
1.MURAL:ヒンディー語で野菜を入れない素の麺が入った丼を検索されても対応画像を探せる人工知能(1/2)まとめ
・概念の多くは、ある言語から別の言語への直接的に一対一に翻訳する事ができない
・連想するものが異なるためだが概念のイメージを見せると意味をより明確にできる
・MURALは100言語以上の翻訳ペアと画像-文章ペアで学習しておりこの課題に対応可能
2.MURALとは?
以下、ai.googleblog.comより「MURAL: Multimodal, Multi-task Retrieval Across Languages」の意訳です。元記事は2021年11月30日、Aashi JainさんとYinfei Yangさんによる投稿です。
MURAL(ミューラル)は英語で壁画を意味する単語という事で、お洒落なアイキャッチ画像のクレジットはPhoto by Annie Spratt on Unsplash。(タイトルでお洒落感を台無しにした感ありますが、後半に出てくる事例はそれほど衝撃的だったので)
概念の多くは、ある言語から別の言語への直接的に一対一に翻訳する事ができません。
たとえ、翻訳する事が出来たとしても、その翻訳はしばしば異なる連想や意味合いを持ち、翻訳元言語が母国語でない話者にとっては理解が困難になります。
しかし、そのような場合、視覚的な例で説明すると、意味がより明確になることがあります。例えば、「結婚式(wedding)」という言葉。英語では、白いドレスの花嫁とタキシードの花婿を連想しますが、ヒンディー語(शादी)では、鮮やかな色の花嫁とシェルワニを着た花婿を連想するのが適切でしょう。
人によって連想するものはかなり違うかもしれませんが、意図する概念のイメージを見せられると、意味がより明確になります。

英語とヒンディー語で「結婚式(wedding)」という言葉は、それぞれ異なる心象風景を伝えてくれます。
画像はwikipediaから引用。CC BY-SA 4.0ライセンスに基づき、クレジットは左画像はPsoni2402、右画像はDavid McCandless
現在のニューラル機械翻訳と画像認識の進歩により、文章とそれを補足する画像のペアを提示することで、このような翻訳の曖昧さを低減することが可能になっています。
先行研究では、英語などの高リソース言語に対する画像-テキスト結合特徴表現の学習が大きく進展しています。これらの特徴表現モデルは、画像とテキストを一緒に共有embedding 空間のベクトルに符号化し、その空間において画像とそれを説明するテキストが互いに近接するように学習する事でこれを実現しています。
例えば、ALIGNとCLIPは、対照学習損失を用いて画像とテキストのペアに対してデュアルエンコーダーモデル(すなわち、2つの別々のエンコーダーで学習したモデル)を学習させると、十分な学習データが与えられた場合に驚くほどうまくいくことを示しました。
残念ながら、このような画像とテキストがペアになっているデータセットは、大多数の言語では大規模なデータセットとしては存在しません。実際、インターネットから収集可能なこの種のデータの90%以上は、英語や中国語など利用可能なリソースが豊富な上位10言語に属しており、リソースの少ない言語のデータは非常に少ないのが実情です。
この問題を解決するためには、リソースが不足している言語の画像とテキストのペアデータを手作業で集める事が考えられますが、大規模に収集する事は法外に困難です。
あるいは、翻訳ペアデータセットなど既存のデータセットを活用して、複数言語に対応する特徴表現の学習手段を提供することが考えられます。
Findings of EMNLP 2021で発表した論文「MURAL: Multimodal, Multitask Retrieval Across Languages」では、画像-文章マッチング用の特徴表現モデルについて述べています。MURALは、100以上の言語をカバーする翻訳ペアと画像-文章ペアを用いてマルチタスク学習を行っています。
この技術により、翻訳先言語への直接的な翻訳がない単語を画像で表現できるようになる可能性があります。
例えば、マダガスカル人が演奏する管楽器の一種である「ヴァリハ(Valiha)」という言葉は、ほとんどの言語に直訳できません。しかし、画像を使えば簡単に表現することが可能です。
経験的に、MURALは最先端のモデル、他のベンチマーク、競合のベースラインに対して、全面的に一貫した改善を示しています。さらに、MURALはテスト対象となったリソース不足の言語の大部分に対して、驚くほど良好な結果を示しています。さらに、我々はMURALの特徴表現によって学習された興味深い言語的相関関係を発見しました。
MURALの構成
MURALアーキテクチャは、ALIGNの構造をベースに、マルチタスク方式が採用されています。ALIGNがデュアルエンコーダーアーキテクチャを使用して画像の特徴表現と関連するテキストを一緒に描く事が出来るのに対して、MURALは同じ目的のためにデュアルエンコーダー構造を採用し、翻訳ペアを組み込むことによって複数言語に拡張しています。画像とテキストのペアのデータセットはALIGNに使われたものと同じであり、翻訳ペアはLaBSEに使われたものです。
MURALは2つの対照学習タスクを学習します。
(1)画像-テキストマッチング
(2)テキスト-テキスト(bitext)マッチング
この2つのタスクはテキストエンコーダーモジュールを共有しています。
このモデルは、画像-テキストデータから画像とテキストの関連付けを学習し、翻訳ペアから数百の多様な言語の特徴表現を学習します。
背後にあるアイディアは、共有エンコーダーが、高リソース言語から学習した画像とテキストの関連付けを、リソースが不足している言語にも伝達するのではないかという事です。
私たちは、EfficientNet-B7画像エンコーダとBERT-largeテキストエンコーダを一から学習させたモデルが最適であることを発見しました。学習された特徴表現は、下流の視覚タスクや視覚言語タスクに利用することができます。
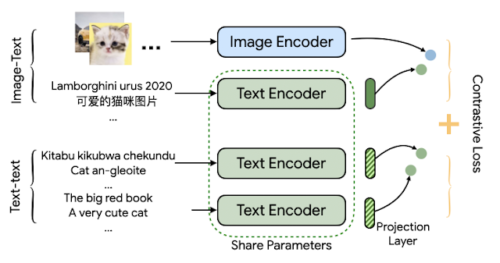
MURALのアーキテクチャは、2つのタスク間でテキストエンコーダを共有するデュアルエンコーダであり、対照学習損失を用いて学習されます。
3.MURAL:ヒンディー語で野菜を入れない素の麺が入った丼を検索されても対応画像を探せる人工知能(1/2)関連リンク
1)ai.googleblog.com
MURAL: Multimodal, Multi-task Retrieval Across Languages
2)arxiv.org
MURAL: Multimodal, Multitask Retrieval Across Languages

