
1.ニューラルネットワークの並列訓練の限界を測定(1/2)まとめ
・バッチサイズとトレーニング時間の減少の関係を追及した論文が発表
・作業負荷によって異なるがどのような最適化/データ/モデルも3つの段階がある事を確認
・サイズに比例して時間を減らせる段階、時間が徐々に減らなくなる段階、全く減らない段階
2.バッチサイズとトレーニング時間の普遍的な関係
以下、ai.googleblog.comより「Measuring the Limits of Data Parallel Training for Neural Networks」の意訳です。元記事は2019年3月19日、 Chris ShallueさんとGeorge Dahlさんによる投稿です。
過去10年間で、ニューラルネットワークは、画像分類、機械翻訳、および音声認識など、さまざまな予測タスクで従来手法を上回る結果を達成してきました。これらの成功は、少なくとも部分的には、ニューラルネットワークのトレーニングを著しく加速させたハードウェアとソフトウェアの改良によってもたらされました。
より迅速なトレーニングにより、より多くのトレーニングデータを処理できるようになり、且つ研究者が新しいアイデアや構成をより迅速に試すことができるようになるので、モデル品質は劇的に向上しました。
現在、Cloud TPU Podsのようなハードウェア開発はニューラルネットワークトレーニングに利用可能な計算量を急速に増加させています。これはニューラルネットワークをさらに速く訓練しモデル品質のさらなる改善を促進する可能性を高めます。
しかし、これまでにない膨大な量の計算を必要とする作業はどこまで制御可能なのでしょうか?より迅速なトレーニングを実現するためには常により多くの計算機が存在する事を期待すべきでしょうか?
大規模な計算機能力を利用する最も一般的な方法は、異なるプロセッサ間で計算を分散し、それらの計算を同時に実行することです。ニューラルネットワークをトレーニングする場合、これを達成するための主な方法は並列処理です。これには「ニューラルネットワークを異なるプロセッサに分散させるモデルの並列化」と、「トレーニングサンプルを異なるプロセッサに分散しニューラルネットワークへの更新を並列処理するデータの並列化」が含まれます。
モデル並列処理は単一プロセッサがサポートできるよりも大きいニューラルネットワークを訓練することを可能にしますが、モデルのアーキテクチャを利用するハードウェアに合わせる事が通常必要となります。
対照的に、データ並列処理はモデルにとらわれず、あらゆるニューラルネットワークアーキテクチャに適用可能です。これは、ニューラルネットワークのトレーニングを並列化するための最も単純で最も広く使用されている手法です。
最も一般的なニューラルネットワークトレーニングアルゴリズム(同期確率的勾配降下法とその変形)では、データ並列処理の規模はバッチサイズ、つまりニューラルネットワークへの各更新の計算に使用されるトレーニングサンプルの数に対応します。しかし、このタイプの並列化の制限は何でしょうか?また、大幅な高速化が見込まれるのはどこからどこまでしょうか?
論文「Measuring the Effects of Data Parallelism in Neural Network Training」では、3つの異なる最適化アルゴリズム(オプティマイザ)を使用して7つの異なるデータセットにわたって6つの異なるタイプのニューラルネットワークで実験を行い、バッチサイズとトレーニング時間の関係を調べました。
合計で、約450のワークロードで10万を超える個々のモデルをトレーニングし、テストしたすべてのワークロードにわたってバッチサイズとトレーニング時間の間に一見普遍的な関係があることを観察しました。
また、この関係がデータセット、ニューラルネットワークアーキテクチャ、およびオプティマイザーによってどのように変化するかを調べたところ、ワークロード間で非常に大きな変化が見られました。さらに、私たちは研究コミュニティによるさらなる分析のために私たちの生データを共有することに興奮しています。
このデータには、私たちが訓練した10万以上の個々のモデルの訓練曲線を作成するための71Mを超えるモデル評価が含まれており、私たちの論文の24のプロットを全て再現する事ができます。
バッチサイズとトレーニング時間の普遍的な関係
ごくわずかな時間をプロセッサ間の同期に費やす理想的なデータ並列システムでは、トレーニング時間はトレーニングステップの数(ニューラルネットワークのパラメータを更新する回数)で測定することができます。
この仮定の下で、我々はバッチサイズとトレーニング時間との間の関係において3つの異なるスケーリング段階を観察しました。
バッチサイズを2倍にすると、目標に達するのに必要なトレーニングステップ数が半分になる「完全なスケーリング段階」。その後、バッチサイズを増やしてもトレーニングステップがあまり減らない「収益減少段階」が続きます。そして最後に、「最大データ並列処理段階」では、バッチサイズをさらに増やしても、理想的なハードウェアの状況下であってもトレーニング時間はこれ以上短縮できません。
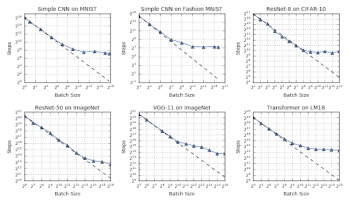
テストしたすべてのワークロードについて、バッチサイズとトレーニング速度の間に普遍的な関係、3つの異なる段階がある事が観察できました。完全なスケーリング段階(破線)、収益減少段階(破線から発散)、および「最大データ並列処理段階」(トレンドが横ばいに変化)。 段階間の移行点は、異なるワークロード(作業負荷)間で劇的に異なります。
3.ニューラルネットワークの並列訓練の限界を測定(1/2)関連リンク
1)ai.googleblog.com
Measuring the Limits of Data Parallel Training for Neural Networks
2)arxiv.org
Measuring the Effects of Data Parallelism on Neural Network Training

コメント