
1.教師なし学習による特徴表現解きほぐし手法の評価(1/2)まとめ
・抽出した特徴量をもっと細かく具体的な単位に解きほぐすdisentangledな手法が注目されている
・「猫の特徴」ではなく耳と目と輪郭と毛色から猫を特定できれば一部が写ってなくても猫が特定できる
・様々な側面から研究が行われているが、個々の手法を同じ土俵で評価しようとする試みは従来なかった
2.disentangled representationsとは?
以下、ai.googleblog.comより「Evaluating the Unsupervised Learning of Disentangled Representations」の意訳です。元記事は2019年4月24日、Olivier Bachemさんによる投稿です。
高次元データを理解し、そこから得た知識を教師なしで有用な特徴表現に蒸留する能力は、依然としてディープラーニングにおける重要な課題です。これらの課題を解決するための1つのアプローチは、disentangled representationsです。
訳注:「disentangled representations」は、私の知る限り、まだ良い感じの日本語訳がないようです。直訳すると「解きほぐされた特徴表現」です。例えば、「人工知能が猫を認識できるようになった」と言う事は「猫の特徴」を理解したと言う事ですが、「猫の特徴」と言っても大ざっぱすぎるのでもうちょっと詳しく注目した特徴を具体的に細分化して貰いましょう、例えば、顔が丸いとか、耳がとがっているとか、って考え方が「disentangled representations」、すなわち「特徴の解きほぐし」です。教師あり学習だと、学習用データの「細分化して欲しい箇所」にラベルを一々付ける事になるので、それはやってられないので教師無し学習でdisentangled representationsをして欲しいですよね、って事が今回のお話の背景です。
disentangledなモデルとは特徴Aが変化しても特徴Bが影響を受けないような、個々の独立した特徴を捉えるモデルです。これに成功すれば、自動運転自動車やロボットなど、実世界をナビゲートするように設計された機械学習システムは、オブジェクトやその周辺から様々な要因や特性を解きほぐして学習する事が可能になり、今まで見た事がない状況にも対応できるようになります。
教師なし学習による特徴表現の解きほぐしは、好奇心駆動型探査(curiosity driven exploration)、抽象推論(abstract reasoning)、視覚概念学習(visual concept learning)および強化学習のためのドメイン適応(domain adaptation for reinforcement learning)、などの既存研究で既に使用されていますが、最近のこの分野における進捗は、異なるアプローチがどの程度うまく機能するのかおよびその限界を把握する事を困難にしています。
論文、「Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations」(ICML 2019で発表)で、私達は最近の教師なし解きほぐし法について大規模な評価を行い、解きほぐし学習に関する将来の研究にいくつかの改善を提案する事に挑戦しています。
この評価は、7つの異なるデータセットに関する再現可能な大規模実験の結果で、最も有名な方法と評価指標をカバーするように12,000以上のモデルをトレーニングしています。
重要な事は、この調査で使用されたコードと10,000以上の事前トレーニングされた解きほぐしモデルの両方を公開した事です。結果として得られたライブラリdisentanglement_libは、他の研究者がこの分野における彼ら自身の研究に本成果を活用し、そして私達の経験的結果を容易に複製し検証することを可能にします。
解きほぐしの理解
絡み合っていない特徴表現として符号化できる画像の真の特性をよりよく理解するために、まずShapes3Dデータセットの真の特性について考えてみましょう。
下図のおもちゃモデルでは、各画像はベクトル表現にエンコードできる画像の1つの特性を表します。それぞれ、中央のオブジェクトの形状、サイズ、カメラの回転、および床、壁、オブジェクトの色として定義される特性です。
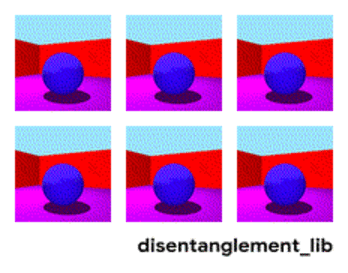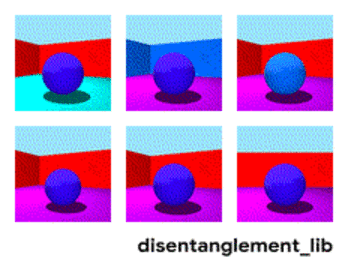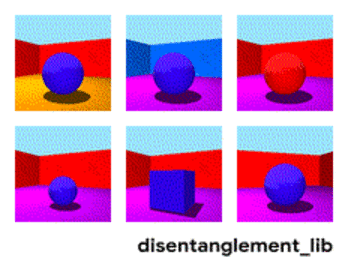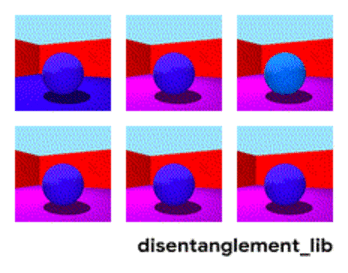
Shapes3Dデータセットの真の特性の視覚化。床の色(左上)、壁の色(上段中央)、オブジェクトの色(右上)、オブジェクトのサイズ(左下)、オブジェクトの形状(下段中央)、そしてカメラの角度(右下)。
解きほぐした特徴表現の目的は、これらの説明可能な要因をベクトルとして捉える事ができるモデルを構築することです。
下の画像は、10次元の特徴表現ベクトルを持つモデルを表しています。10個の画像は、それぞれ異なる特徴表現のうちの1つで、どの情報が絡まっているかを視覚化しています。右上と上段中央の画像から、モデルは床の色をうまく解きほぐしているのに対し、左下の2つの画像はオブジェクトの色とサイズがまだ絡まっていることを示しています。

FactorVAEモデルによって学習された潜在次元の可視化。
カメラの回転だけでなく、壁と床の色も解きほぐされています(右上、上段中央と下段中央を参照)。一方、物体の形状、サイズ、色は解きほぐしできていません。左下の2つの画像)
3.教師なし学習による特徴表現解きほぐし手法の評価(1/2)関連リンク
1)ai.googleblog.com
Evaluating the Unsupervised Learning of Disentangled Representations
2)arxiv.org
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
