
1.GPipe:大規模ニューラルネットワークを効率的に訓練するオープンソースライブラリ(1/3)まとめ
・最近のニューラルネットワークはTPUアクセラレータのメモリに収めるのが難しいくらい巨大化している
・しかし、性能とパラメータ数には強い相関がありニューラルネットワークの大規模化は避けえない
・GPipeはモデルとデータを分割して学習させる事により大規模ネットワークの学習を可能にする
2.GPipeとは?
以下、ai.googleblog.comより「Introducing GPipe, an Open Source Library for Efficiently Training Large-scale Neural Network Models」のまとめです。
元記事は2019年3月4日、Yanping Huangさんによる投稿です。
最近の大規模ニューラルネットワークモデルは性能が飛躍的に向上していますが、サイズも同時に巨大化しており、TPUv2のメモリ内に収める事が難しくなってきています。このような巨大モデルも本投稿で紹介するGPipeを使うと分割して効率良くトレーニング可能になるとのお話です。
2021年12月追記)後続研究の「GSPMD:ニューラルネットワークの規模拡大を可能にする汎用的な並列化手法」が発表されています。
ディープニューラルネットワーク(DNN)は、音声認識、視覚認識、および言語処理を含む多くの機械学習タスクを進めてきました。
BigGan、BERT、およびGPT2.0による最近の進歩は、ますます大きなDNNモデルがより優れたパフォーマンスをもたらすこと、および視覚認識タスクにおける過去の進歩も、モデルサイズと分類精度との間に強い相関関係がある事を示しました。たとえば、2014年のImageNet視覚認識チャレンジの勝者はGoogleNetで、400万個のパラメータで74.8%のTop-1 Accuracy(モデルが最初に提示したラベルが正解である確率)を達成しましたが、わずか3年後の2017年のImageNetチャレンジの勝者はSqueeze-and-Excitation Networksでした。 これは、145.8百万(36倍以上)のパラメータで82.7%のTop-1 Accuracyを達成しました。
ただし、同じ期間にGPUメモリは約3倍にしか増えておらず、現在の最先端の画像モデルはすでにCloud TPUv2で利用可能なメモリの上限に達しています。
したがって、大規模なディープラーニングを可能にし、現在のアクセラレータのメモリ制限を克服する、効率的でスケーラブルなインフラストラクチャが強く切迫して必要とされています。
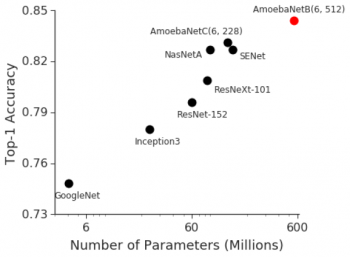
最近開発された代表的な画像分類モデルに対するImageNet精度とモデルサイズの間の強い相関
論文「GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism」では、この制限を克服するためにDNNトレーニングをスケールアップするためのパイプライン並列処理の使用について説明しています。
GPipeは、トレーニングのために同期型確率勾配降下法とパイプライン並列処理を使用する分散型機械学習ライブラリで、複数の連続した層で構成されるあらゆるDNNに適用できます。重要なことは、GPipeは研究者がより大きなモデルを訓練し、そしてハイパーパラメーターを調整することなしに性能を拡大するために、より容易により多くのアクセラレータの使用を可能にする事です。
GPipeの有効性を実証するために、Google Cloud TPUv2上で、5億5700万個のモデルパラメータと480×480の入力画像サイズで、AmoebaNet-Bをトレーニングしました。このモデルは、シングルクロップのImageNetの精度を84.3%に、CIFAR-10の精度を99%に、CIFAR-100の精度を91.3%にするなど、複数の一般的なデータセットでうまく機能しました。コアGPipeライブラリはLingvoフレームワークの下でオープンソース化されています。
ミニバッチからマイクロバッチへ
中規模DNNモデルを高速化する手法には、2つの標準的な方法があります。データ並列処理アプローチでは、より多くのマシンを使用し、入力データを分割してそれらに任せます。もう1つの方法は、モデルをGPUやTPUなどのモデルトレーニングに特化した特別なハードウェアを備えたアクセラレータで処理する事です。ただし、アクセラレータはメモリが限られており、ホストマシンとの通信帯域幅が限られています。
そのため、モデルを細かく分割し、分割した個々のモデルを個々のアクセラレータに割り当てることによって、アクセラレータで大きなDNNモデルをトレーニングするには、モデルの並列処理が必要です。しかし、DNNは順番に処理をこなす性質があるため、この単純な方法では、計算中に1つのアクセラレータしか有効アクティブにならず、アクセラレータの計算能力が著しく低下します。
一方、標準のデータ並列処理アプローチは、複数のアクセラレータで異なる入力データを使用して同じモデルを同時にトレーニングすることはできますが、アクセラレータがサポートする最大のモデルサイズを増やすことはできません。複数のアクセラレータにまたがる効率的なトレーニングを可能にするために、GPipeはモデルを異なるアクセラレータにまたがって分割し、ミニバッチのトレーニングサンプルを自動的により小さなマイクロバッチに分割します。
マイクロバッチを用いて経由で実行をパイプライン化することによって、アクセラレータは並行して動作することができます。さらに、勾配はマイクロバッチ全体で一貫して累積されるため、パーティションの数はモデルの品質に影響しません。
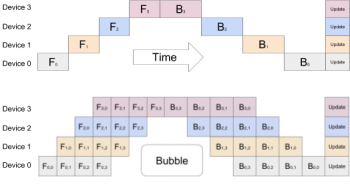
上図:シンプルな並列処理では、ニューラルネットワークの逐次的性質のために、十分にアクセラレータが活用されません。一度にアクティブになるアクセラレータは1つだけです。下図:GPipeは入力ミニバッチをより小さなマイクロバッチに分割し、異なるアクセラレータが別々のマイクロバッチで同時に作業できるようにします。
(GPipe:大規模ニューラルネットワークを効率的に訓練するオープンソースライブラリ(2/3)に続きます)
3.GPipe:大規模ニューラルネットワークを効率的に訓練するオープンソースライブラリ(1/3)関連リンク
1)ai.googleblog.com
Introducing GPipe, an Open Source Library for Efficiently Training Large-scale Neural Network Models
2)arxiv.org
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
3)github.com
lingvo/lingvo/core/gpipe.py
