to Tokenize」の意訳です。元記事は2021年12月7日、Michael RyooさんとAnurag Arnabさんによる投稿です。
パッチ(patch)を意図したアイキャッチ画像のクレジットはPhoto by Joao Tzanno on Unsplash
Transformerを使ったモデルは、物体検出や動画分類などのコンピュータビジョンの課題において、常に最先端の結果を残しています。画像を画素単位で処理する標準的な畳み込みアプローチとは対照的に、Vision Transformers(ViT)は画像をパッチトークン(patch tokens、複数の画素からなる画像の小さな断片の事。パッチと言う)の並びとして扱います。
つまり、ViTモデルは各レイヤーにおいて、multi-head self-attentionを用いて、各トークンのペア間の関係に基づいてパッチトークンを再結合し処理します。これにより、ViTモデルは画像全体の大域的な特徴表現を構築することができます。
入力レベルでは、トークンは画像を複数の断片に一様に分割することで形成されます。例えば、512 x 512画素の画像を16 x 16画素のパッチに分割します。中間レベルでは、前のレイヤーの出力が次のレイヤーのトークンになります。動画の場合、16x16x2のビデオの断片(2フレームにわたる16×16画像)のようなビデオ「チューブレット(tubelets)」がトークンになります。これらの視覚的なトークンの質と量によって、Vision Transformerの全体的な品質が決まります。
多くのVision Transformerアーキテクチャの主な課題は、妥当な結果を得るためにあまりにも多くのトークンを必要とすることです。例えば16×16パッチのトークン化でも、1枚の512×512画像は1024個のトークンとなります。複数のフレームを持つビデオでは、各レイヤーで何万ものトークンが処理されることになります。
トークン数に比例してTransformerの計算が2次関数的に増加することを考えると、これはしばしば大きな画像や長いビデオに対してTransformerを実行不可能にする可能性があります。これは、各レイヤーでそれほど多くのトークンを処理することが本当に必要なのか、という疑問につながります。
NeurIPS 2021では論文「TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?」の早期版を発表し、常に均一分割する事で形成されたトークンに頼るのではなく、より少数のトークンを適応的(adaptively)に生成することで、Vision Transformersがより速く、より良いパフォーマンスで動作するようになることを示しました。
TokenLearnerは、画像のようなテンソル(すなわち入力)を受け取り、トークンの小さな集合を生成する学習可能なモジュールです。
このモジュールは対象のモデル内の様々な異なる場所に配置することができ、後続の全ての層で扱うべきトークンの数を大幅に削減することができます。実験では、TokenLearnerを搭載することで、分類性能を損なわずにメモリと計算を半分以上節約でき、入力に柔軟に適応する能力があるため、精度さえ向上することが実証されました。
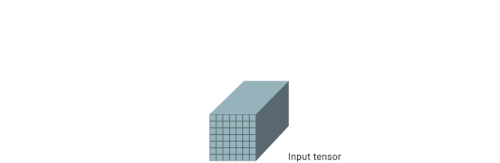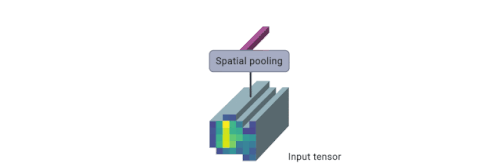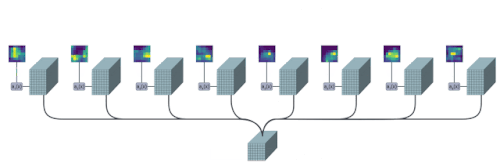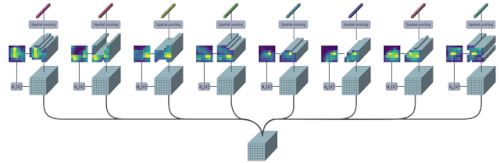
TokenLearnerモジュールは、各出力トークンに対して空間Attention mapを生成するように学習し、それを用いてトークン化のための入力を抽象化します。実務的には、複数の空間的Attention関数を学習し、入力に適用し、異なるトークンベクトルを並列に生成します。
その結果、TokenLearnerは、入力に対して固定した一律のトークン化処理をするのではなく、特定の認識タスクに関連する少数のトークンを処理することを可能にしました。
すなわち、
(1)適応的なトークン化を可能にする事で、入力に応じたトークンを動的に選択できるようにしました。
これにより、
(2)トークンの総数が効果的に削減され、ネットワークが行う計算が大幅に軽減されました。
これらの動的かつ適応的に生成されたトークンは、画像用のViTや動画用のViViTなどの標準的なtransformerアーキテクチャで利用することができます。
3.TokenLearner:柔軟にトークン化する事でVision Transformerの効率と精度を向上(1/2)まとめ
1)ai.googleblog.com
Improving Vision Transformer Efficiency and Accuracy by Learning to Tokenize
2)arxiv.org
TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?
3)github.com
scenic/scenic/projects/token_learner/

