
1.拡散モデルを使用してGANより忠実度の高い画像を生成(1/2)まとめ
・画像合成は、GAN、VAE、自己回帰モデル等を使って行われているがどれも一長一短
・2015年に発表された拡散モデルは安定性と生成サンプルの品質で最近注目を集めている
・拡散モデルを規模拡大しデータ拡張を行ってGANを超える強力な超解像画像の生成に成功
2.拡散モデルとは?
以下、ai.googleblog.comより「High Fidelity Image Generation Using Diffusion Models」の意訳です。元記事の投稿は2021年6月16日、Jonathan HoさんとChitwan Sahariaさんによる投稿です。
diffusion modelは「拡散過程モデル」と日本語訳しているケースも見かけたのですが、人工知能分野ではなく数学分野に見えたので、区別するために拡散モデルとしてみました。
見事な超解像で動かしてみたいですが、残念ながらまだコードは公開されていません。しかし、おそらくコードが公開されても相当な環境(クラウドで言えば何百万円級)でなければ動かせないのではないかと思われます。
diffusionで検索すると出てきたsuper-resolutionっぽくもある星雲(Nebula)のアイキャッチ画像のクレジットはPhoto by NASA on Unsplash
2022年6月追記)個人所有のGPUでも動かす事ができる拡散モデル(diffusion model)の実装がgithubで公開されています
2022年8月追記)Stable Diffusionの論文を探してこのページに来た方は「DALL-E2やStable Diffusion等の拡散モデルの動作原理と説明がつかない事」の方が適切かもしれません。実例を探している方は「Dall-E 2、Midjourney、Stable Diffusionなど文章から画像を生成する人工知能の一覧」や「stable diffusionに同じ絵を描いて貰うためにはどうすれば良いか?」をどうぞ。
自然画像合成(Natural Image Synthesis)は、さまざまなアプリケーションを使用した幅広いクラスの機械学習(ML:Machine Learning)タスクであり、多くの設計上の課題があります。
一例は、画像の超解像(super-resolution)です。モデルは、低解像度の画像を詳細な高解像度の画像(RAISRなど)に変換するようにトレーニングされます。超解像には、古い家族の肖像写真を復元する事から医用画像システムの改善まで、さまざまな用途があります。
別の画像合成タスクは、クラス条件付き画像生成(class-conditional image generation)であり、ラベルを入力されるとそのラベルが示すクラスのサンプル画像を生成するようにモデルがトレーニングされます。結果として生成されたサンプル画像は、画像の分類、セグメンテーションなどの下流工程モデルのパフォーマンスを向上させるために使用できます。
一般に、これらの画像合成タスクは、GAN、VAE、自己回帰モデル(autoregressive models)などの深層生成モデルによって実行されます。しかし、これらの生成モデルのそれぞれには、高解像度のデータセットで高品質のサンプルを合成するようにトレーニングされた場合に困難な欠点があります。たとえば、GANは不安定なトレーニングとモード崩壊に悩まされることが多く、自己回帰モデルは通常、合成速度が遅いことに悩まされます。
代わりに、2015年に最初に提案された拡散モデル(diffusion models)は、トレーニングの安定性と、画像および音声の生成に関する有望なサンプル品質を出力する事により、最近復活しました。つまり、拡散モデルは、他のタイプの深層生成モデルと比較して、潜在的に有利なトレードオフを提供します。
拡散モデルは、ガウスノイズを徐々に追加してトレーニングデータを破損し、純粋なノイズになるまでデータの詳細をゆっくりと消去してから、ニューラルネットワークをトレーニングしてこの破損プロセスを逆転させることで機能します。
この逆破損プロセスを実行すると、クリーンなサンプルが生成されるまでデータから徐々にノイズ除去するんで、純粋なノイズからデータが合成されます。この合成手順は、データ密度の勾配に従って、存在する可能性のあるサンプルを生成する最適化アルゴリズムとして解釈できます。
本日、拡散モデルの画像合成品質の限界を押し上げる2つの密接したアプローチを紹介します。
「繰り返し精密化による超解像(SR3:Super-Resolution via Repeated Refinements)」と「カスケード拡散モデル(CDM:Cascaded Diffusion Models)」と呼ばれるクラス条件付き合成モデルです。
拡散モデルの規模を拡大し、慎重に選択したデータ水増し手法を使用することで、既存のアプローチよりも優れたパフォーマンスを発揮できることを示します。具体的には、SR3は、人間の評価においてGANを超える強力な超解像画像結果を達成します。CDMは、FIDスコアと分類精度スコアの両方でBigGAN-deepとVQ-VAE2を大幅に上回る忠実度の高いImageNetサンプルを生成できます。
SR3:超解像画像
SR3は、低解像度の画像を入力として受け取り、純粋なノイズから対応する高解像度の画像を構築する超解像拡散モデルです。モデルは、純粋なノイズのみが残るまで、ノイズが高解像度画像に徐々に追加される画像破損プロセスでトレーニングされます。次に、純粋なノイズから始めて、このプロセスを逆にすることを学習します。入力された低解像度画像のガイダンスを通じて、ターゲット分布に到達するためにノイズを徐々に除去します。

(訳注:元投稿は41秒38MBのMP4動画です。サイズが大きかったので画像1枚だけ張り付けています。というか、ヒントン先生ってフリー素材扱いで良いのか!?まぁ、カッコ良いからいいか、とは思いました。)
SR3は、大規模なトレーニングにより、入力された低解像度画像を4倍から8倍の解像度に規模拡大するときに、顔画像と自然画像の超解像タスクで強力なベンチマーク結果を達成します。これらの超解像モデルをさらに組み合わせて、超解像の解像度を更に上げる事ができます。
たとえば、64×64 → 256×256と256×256 → 1024×1024の顔の超解像モデルを積み重ねて、64×64 → 1024×1024の超解像タスクを実行できます。
そして、人間による評価を使用して、SR3を従来手法と比較します。
「どの画像がカメラで撮影したものだと思いますか?」
と被験者に対して「参照用の高解像度画像」と「モデルが出力した画像」を見せて、どちらかを選択するように質問する二者択一強制選択実験(Two-Alternative Forced Choice Experiment)を実施しました。
混同率(confusion rates)を通じてモデルのパフォーマンスを測定します。以下のグラフでは横軸(%)の割合で評価者は、参照画像ではなくモデル出力を選択しました。見分けがつかないほど完全なアルゴリズムであれば、混同率は50%になります。調査結果を下図に示します。
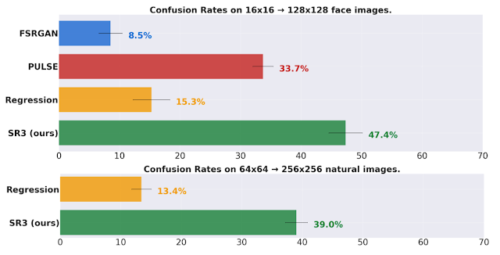
上図:16×16→128×128の顔のタスクで、ほぼ50%の混合率を達成し、顔に関する最先端の超解像手法であるPULSEおよびFSRGANを上回っています。
下図:64×64→256×256の自然画像というはるかに難しいタスクでも40%の混合率を達成し、比較対象である回帰モデルを大幅に上回っています。
3.拡散モデルを使用してGANより忠実度の高い画像を生成(1/2)関連リンク
1)ai.googleblog.com
High Fidelity Image Generation Using Diffusion Models
2)arxiv.org
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Improved Denoising Diffusion Probabilistic Models
3)iterative-refinement.github.io
SR3:Image Super-Resolution via Iterative Refinement
4)cascaded-diffusion.github.io
Cascaded Diffusion Models for High Fidelity Image Generation

