
1.SimVLM:弱い教師を使ったシンプルな視覚言語モデル(1/2)まとめ
・視覚言語モデリングは、視覚的な入力に言語を対応させて理解する土台となる
・視覚入力と言語入力の両方から単一の特徴空間を学習する手法で近年大きく進歩した
・SimVLMはシンプルな視覚言語モデルで従来手法より規模の拡大が容易に実行可能
2.SimVLMとは?
以下、ai.googleblog.comより「SimVLM: Simple Visual Language Model Pre-training with Weak Supervision」の意訳です。元記事の投稿は2021年10月15日、Zirui WangさんとYuan Caoさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by kevin laminto on Unsplash
視覚言語モデリング(Vision-language modeling)は、視覚的な入力に言語を対応させて理解する土台となり、重要な製品やツールの開発に役立つ可能性があります。
たとえば、画像キャプションモデルは、画像に自然言語の説明文を生成します。このようなクロスモーダル作業にはさまざまな課題がありますが、効果的な視覚言語事前トレーニング(VLP:Vision-Language Pre-Training)の採用により、視覚言語モデリングに関して過去数年間で大きな進歩が見られました。
このアプローチは、視覚入力用と言語入力用の2つの別個の特徴空間を学習するのではなく、視覚入力と言語入力の両方から単一の特徴空間を学習することを目的としています。
この目的のために、既存のVLPは、多くの場合、Faster R-CNNなどの物体検出器を活用し、ラベル付きオブジェクト検出データセットでトレーニングして関心領域(ROI:Regions-Of-Interest)を分離する事が良くあります。
そして、画像とテキストの特徴表現を共同で学習するために、タスク固有のアプローチ(つまり、タスク固有の損失関数)に依存しています。このようなアプローチでは、注釈付きのデータセットまたはタスク固有のアプローチを設計する時間が必要になるため、規模拡張性が低下します。
この課題に対処するために、論文「SimVLM: Simple Visual Language Model Pre-training with Weak Supervision」では「Simple Visual Language Model(シンプルな視覚言語モデル)」の略であるSimVLMという名前の最小限で効果的なVLPを提案します。
SimVLMは、言語モデリングと同様に、大ざっぱに揃えた大量の画像とテキストのペア(weakly aligned。つまり、画像とペアになっているテキストは、必ずしも画像の正確な説明ではありません)を使って、直接トレーニングされます。
SimVLMのシンプルさは、このような大規模に拡張されたデータセットを使っての効率的なトレーニングが可能にし、モデルが6つの視覚言語ベンチマークにわたって最先端のパフォーマンスを達成するのに役立ちます。
さらに、SimVLMは、オープンエンド(訳注:Yes or Noで答えられないような問題)の視覚的な質問回答、画像のキャプション、マルチモーダル変換などのタスクを含め、微調整なしで、またはテキストデータのみを微調整して、強力なゼロショットクロスモダリティ転移を可能にする統合マルチモーダル特徴表現(unified multimodal representation)を学習します。
モデルと事前トレーニング手順
BERTなどのマスク言語モデリング(masked language modeling)と同じ事前トレーニング手法を採用する既存のVLPとは異なり、SimVLMはsequence-to-sequenceフレームワークを採用し、プレフィックス言語モデル(PrefixLM:prefix language model)でトレーニングされます。
これは文章の先頭部分(プレフィックス)を入力として受け取り、その後に続く文を予測します。例えば、「A dog is chasing after a yellow ball.(犬が黄色いボールを追いかけている)」という文が与えられた場合、プレフィックスは文をランダムに切り捨てた「A dog is chasing(犬が追いかけている)」になり、モデルはその後続にくるものを予測します。
プレフィックスの概念は画像データにも同様に適用されます。画像はいくつかの断片(パッチ)に分割され、それらの断片の一部分が入力としてモデルに順次供給されます。これは「画像パッチシーケンス(image patch sequence)」と呼ばれます。
SimVLMでは、マルチモーダル入力(画像とその説明文など)の場合、プレフィックスは、エンコーダーが受信する画像パッチシーケンスとテキストプレフィックスの両方を連結したものです。次に、デコーダーはテキストの次にくるものを予測します。
いくつかの事前トレーニング損失を組み合わせた以前のVLPモデルと比較して、PrefixLM損失は単一のトレーニング目標であり、トレーニングプロセスを大幅に簡素化します。SimVLMのこのアプローチは、さまざまなタスク設定に対応する際の柔軟性と普遍性を最大化します。
最後に、BERTやViTなどの言語タスクと視覚タスクの両方で成功したため、モデルのバックボーンとしてTransformerアーキテクチャを採用しました。これにより、以前のROIベースのVLPアプローチとは異なり、モデルは生の画像を直接入力として取り込むことができます。
更にさらに、CoAtNetに触発されて、文脈化されたパッチを抽出するために、ResNetの最初の3つのブロックで構成される畳み込みステージを採用します。これは、元のViTモデルのナイーブ線形射影(naïve linear projection)よりも有利です。全体的なモデルアーキテクチャを以下に示します。
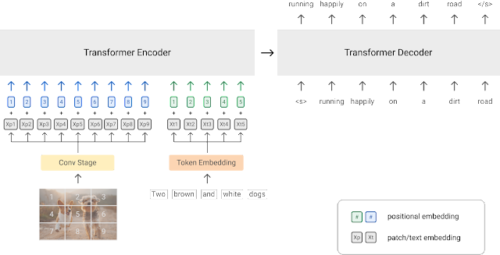
SimVLMモデルアーキテクチャの概要
モデルは、画像-テキスト入力とテキストのみの入力の両方について、大規模なWebデータセットで事前トレーニングされています。共同ビジョンと言語データには、約18億のノイズの多い画像とテキストのペアを含むALIGNトレーニングセットを使用します。テキストのみのデータの場合、T5によって導入されたColossal Clean Crawled Corpus(C4)データセットを使用し、合計800GのWebクロールされた文章を使用します。
ベンチマーク結果
事前トレーニングの後、VQA、NLVR2、SNLI-VE、COCO Caption、NoCaps、Multi30K En-Deの各データセットを使いマルチモーダルタスクでモデルを微調整します。
たとえば、VQAの場合、モデルは入力画像に関する画像と対応する質問を取得し、出力として回答を生成します。
3.SimVLM:弱い教師を使ったシンプルな視覚言語モデル(1/2)関連リンク
1)ai.googleblog.com
SimVLM: Simple Visual Language Model Pre-training with Weak Supervision
2)arxiv.org
SimVLM: Simple Visual Language Model Pretraining with Weak Supervision

