
1.Google Research:2019年の振り返りと2020年以降に向けて(5/8)まとめ
・2019年はニューラルネットワークのトレーニングにどのような力学が働くのか特性を理解を目指した
・AutoMLの研究も継続し、既存モデルの改良や特定ハードに特化したモデルなど様々な改良を実施
・表形式データの取り扱いに特化したAutoML Tablesはデータサイエンティストのコンペで好成績収めた
2.機械学習アルゴリズムとAutoML
以下、ai.googleblog.comより「Google Research: Looking Back at 2019, and Forward to 2020 and Beyond」の意訳です。元記事の投稿は2020年1月9日、Google Research部門トップのJeff Deanさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Benjamin Davies on Unsplash
(9)機械学習アルゴリズム
2019年、様々な角度から機械学習アルゴリズムと手法に関する調査を実施しました。主な焦点の1つは、ニューラルネットワークのトレーニングにはどのような力学が働くのかについて特性を理解することでした。ブログ記事「Measuring the Limits of Data Parallel Training for Neural Networks」で、Googleの研究者は論文内で行った慎重な一連の実験結果を投稿しました。
(バッチサイズをより大きくする事により)量の観点からデータ並列処理を規模拡大することが、(データ並列処理を使用して)モデルをより速く収束させるのに効果的であることを示したのです。
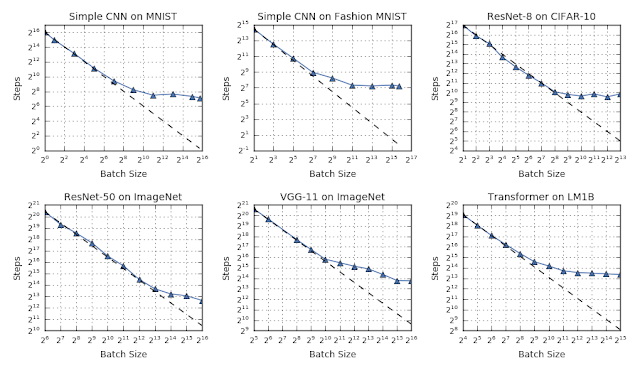
テストした全てのケースにおいて、バッチサイズとトレーニング速度に普遍的な関係が観察されました。3つの明確な段階が存在するのです。
1)小さいバッチサイズではバッチサイズが増えるにつれて収束速度が増します(破線部分)
2)ある程度バッチサイズが大きくなると収束速度はそれほど増えなくなります(破線から離れる)
3)最大のバッチサイズで最大データ並列性が達成されます(傾きが水平になる)
どの時点で段階が移行するかはケースによって全く異なります。
モデルの並列性は、データの並列性、すなわちモデルを複数の計算デバイスに分散する事とは対照的に、モデルの規模を拡大する効果的な方法です。GPipeは、CPUプロセッサが並列処理実現のために行っているパイプライン処理と同様のアプローチで、モデルの並列性をより効果的に実現するライブラリです。モデルの一部がデータの一部を処理している場合、他の部分は異なるデータの一部を処理できます。このパイプラインアプローチの結果を組み合わせて、より大きな有効なバッチサイズをシミュレートできるのです。
機械学習モデルは、未加工の入力データから、「解きほぐされた(disentangled)高レベルの特徴表現」を学習できる場合に有用です。「解きほぐされた(disentangled)高レベルの特徴表現」とは私達がモデルが区別できるようになって欲しい、サンプルによって異なる属性です。例えば風景写真から「猫とトラックとヌー(哺乳綱ウシ目ウシ科の動物)」を区別できる事やレントゲン写真から「癌になった組織と正常な組織」を区別する事などです。
(訳注:「猫の特徴を認識した」などの大ざっぱな特徴認識ではなく、トラックはタイヤがあるからトラックで、ヌーは角があるからヌーなんだ、等のより具体的な特徴を抽出するのが「解きほぐされた(disentangled)高レベルの特徴表現」の意です)
機械学習アルゴリズムの進歩として重点を置いているのは、新しいサンプル、問題、または領域により適切に一般化する、より良い特徴表現の学習を促進することです。今年は、この問題をさまざまな状況で検討しました。
・ブログ投稿「Evaluating the Unsupervised Learning of Disentangled Representations」では、解きほぐされた特徴表現を教師なし学習で評価し、優れた特徴表現と効果的な学習に役立つものをよりよく理解するために、教師なしデータから学習した特徴表現にどのような属性が影響するかを調べました。
・論文「Predicting the Generalization Gap in Deep Neural Networks」では、マージンがどのように分布しているかの統計を使用して一般化ギャップを予測できることを示しました。
(訳注:AとBを分類する時、AとBの間にはマージン(余白)があって、そのマージンのどこかに、「こっちに寄るとA」、「こっちに寄るとB」という判断軸があるわけですが、その軸がA側に寄っているとAを厳密に認識できますが、どちらかというとAっぽいものもBと判断される事になります。そのため、マージンがどのようになっているかを調べるとモデルの一般化性能、つまりAっぽいものをどこまでAとして認識できるかという分類性能もわかります、ってお話でした)
一般化ギャップとは学習時に使ったトレーニングデータに対するモデルのパフォーマンスと、学習時に使ったデータとは異なるデータにおけるモデルのパフォーマンスのギャップです。これは、どのモデルが最も効果的に一般化されているかをよりよく理解するのに役立ちました。
また、モデルがこれまでに扱った事のない種類のデータに遭遇した時の挙動をよりよく理解するために、機械学習モデルでのOut-of-Distribution(分類外データ)の改善に関する調査も行いました。また、どのモデルが最も一般化される可能性が高いかをよりよく理解するために、強化学習を使ってオフポリシー分類を検討しました。

・論文「Learning to Generalize from Sparse and Underspecified Rewards」では、強化学習で取り扱う事が難しい、疎で不十分な報酬しか定義できない状態で、強化学習のための報酬関数を指定する方法も検討しました。これにより、学習システムが真の目的からより直接的に学習し、長時間にわたって気を散らすことが少なくなります。
(訳注:例えば、「迷路を解く」というお題は、前進する事がゴールに近づいているのか否かがわからないので、報酬を与える適切なタイミングがほとんどないので「疎な報酬」しか与えられず強化学習で扱う事が難しいと言うお話で、これは人間も「疎な報酬」では中々やる気を出せないのでやっぱり人工知能と人間の脳って似てますよねってお話でした)
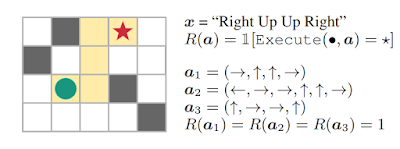
「右、上、上、右」という指示に従うタスクでは、a1(右、上、上、右)、a2(左、右、右、上、上、右)、a3(上、右、右、上)の行動は全て目標地点★に到達しますが、a2、a3は指示に従っていませんがゴールに到達して報酬を得る事になってしまいます。これは、不十分な報酬の問題を示しています。
(10)AutoML
今年もAutoMLの研究を継続しました。AutoMLは「学習方法を学習するアルゴリズム」で機械学習モデルを設計する際に必要な作業の多くを自動化できます。機械学習設計に関して最高の知識を持つ人間の専門家よりもはるかに優れたモデルをしばしば作り上げるアプローチです。
今年の成果は、以下です。
・「EfficientNet: Improving Accuracy and Efficiency through AutoML and Model Scaling」では、ニューラルアーキテクチャを自動で探索する手法を使用して、コンピュータービジョンの課題解決に非常に優れた結果を達成する方法を示しました。これには、従来の最高性能モデルよりも8倍少ないパラメーター数しか持たないmodelで、最先端の結果(ImageNetで84.4%のtop-1 accuracy)を達成したという事実が含まれます。
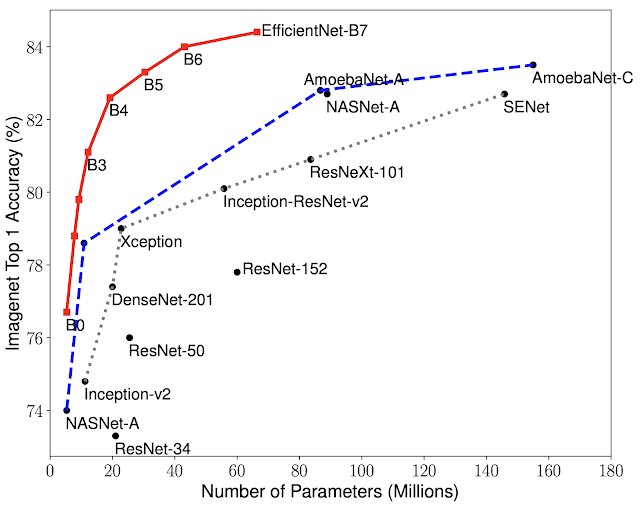
モデルサイズと精度の比較。 EfficientNet-B0はAutoML MNASによって開発された基準となるベースラインネットワークであり、Efficient-B1からB7はベースラインネットワークの規模を拡大したモデルです。 特に、私達のEfficientNet-B7は、最高水準の84.4%top-1/97.1%top-5の精度を実現しながら、既存の最高のCNNモデルよりも8.4倍小さくなっています。
・「EfficientNet-EdgeTPU: Creating Accelerator-Optimized Neural Networks with AutoML」では、ニューラルアーキテクチャを自動で探索するアプローチが、特定のハードウェアアクセラレータに特化した効率的なモデルを見つける事が出来る事を示しました。計算能力が高くないモバイルデバイスで実行する事に特化した、高精度なモデルを自動で設計する事に成功したのです。
・「Video Architecture Search」では、AutoMLを動画を扱うビデオモデルの領域に拡張し、最先端の結果を達成するアーキテクチャを見つける方法について解説しています。必要な計算能力を50分の1に削減しつつ、人間の専門家が手動で設計したモデルのパフォーマンスに匹敵する軽量のアーキテクチャを作り上げました。
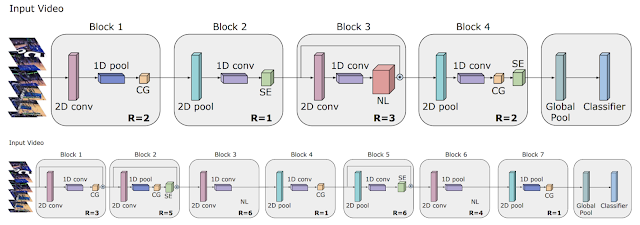
TinyVideoNet(TVN)アーキテクチャは、ビデオ認識にかかる所要時間を希望の制限内に保ちながら認識精度を最大化するために進化しました。例えば、 TVN-1(上)はCPU上では37ミリ秒、GPUでは10ミリ秒で実行されます。TVN-2(下)は、CPU上で65ミリ秒、GPU上で13ミリ秒で実行されます。
・多くの企業や組織はデータベースに興味深い独自データを所有しています。そして、多くの場合、この独自データを取り扱う事の出来る機械学習モデルを開発したいと考えています。そのため、私達は、データベースに格納されている表形式のデータを扱う事の出来る技術をGoogle Cloud AutoML Tablesとして製品化しました。
また、AutoML Tablesがデータサイエンティストが集うコンペサイトであるKaggleのコンペでどの程度通用するかについて挑戦しました。(ネタバレ:AutoML Tablesは、熟練したデータサイエンティストからなる74チームの中で、2位の成績を納めました)
・「Exploring Weight Agnostic Neural Networks」の中では、学習せずとも本能のように特定の機能を実現できる興味深いニューラルネットワークアーキテクチャを見つける方法を探りました。これにより、ニューラルネットワークのアーキテクチャを探索する際の計算効率が大幅に向上します。
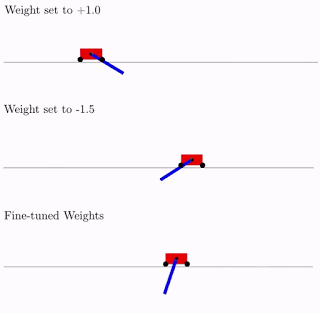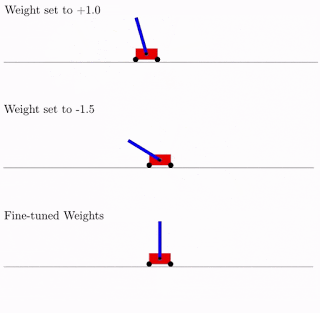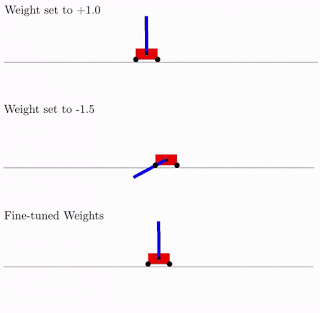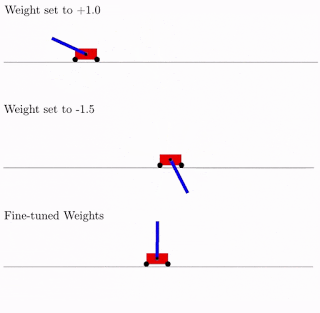
重みに依存しないニューラルネットワーク(weight-agnostic neural network)に2種類の重みパラメーターでCartpole Swing-upタスクを実行させた結果と、微調整した重みパラメータで実行させた結果
・AutoMLをTransformerアーキテクチャに適用することで、大幅に計算コストを削減しつつ、素のTransformerモデルを大幅に上回る自然言語処理タスク用のアーキテクチャ、Evolved Transformerを見つける事に成功しました。
Evolved Transformerと素のTransformerの比較。様々なパラメータサイズでWMT’14 En-Deタスクを実行したスコアを比較しています。パフォーマンスが最も向上しているのは小さなサイズですが、Evolved Transformerは大きなサイズでも強みを示し、37.6%少ないパラメーターで素のTransformerの最大モデルサイズのスコアを凌駕しています。(緑色の丸で囲んだ部分の比較です)。正確な数値については、論文「The Evolved Transformer」の表3を参照してください。
・「SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition」では、学習用データを水増しするアプローチを音声認識モデルに拡張できることを示しました。水増し方法を自動的に学習するこのアプローチにより、既存の人間の機械学習エキスパートが行うデータ増強アプローチよりも少ないデータで大幅に高い精度を達成します。
・「Improving Keyword Spotting and Language Identification via Neural Architecture Search at Scale」ではAutoMLを使用した初の音声アプリケーションについて発表しました。「キーワードの抽出」と「話されている言語の識別」をする事が出来、私達の実験では、人間が設計した従来のモデルよりも(効率とパフォーマンスの両方で)優れたモデルとなりました。
3.Google Research:2019年の振り返りと2020年以降に向けて(5/8)関連リンク
1)ai.googleblog.com
Google Research: Looking Back at 2019, and Forward to 2020 and Beyond
2)research.google
Publication database(2019)
Optimization of Molecules via Deep Reinforcement Learning
AVA
3)modelcards.withgoogle.com
Object Detection Model Card v0 Cloud Vision API
4)ai.google
Working together to apply AI for social good
5)blog.google
Using AI to give people who are blind the “full picture”
What our quantum computing milestone means
Teachable Machine 2.0 makes AI easier for everyone
Google for Startups Accelerator empowers AI startups in Europe
6)support.google.com
Get image descriptions on Chrome
7)federated.withgoogle.com
Federated Learning An online comic with google AI
8)arxiv.org
The Evolved Transformer
9)www.isca-speech.org
Improving Keyword Spotting and Language Identification via Neural Architecture Search at Scale
10)github.com
google / jax
11)leogao.dev
The Decade of Deep Learning

コメント