
1.SpecAugment:音声認識のために学習データを水増しする(1/2)まとめ
・SpecAugmentは学習用の音声データを水増しする手法で従来手法より効率的な水増しが可能
・音声データのままではなく音声データを画像データに変換してから水増しをする所が特徴
・再計算の手間が省け、追加の音声データも不要になりモデルのパフォーマンスを大きく向上させる
2.SpecAugmentとは?
以下、ai.googleblog.comより「SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition」の意訳です。元記事は2019年4月22日、Daniel S. Park,さんとWilliam Chanさんによる投稿です。学習用の画像データを水増しする手法はAutoAugmentが有名ですが、音声の学習用データを水増しするのがSpecAugmentです。ただ音声データをそのまま水増しするのではなく、波形の画像イメージに変換してから水増しするので再計算の手間も省けるのがウリのようです。ただ、音声データをそのまま扱うのではなく、画像として扱うアイディアはSpecAugmentが初出ではなく、少なくともクジラの唄声認識の時に読んで感心した記憶があります。
自動音声認識(ASR:Automatic Speech Recognition)、入力された音声をテキストに転記するプロセスは、ディープニューラルネットワークの現在進行中の発展から大いに恩恵を受けています。
その結果、ASRは、Googleアシスタント、Googleホーム、そしてユーチューブのような多くの現代的な装置や製品に採用されるようになりました。それにもかかわらず、ディープラーニングベースのASRシステムを開発する上で、まだ多くの重要な課題が残っています。
そのような課題の1つは、多くのパラメーターを持つASRモデルは、トレーニングデータに過学習してしまう傾向があり、トレーニングセットが十分な広がりを持たない場合、学習時に現れなかった初見のデータの取り扱いに苦労することです。
十分な量のトレーニングデータがない場合、データ水増し手法を使って既存データの有効サイズを増やすことが可能であり、これは画像分類の分野におけるディープネットワークの性能を著しく向上させるのに貢献してきました。音声認識の場合、学習用データの水増しは伝統的に、トレーニングに使用される音声波形を何らかの方法で(例えば、再生速度を加速または減速することによって)変形すること、または背景雑音を追加する事を含みます。
単一の入力の複数の水増しバージョンがトレーニングの過程でネットワークに供給されるので、これはデータセットを効果的に大きくする効果があり、また関連する特徴を学習することをネットワークに強要することによってネットワークを強固にします。しかしながら、音声入力を水増しする既存の従来の方法は、追加の計算コストが必要になり、時には追加のデータも必要とします。
私達の直近の論文「SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition」では、音声データの問題ではなく視覚的な問題として扱い、音声データを水増しするための新しいアプローチを紹介します。伝統的に行われているように入力音声の波形を水増しする代わりに、SpecAugmentは増強ポリシーを音声スペクトログラム(すなわち、波形の画像表現)に直接適用します。
この方法は単純で、計算コストが安く、追加のデータを必要としません。また、ASRネットワークのパフォーマンスを向上させることで驚くほど効果的であり、ASRタスクの測定基準であるLibriSpeech 960hおよびSwitchboard 300hの最先端のスコアを実現します。
SpecAugment
従来のASRでは、音声波形は、通常、ネットワークのトレーニングデータとして入力される前に、スペクトログラムなどの視覚的表現として符号化されます。トレーニングデータの水増しは、通常、それがスペクトログラムに変換される前に波形オーディオに適用されるので、そのため、毎回反復の後に新しくスペクトログラムを生成しなければなりません。しかし、SpecAugmentではデータ水増しはネットワークの入力特徴に直接適用されるため、トレーニング速度に大きな影響を与えることなくトレーニング中にオンラインで実行できます。
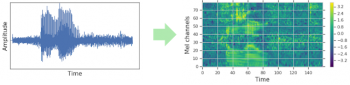
波形は通常、ネットワークに入力される前に視覚的表現(この場合はlog melスペクトログラム、Mel-frequency cepstrumの手順1から3)に変換されます。
SpecAugmentは、スペクトログラムを時間方向にワープし、連続した周波数チャネルのブロックをマスキングし、発話ブロックを時間的にマスキングすることによってスペクトログラムを修正します。これらの水増しは、ネットワークが時間方向の変形、周波数情報の部分的な損失、および入力の音声の小さな部分的欠落に対して耐性を持つ事を助けるために使用されています。
このようなデータ水増しの具体例を以下に示します。
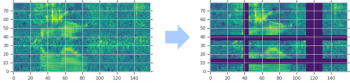
対数メルスペクトログラムは、時間方向にワープし、(複数の)連続する時間ステップのブロック(垂直マスク)およびメル周波数チャネル(水平マスク)をマスキングすることによって増強されます。スペクトログラムのマスクされた部分は、強調するために紫色で表示されています。
3.SpecAugment:音声認識のために学習データを水増しする(1/2)関連リンク
1)ai.googleblog.com
SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition
2)arxiv.org
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
3)en.wikipedia.org
Mel-frequency cepstrum
