
1.MeRL:強化学習でまばらで仕様が曖昧な報酬に対応(1/3)まとめ
・強化学習はアクションに対するフィードバック(報酬)が重要
・報酬が疎であったり報酬に繋がる行動が不明では学習が困難
・特に仕様が不明確な報酬は予想外の行動に繋がる可能性があり危険
2.疎で曖昧な報酬の問題とは?
以下、ai.googleblog.comより「Learning to Generalize from Sparse and Underspecified Rewards」の意訳です。元記事は2019年2月22日、Rishabh AgarwalとMohammad Norouziさんによる投稿です。
強化学習(RL)はゴールが定まっている行動を最適化する統一された柔軟なフレームワークです。人工知能にビデオゲームでハイスコアを記録させたり、何かを継続的にコントロールさせる作業やロボット学習など、従来は困難だった作業で著しい成功を可能にしました。これらのアプリケーション領域での強化学習アルゴリズムの成功は、高品質で高密度の報酬フィードバックループを利用できるかどうかにかかっています。
まばらでかつ仕様が曖昧な不十分な報酬を伴う環境に強化学習アルゴリズムの適用可能性を広げることは現在も研究されている挑戦的な課題です。これは、強化学習エージェントが限られたフィードバックから一般化する(すなわち正しい行動を学ぶ)事を要求します。
訳注:例えば、「バスケットボールをゴールに入れる作業」などでしたら、人工知能がボールを投げる度に「ボールが輪に触れたら0.5点、ボールが網に触れたら0.1点、ボールが輪の中に入ったら10点」等々のアクションに対してフィードバックが毎回発生し明確です。しかし、「迷路を探索して目標物を見つける作業」等では目的のものが見つかるまでフィードバックが得られず、しかも「最終的に目標物にたどり着くまでに最も貢献したアクションが何だったのか?(貢献度分配問題:Credit assignment problem)」が良くわからないので強化学習が難しいという事です。余談ですが、人間の脳も「報酬がめったに得られない」「どの行動が報酬に紐づくのか明確にされない」環境ではやる気を失うでしょうから、強化学習は本当に人間の脳に似てますね。
このような問題設定で強化学習アルゴリズムのパフォーマンスを調査する自然な方法は、言語理解タスクによるものです。強化学習エージェントには自然言語が入力として与えられ、入力で指定された目標を達成するために複雑な応答を生成する必要がありますが、成功 or 失敗のフィードバックのみを受け取ります。
例えば、一連の自然言語コマンド(右、上、上、右)をたどることによって迷路の中で目標位置に到達することを任務とする「盲目の」エージェントを考えてみましょう。入力テキストが与えられると、エージェント(緑色の円)はコマンドを解釈し、その解釈に基づいてアクションを実行してアクションシーケンス(a)を生成する必要があります。
エージェントは、目標に到達した場合は1、それ以外の場合は0の報酬を受け取ります。 エージェントは視覚的な情報にアクセスできないため、エージェントがこのタスクを解決して新しい指示に一般化する唯一の方法は、指示を正しく解釈することです。
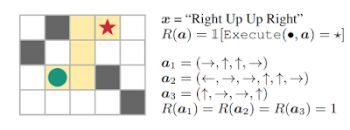
上の指示追従タスクでは、行動a1, a2, a3は目標に到達しますが、シーケンスa2, a3は指示に従っていません。 これは、「仕様が曖昧な報酬(unspecified reward)」の問題を示しています。
これらのタスクでは、強化学習エージェントはスパース(疎)な報酬(少数の行動だけがゼロ以外の報酬につながる)および仕様が曖昧な報酬(意図的な成功と偶発的な成功の区別がない)から一般化したルールを学ぶ必要があります。 重要な事は、仕様が曖昧な報酬が設定されていると、強化学習エージェントは環境内で様々な想定外の行動を行って報酬を受け取ろうとするかもしれません。これは報酬のハッキングにつながり、現実世界のシステムに配備されたときに意図しない有害な行動を引き起こす可能性があります。
余談:報酬が不明確だとズルや不正や想定外の行動に繋がる危険性があるというところもとても人間に似ています。
論文「Learning to Generalize from Sparse and Underspecified Rewards」では、補助的な報酬関数を最適化することによってより洗練されたフィードバックをエージェントに提供するMeta Reward Learning(MeRL)を開発することによって、仕様が曖昧な報酬の問題に対処します。
(MeRL:強化学習でまばらで仕様が曖昧な報酬に対応(2/3)に続きます)
3.MeRL:強化学習でまばらで仕様が曖昧な報酬に対応(1/3)関連リンク
1)ai.googleblog.com
Learning to Generalize from Sparse and Underspecified Rewards
2)arxiv.org
Learning to Generalize from Sparse and Underspecified Rewards

コメント