
1.機械学習モデルの分類外データの検出を改良(1/3)まとめ
・機械学習は学習時に想定されてなかった分類外データを入力に与えられると確信を持って間違う時がある
・これを避けるため「そのデータが分類外(out of distribution)データか否か?」を検出する手法がある
・しかし既存の分類外データ検出手法はしばしば誤っている事が今回の研究の結果わかった
2.分類外データ(OOD:out of distribution)とは?
以下、ai.googleblog.comより「Improving Out-of-Distribution Detection in Machine Learning Models」の意訳です。元記事の投稿は2019年12月17日、Jie RenさんとBalaji Lakshminarayananさんによる投稿です。Google AI Residency Programの第三期のハイライトで紹介されていた研究ですね。
機械学習が確信をもって物凄い見当違いな事を言い出す事例はよく知られていますが、その原因の一つは、学習時に想定されてなかったデータ(分類外データ:out of distribution)を入力に与えられた時であっても、ムリヤリ学習データから学んだ事例に当てはめようとするからです。
例えば、便座以外に白い板状の物体を見た事がない機械学習モデルに単なる白い板を見せると「99%の確率でこれは白い便座です」とか言い出したりします。
これを避けるために、「その入力データは学習時に想定していたデータの範囲に収まっているのか?」をチェックしようというアイディアが出てきます。これが今回のお話の主題である「そのデータが分類外(out of distribution)データか否か?」です。
「分類外データか否か?」は「もっともらしさ(尤もらしさ)」で判断する事になりますが、英語ではlikelihood、統計の分野では「尤度(ゆうど)」と言うあまり聞きなれない単語に訳される事が多いです。
今回のお話の最終的な結論は「likelihood」より「likelihood ratio」が有効であるとの結論になるのですが、「もっともらしさ」と「もっともらしさ比」で表記すると読みにくくなるので「尤度」と「尤度比」の表現に統一しておきます。見慣れない単語ですが「どのくらい分類外データっぽいですか?」と言うだけの話です。
また、分類外データと関連が深い共変量シフトについて調べたお話はこちら。
機械学習システムを現実世界の業務へ展開させるには、システムが「異常なデータ」や「トレーニングで使用したデータとは著しく異なっているデータ」を検出できる必要があります。これは、このような分類外(OOD:out-of-distribution)の入力データを、自分が学習した分類クラスのいずれか分類してしまい、しかもその誤った分類結果を信頼度の高い分類として出力してしまう可能性のあるディープニューラルネットワークで実装された分類器にとって重要です。また、これらの予測が実世界で何らかの決定を下す際に参考にされるような情報である場合、特に重要です。
例えば、機械学習モデルを現実世界のアプリケーションとして使用する挑戦の1つは、ゲノム配列に基づく細菌の識別です。細菌の検出は、敗血症などの感染症の診断と治療、および食品を媒介して伝染する病原体の特定に不可欠です。
新たな細菌は長年にわたって発見され続けており、既存のデータでトレーニングされたニューラルネットワークによる分類器は、交差検証によって測定すると高い精度を達成します。
しかし、現実世界のデータは常に進化しており、トレーニング時には発見されていなかった細菌(OOD入力)の遺伝子情報が必然的に含まれるため、モデルを現実世界で使用する事は困難です。
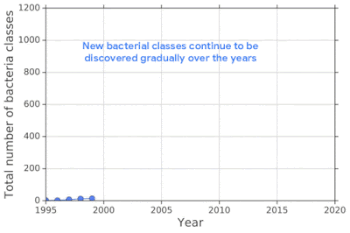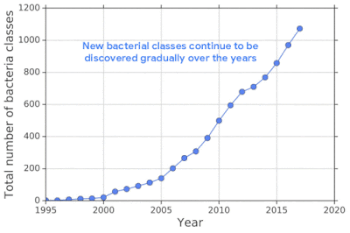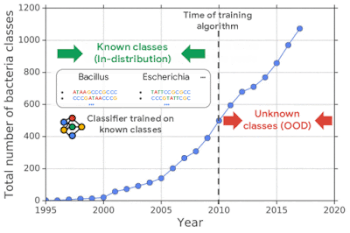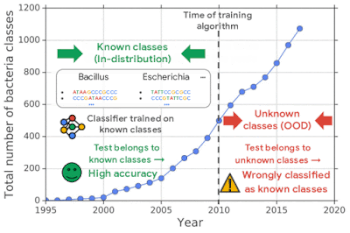
新しい細菌は、長年にわたって常に発見され続けています。既知の細菌でトレーニングされた分類器は、既知の細菌に属する細菌であれば高い精度で分類しますが、未知の細菌(OOD入力)を誤って既存の細菌として分類してしまいます。
NeurIPS 2019で発表した「Likelihood Ratios for Out-of-Distribution Detection」では、上記の現実世界の課題に触発されて、ゲノム配列を用いたOOD検出用のベンチマークデータセットを提案し、リリースしました。
私達は生成モデルを使用してゲノム配列でOODを検出する既存手法をテストし、それらが算出する尤度値(つまり、入力データが学習データが想定する範囲内に収まっている確率)がしばしば誤っていることを発見しました。
「背景画像の統計量(Background Statistics)」の効果によりこの現象を説明し、OOD検出の精度を大幅に向上させる尤度比(likelihood-ratio)ベースのソリューションを提案します。
3.機械学習モデルの分類外データの検出を改良(1/3)関連リンク
1)ai.googleblog.com
Improving Out-of-Distribution Detection in Machine Learning Models
2)arxiv.org
Likelihood Ratios for Out-of-Distribution Detection
3)github.com
google-research/genomics_ood/

コメント