
1.Crisscrossed Captions:画像とテキストの意味的類似性の探求(1/3)まとめ
・自動画像キャプションはアルゴリズムで画像の説明を作成するタスクで目覚ましい進歩を遂げた
・これにより視覚情報と言語情報を紐づける研究に利用可能なデータセットの構築が可能になる
・CxCはMS-COCOを拡張し画像と文書の意味的類似性を評価するために利用可能なデータセット
2.Crisscrossed Captionsとは?
以下、ai.googleblog.comより「Crisscrossed Captions: Semantic Similarity for Images and Text」の意訳です。元記事の投稿は2021年5月6日、Zarana ParekhさんとJason Baldridgeさんによる投稿です。
Crisscrossとは「交差」や「十字」の意味を持ち、そしてそこから連想なのか騙すや裏切ると言う意味も持つらしいのですが単純な十字の連想からのアイキャッチ画像のクレジットはPhoto by Robert Bye on Unsplash
過去10年間で、自動画像キャプション(automatic image captioning、コンピューターアルゴリズムが画像の説明を作成するタスク)が目覚ましい進歩を遂げました。進歩の多くは、コンピュータービジョンと自然言語処理の両方のために開発された最新の深層学習手法を、「画像」と「人が作成した説明(キャプション)」を組み合わせた大規模なデータセットと組み合わせて使用することで実現しました。
これらのデータセットは、視覚障害者向けに画像の説明文を提供するなど、重要で実用的なアプリケーションをサポートするだけでなく、視覚からの情報を自然言語に紐づける、重要で刺激的な研究に関する問いかけを調査可能にします。
例えば「車」のような単語のディープな特徴表現を学習することは、「言語的な意味合い」と「視覚的な意味合い」の両方で使用可能な特徴表現を意味します。
MS-COCOやFlickr30kなど、テキストの説明とそれに対応する画像のペアを含む画像キャプションデータセットは、並び合わせた画像とテキストの特徴表現を学習し、キャプションモデルを構築するために広く使用されています。
残念ながら、これらのデータセット内の領域間のクロスモーダルな関連付け、すなわち「画像領域」と「言語領域」をクロスするような関連付けは限られています。
画像は他の画像とペアになっておらず、キャプションは同じ画像の他のキャプション(co-captions、コキャプションとも呼ばれます)とのみペアになっています。
画像とキャプションのペアが一致していても「一致」としてラベル付けされていないペアがあり、画像とキャプションのペアが一致しないことを示すラベルはありません。
これは、モダリティ間学習(たとえば、キャプションを画像に関連づける)がモダリティ内タスク(キャプションをキャプションに関連づける、または画像を画像に関連づける)にどのように影響するかに関する研究を弱体化させます。
特に、テキストと組み合わせた画像から学習させる研究作業は、視覚要素が言語の特徴表現にどのように情報を提供し、改善するかについての議論によって動機付けられているため、これに対処することが重要です。
この評価のギャップに対処するために、最近EACL2021で発表した「Crisscrossed Captions: Extended Intramodal and Intermodal Semantic Similarity Judgments for MS-COCO」を提示します。
CrisscrossedCaptions(CxC)データセットは、MS-COCOの開発データセットとテストデータセットの分割を拡張し、画像-テキスト、テキスト-テキスト、および画像-画像のペアの意味的類似性を評価します。
評価基準は、テキストの持つ意味の類似性に基づいています。これは、短いテキストのペア間の意味的関連性の既存の広く採用されている尺度であり、画像に関する判断も含めるように拡張されています。全体として、CxCには、267,095ペア(1,335,475の独立した判断から導出)の人間由来の意味的類似性評価が含まれています。これは、MS-COCOの開発およびテスト分割における5万の元のバイナリペアに対するスケールと詳細の大幅な拡張です。
CxCの評価と、CxCを既存のMS-COCOデータに併合するコードをリリースしました。したがって、MS-COCOに精通している人なら誰でも、CxCを使った実験を簡単に強化できます。
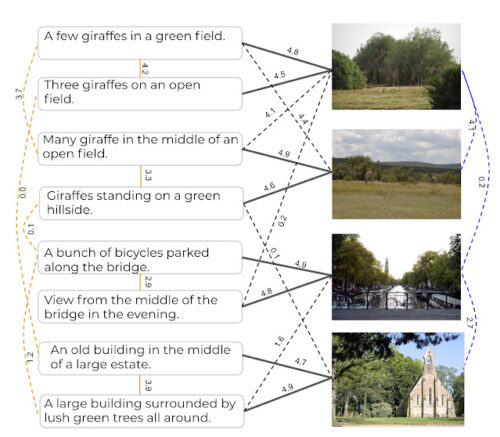
Crisscrossed Captionsは、既存の画像とキャプションのペアとコキャプション(実線)に人間が導出した意味的類似性評価を追加することにより、MS-COCO評価セットを拡張します。また、新しい「画像-キャプション」、「キャプション-キャプション」、および「画像-画像」のペア(破線)に人間による評価を追加することで、評価密度を高めます。
CxCデータセットの作成
写真が千の言葉に値するのであれば、それは一般的に写真内の個々の物体が非常に多くの詳細と関係を持つためである可能性があります。
犬の毛皮の質感を説明し、犬が追いかけているフリスビーのロゴの名前を読む事、フリスビーを投げたばかりの人の顔の表情に言及したり、人の頭の上にある木の大きな葉の鮮やかな赤に着目する事もできます。
CxCデータセットは、画像間またはキャプション間、および画像とキャプション間で段階的な類似性の関連付けを使用して、MS-COCO評価分割を拡張します。
MS-COCOには、画像ごとに5つのキャプションがあり、41万のトレーニング、2.5万の開発、および2.5万のテストキャプションに分割されています(それぞれ8.2万、5千、5千の画像用)
理想的な拡張機能は、データセット内のすべてのペア(キャプション-キャプション、画像-画像、および画像-キャプション)を評価しますが、数十億のペアに対して人間が評価する必要があるため、これは実行不可能です。
3.Crisscrossed Captions:画像とテキストの意味的類似性の探求(1/3)関連リンク
1)ai.googleblog.com
Crisscrossed Captions: Semantic Similarity for Images and Text
2)www.aclweb.org
Crisscrossed Captions: Extended Intramodal and Intermodal Semantic Similarity Judgments for MS-COCO
3)github.com
google-research-datasets / Crisscrossed-Captions

