
1.KELM:ナレッジグラフを言語モデルの事前トレーニング資料に統合まとめ
・大規模な自然言語処理モデルは、インターネットから取得した自然言語の資料を活用する
・自然言語のテキストだけでは、知識の範囲が限られるため他の情報源もある事が望ましい
・KELMはナレッジグラフを合成自然言語文に変換して事前トレーニングへの統合を可能にする
2.KELMとは?
以下、ai.googleblog.comより「KELM: Integrating Knowledge Graphs with Language Model Pre-training Corpora」の意訳です。元記事の投稿は2021年5月20日、Siamak ShakeriさんとOshin Agarwalさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Amer Mughawish on Unsplash
BERT、RoBERTa、GPT-3、T5、REALMなどの事前にトレーニングされた大規模な自然言語処理(NLP:Natural Language Processing)モデルは、自然言語の資料を活用します。これらはインターネットから取得した、タスク固有のデータで微調整されており、様々なNLPタスクで大幅な進歩を遂げています。
ただし、自然言語のテキストだけでは、知識の範囲が限られています。そして事実は多くの異なった形で助長な文章中に含まれるかもしれません。更に、テキストに事実に反する情報や有害なコンテンツが存在すると、最終的には結果のモデルに偏見が生じる可能性があります。
代替となる情報源は、構造化データで構成されるナレッジグラフ(KG:Knowledge Graphs)です。ナレッジグラフの情報は通常、より信頼できるソースから抽出され、後処理フィルターと人間の編集者が不適切で不正確なコンテンツを確実に削除して知識をグラフ化するため、KGは事実に基づいています。
従って、それらを組み込むことができるモデルであれば、事実の精度が向上し、毒性が低下するという利点があります。ただし、構造形式が異なるため、言語モデルが通常使用する既存の事前トレーニング資料とナレッジグラフを統合することは困難です。
NAACL 2021で受理された「Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training」(KELM)では、KGを合成自然言語文に変換して、既存の事前トレーニング資料を拡張し、事前トレーニングへの統合を可能にします。これは、アーキテクチャを変更することなく、言語モデルの事前トレーニングへの統合を可能にします。
そのために、公開されている英語のWikidata KGを活用し、それを自然言語のテキストに変換して、合成資料を作成します。次に、検索ベースの言語モデルであるREALMを、事前トレーニングで自然言語資料とKGを統合する方法として合成資料で拡張しました。この合成資料KELMは、より幅広い研究コミュニティ向けにgithubで公開されています。
ナレッジグラフを自然言語テキストに変換する
KGは、構造化された形式で明示的に表された事実情報で構成されます。
一般的には
(例:[10×10 photobooks, inception, 2012])
関連するトリプルを集めたグループは、エンティティサブグラフと呼ばれます。
前のトリプルの例に基づいたエンティティサブグラフの例は、
{
[10×10 photobooks, instance of, Nonprofit Organization],
[10×10 photobooks, inception, 2012]
},
であり、以下の図のように示されます。KGは、相互接続されたエンティティサブグラフと見なすことができます。
サブグラフを自然言語テキストに変換することは、データからテキストへの生成として知られるNLPの標準的なタスクです。WebNLGなどのベンチマークデータセットを使ってデータからテキストを生成するタスクには大きな進歩がありましたが、KG全体を自然テキストに変換するためには追加の課題があります。
大きなKGのエンティティと関係は、小さなベンチマークデータセットよりも広大で多様です。更に、ベンチマークデータセットは、流暢で意味のある文を形成できるように事前定義されたサブグラフが含まれます。KG全体で、エンティティサブグラフに対してそのようなサブグラフも作成する必要があります。
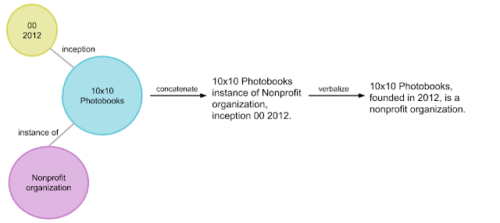
エンティティサブグラフ(球形状)を合成自然文(右端)に変換する手法の概要図
Wikidata KGを合成自然文に変換するために、「Text from KG Generator」(TEKGEN)という名前の言語化パイプラインを開発しました。これは、以下の部品から構成されています。
・経験側に基いて配置されたWikipediaテキストとWikidataKGトリプルの大規模なトレーニングコーパス
・KGトリプルをテキストに変換するテキスト間ジェネレーター(T5)
・一緒に言語化されるトリプルのグループを生成するためのエンティティサブグラフジェネレーター
・低品質の出力を削除するための後処理フィルター
その結果、WikidataKG全体を自然なテキストとして含む資料が作成されます。これをKnowledge-Enhanced Language Model(KELM)コーパスと呼びます。これは、最大4500万のトリプルと最大1500の関係にまたがる最大1800万の文で構成されています。

ナレッジグラフを自然言語に変換し、言語モデルの拡張に使用
言語モデルの事前トレーニング用にナレッジグラフと自然言語を統合
私達の評価は、KGの言語化がKGを自然言語のテキストと統合する効果的な方法であることを示しています。ウィキペディアのテキストのみを含むREALMの検索コーパスを拡張することにより、これを示します。
言語化の有効性を評価するために、REALM検索コーパスをKELMコーパス(つまり、「言語化されたトリプル」)で拡張し、言語化なしの連結トリプルによる拡張とそのパフォーマンスを比較します。
2つの一般的なオープンドメインの質問応答データセットであるNatural QuestionsとWeb Questionsで、各データ拡張手法を使用して精度を測定します。
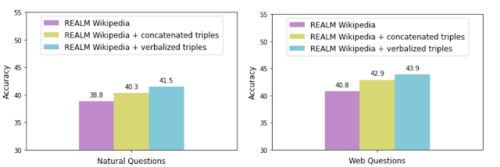
連結されたトリプルを用いてREALMを拡張すると、精度が向上し、テキストで明示的にまたはまったく表現されていない情報が追加される可能性があります。しかしながら、精度が高まる事からわかるように、言語化されたトリプルを使用する事でKGと自然言語のテキスト資料をよりスムーズに統合できます。
また、空欄に入る言葉を記入させてモデルをチェックするLAMAと呼ばれる調査方法でも同じ傾向が見られました。
結論
KELMを使用して、公開されているナレッジグラフを自然なテキストとして提供しました。ナレッジグラフの言語化を使用して、ナレッジグラフを自然なテキスト資料と統合し、構造の違いを克服できることを示しました。これには、質問回答など、事実に基づく知識の提供が不可欠な知識集約型タスクの実際のアプリケーションがあります。更に、そのような言語資料は、大規模な言語モデルの事前トレーニングに適用でき、毒性を減らし、事実を改善する可能性があります。本研究が、構造化された知識ソースを大規模な言語モデルの事前トレーニングに統合する上でのさらなる進歩を促進することを願っています。
謝辞
本研究は、Oshin Agarwal, Heming Ge, Siamak Shakeri そして Rami Al-Rfouが参加した共同作業です。合成資料のサンプルを評価して品質を評価してくれたWilliam Woods, Jonni Kanerva, Tania Rojas-Esponda, Jianmo Ni, Aaron Cohen 及び Itai Rolnickに感謝します。また、この論文に関する貴重なフィードバックを寄せてくれたKelvin Guuにも感謝します。
3.KELM:ナレッジグラフを言語モデルの事前トレーニング資料に統合関連リンク
1)ai.googleblog.com
KELM: Integrating Knowledge Graphs with Language Model Pre-training Corpora
2)arxiv.org
Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training
3)github.com
google-research-datasets / KELM-corpus

