
1.EfficientNet-EdgeTPU:アクセラレータでの実行に最適化したニューラルネット(1/2)まとめ
・ハードウェアアクセラレータ上での実行に最適化したニューラルネットワークはあまり存在しない
・AutoMLで最適化したEfficientNetsを更にエッジ上での実行に最適化したEfficientNet-EdgeTPUが発表
・Coralのハードウェア製品を通じてEfficientNet-EdgeTPUの性能と電力効率を利用可能
2.EfficientNet-EdgeTPUとは?
以下、ai.googleblog.comより「EfficientNet-EdgeTPU: Creating Accelerator-Optimized Neural Networks with AutoML」の意訳です。元記事は、2019年8月6日、Suyog GuptaさんとMingxing Tanさんによる投稿です。
ムーアの法則で説明されているように、数十年にわたって、コンピュータープロセッサは、各チップ内のトランジスターのサイズを縮小することで、2年ごとにパフォーマンスを2倍にしています。トランジスタサイズを縮小することがますます困難になるにつれて、業界では、ハードウェアアクセラレータなどの特定作業に特化したアーキテクチャを開発して、計算能力を向上させ続けることに新たな焦点が置かれています。
これは、ニューラルネットワーク(NN)の計算用に特別なアーキテクチャを開発している機械学習の場合に特に当てはまります。
皮肉なことに、これらのアーキテクチャはデータセンターやエッジコンピューティングプラットフォームで着実に普及してきましたが、それらの専用ハードウェアを用いて実行されるNNは、基盤となる専用ハードウェアの特徴をフル活用するためにカスタマイズされることはめったにありません。
訳注:エッジとは、直訳すれば先端部。私達の身近な場所に存在するマイクロセンサーやカメラなどのIoTデバイスの事です。これらは温度や位置情報、画像情報など様々な情報を収集できますが、収集した情報を自身で処理するほど処理能力は高くないため、従来は情報をクラウドに送ってクラウドから来る指示を実行するような使われ方をしていました。しかし、実は人工知能をこういったエッジで活用できる事がわかってきて、エッジで人工知能を動かすと従来は到底実現できなかったような便利な事が沢山できそうだ、と言う事で期待されている分野です。この辺りの話は「何故、機械学習の未来はちっぽけなのか?」に詳しいです。
本日、EfficientNetsから派生した画像分類モデルのファミリーであるEfficientNet-EdgeTPUのリリースを発表します。EfficientNet-EdgeTPUは、GoogleのEdge TPUで最適に動作するようにカスタマイズされています。これは、Coral Dev BoardとCoralのUSBアクセラレータを通じて開発者が利用できる電力効率の良いハードウェアアクセラレータです。
訳注:CoralとはGoogleが提供しているエッジでAIを活用するために最適化したハードウェア群の事です。カメラ($24.99)やマザーボード($149.99)、センサー($24.95)などが販売されています。
このようなモデルのカスタマイズにより、Edge TPUはリアルタイムの画像分類パフォーマンスを提供すると同時に、通常はデータセンターで非常に大規模で計算量の多いモデルを実行する場合にのみ達成できるような精度をEdgeで達成できます。
AutoMLを使用してハードウェアアクセラレータでの実行に最適化したEfficientNetsを開発
EfficientNetsは、モデルのサイズと計算の複雑さを大幅に削減しながら、画像分類タスクで最先端の精度を達成できる事を示しました。Edge TPUのアクセラレータアーキテクチャを有効活用するようにEfficientNetsを再設計するため、AutoML MNASフレームワークを呼び出し、Edge TPUで効率的に実行される構成を探索するように元のEfficientNetのニューラルネットワークアーキテクチャの検索スペースを拡張しました。(以下で説明します)
また、モデルのレイテンシ(待ち時間)の推定値を提供する「レイテンシプレディクタ」モジュールを構築および統合しました。レイテンシプレディクタは、正確なサイクルでモデルを実行する事でアーキテクチャをシミュレーションし、待ち時間を予測します。
AutoML MNASコントローラーは、強化学習アルゴリズムを実装して、報酬を最大化しようとしながらこの空間を検索します。これは、予測されたレイテンシとモデル精度をジョイントした関数です。
過去の経験から、モデルのサイズがオンチップメモリに収まる場合、Edge TPUの電力効率とパフォーマンスが最大化される傾向があることがわかっています。したがって、報酬関数も変更して、この制約を満たすモデルに対してより高い報酬を生成するようにしています。
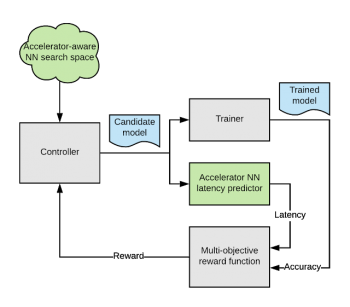
カスタマイズされたEfficientNet-EdgeTPUモデルを設計するためのAutoMLフローの全体図
3.EfficientNet-EdgeTPU:アクセラレータでの実行に最適化したニューラルネット(1/2)関連リンク
1)ai.googleblog.com
EfficientNet: Improving Accuracy and Efficiency through AutoML and Model Scaling
2)github.com
EfficientNet-EdgeTPU
3)www.tensorflow.org
Post-training quantization
4)coral.withgoogle.com
Learn how to build AI products with Coral devices
5)developers.googleblog.com
Coral summer updates: Post-training quant support, TF Lite delegate, and new models!

コメント