
1.より少ないデータから表形式データを推論することを学習(1/2)まとめ
・自然言語推論は通常の文章を対象にした研究は多いが構造化データに適用する研究は少ない
・EMNLP 2020で表形式データ解析用にカスタマイズされた初の事前トレーニングタスク発表
・新しい事前トレーニングを使うとモデルと人間のパフォーマンスギャップを最大50%減少
2.表形式データの推論
以下、ai.googleblog.comより「Learning to Reason Over Tables from Less Data」の意訳です。元記事の投稿は2021年1月29日、Julian Eisenschlosさんによる投稿です。
ToTToに続きテーブル形式データに関するお話です。
アイキャッチ画像のクレジットはPhoto by Jose Losada on Unsplash
自然言語推論(natural language inference)としても知られる、文章に含まれる意味、すなわち含意を認識するタスクは、テキストの一部(premise、前提)が別のテキスト(hypothesis、仮説)から類推される、または否定される(またはどちらでもない)かどうかを判断することで構成されます。
この問題は、機械学習(ML:Machine Learning)システムの推論スキルの重要なテストと見なされることが多く、通常の文章については詳細に研究されています。しかし、これをWebサイト、テーブル、データベースなどの構造化データに適用する研究は非常に少ないです。
しかし、表形式データの内容を正確に要約してユーザーに提示する必要がある場合は常に、テキストの含意を認識することが特に重要であり、忠実度の高い質問回答システムや仮想アシスタントにとって不可欠です。
EMNLP 2020の調査結果に掲載された「Understanding tables with intermediate pre-training」では、表形式データ解析用にカスタマイズされた初の事前トレーニングタスクを紹介し、モデルがより適切に、より速く、より少ないデータから学習できるようにします。
これは、以前紹介したTAPASモデルに基づいて構築されており、テーブル内の回答を見つけるための特別なembeddingを備えたBERT(bi-directional Transformer)モデルの拡張です。
新しい事前トレーニングの目標をTAPASに適用すると、テーブルを含む複数のデータセットに新しい最先端の性能がもたらされます。たとえば、TabFactデータセットを使った結果では、モデルと人間のパフォーマンスのギャップが最大50%減少します。
また効率を高めるために、推論に必要な入力データを選別する体系的な手法を計測し、性能(92%)を維持しながら、速度とメモリ効率を4倍に向上させました。様々なタスクと全てのサイズのモデルがGitHubリポジトリで公開されており、colabノートブックで実際に試すこともできます。
テキスト含意問題
テキスト含意のタスクは、通常のテキストよりも表形式のデータに適用する場合に困難です。例えば、ウィキペディアのテーブルと、それに関連するテーブルコンテンツから派生したいくつかの文について考えてみます。表の内容が文意に沿っているか矛盾するかを評価するには、複数の列と行を調べ、場合によっては平均化、合計、差分などの単純な数値計算を実行する必要があります。
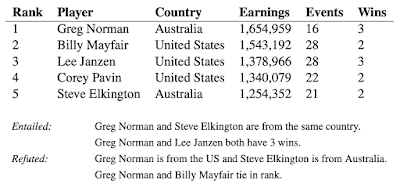
TabFactから抜粋したいくつかのテーブルと関連文。表の内容は、関連文を補足、否定するために使用されます。
TAPASで使用される手法に従って、関連文とテーブル内容を一緒にエンコードし、それらをTransformerモデルに渡して、関連文が表内容に伴うか、または否定されるかを確率として取得します。
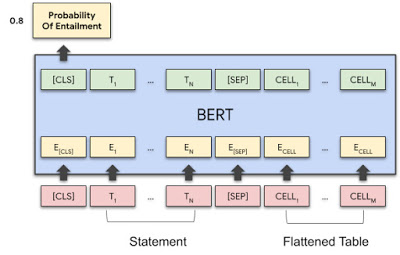
TAPASモデルアーキテクチャは、BERTモデルを使用して、関連文と平坦化された表内容をエンコードし、行ごとに読み取ります。テーブル構造をエンコードするために、特別なembeddingが使用されます。最初のトークンのベクトル出力は、含意の確率を予測するために使用されます。
学習用データ内の各事例が持つ情報は二項分類値(つまり、「正しい」または「正しくない」)のみであるため、関連文に含意が含まれるかどうかを理解するためにモデルをトレーニングすることは困難です。
特に、提供されるトレーニング信号が不足している際に深層学習を使って一般化を達成する事の難しさを浮き彫りにします。
個々の含意または否定された事例を見ると、モデルはデータ内の怪しげなパターンを安易に拾い上げて予測をしてしまいます。例えば、「Greg NormanとBilly Mayfairがランク内で同点(tie)」は「同点(tie)」という単語が存在する事を根拠にしてしまいます。
しかし、元の学習用データの範囲を超えてモデルを正常に一般化するには、ランクを本当に比較する必要があります。
事前トレーニングタスク
事前トレーニングタスクを使用して、すぐに利用できるラベルのないデータを大量にモデルに提供することで、モデルを「ウォームアップ」できます。
ただし、事前トレーニングには通常、表形式のデータではなく、主に通常の文章が含まれます。 実際、TAPASは元々、表形式のデータアプリケーション用に設計されていない単純なマスク言語モデリングを使用して事前にトレーニングされていました。
3.より少ないデータから表形式データを推論することを学習(1/2)関連リンク
1)ai.googleblog.com
Learning to Reason Over Tables from Less Data
2)www.aclweb.org
Understanding tables with intermediate pre-training
3)github.com
google-research/tapas

